來自:碼農翻身(微訊號:coderising)
經過一個月的折騰,終於分家了。
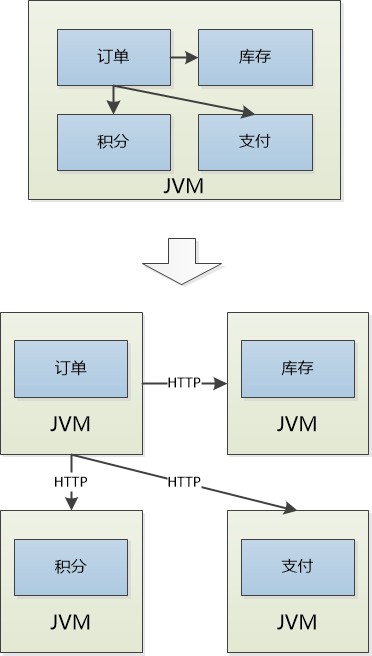
原來的訂單模組,庫存模組,積分模組,支付模組……搖身一變,成為了一個個獨立系統。
主人給這些獨立的系統起了一個時髦的名字: 微服務!
有些微服務是主人的心頭肉,他們“霸佔”了一臺或者多臺機器,像我這個積分模組,哦不,是積分系統,不受人待見,只能委屈一下,和另外幾個傢伙共享一臺機器了。
主人說我們現在是分散式的系統了,大家要齊心協力,共同完成原來的任務。
原來大夥都居住在一個JVM中,模組之間都是直接的函式呼叫,如今每個人對外提供的都是基於HTTP的API: 想要訪問別人,需要準備好JSON資料,然後透過HTTP傳送給過去,人家處理以後,再傳送一個JSON的響應。

真是麻煩,哪怕一次最簡單的溝通都要跨越網路了。
提起這網路我心裡就來氣, 想想原來大家都在一個行程中,那呼叫速度才叫爽。 現在可好,一是慢如蝸牛,二是不可靠,時不時就會出錯。
30毫秒以前,訂單這傢伙呼叫我的介面,要給一個叫做U0002的使用者增加200積分,我很樂意地執行了。
POST /xxx/BonusPoint/U0002
{“value:200”}
可是,當我想把積分的呼叫結果告訴訂單系統的時候,發現網路已經斷開,傳送失敗。 怎麼辦? 我想反正已經執行過了,Forget it !
可是訂單那小子對我這邊的情況一無所知,心裡琢磨著也許是我這邊出錯了, 死心眼的他又發起了同樣的呼叫。
對我而言,這個新的呼叫和之前的那個沒有一毛錢關係。(不要忘了,HTTP是沒有狀態的)我就老老實實地再執行一遍。
結果可想而知,使用者”U0002″的積分被無端地增加了兩次!
訂單小夥說:“這樣不行啊,你得記住我曾經發起過呼叫,這樣第二次就不用執行了!”
“開玩笑!HTTP是無狀態的, 我怎麼可能記錄你曾經的呼叫?”
“我們可以增加一點兒狀態, 每次呼叫,我給你發一個Transaction ID, 簡稱TxID,你處理完以後, 需要把這個TxID,UserID, 積分等資訊給儲存到資料庫中。”
POST /xxx/BonusPoint/U0002
{“txid”:”T0001″,”value”:”200″}
我說:“這有什麼用?”
“每次執行的時候,你都可以從資料庫中查一下啊,如果看到同樣的TxID已經存在了,那就說明之前執行過,就不用重覆執行了。如果不存在,才真正去執行。”
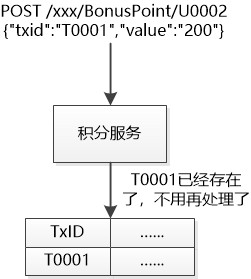
這倒是一個好主意,雖然我增加了一點工作量,需要一點額外的儲存空間(正好藉此機會要一個好點兒的伺服器!),但是卻有一個很好的特性:對於同一個TxID,無論呼叫多少次,那執行效果就如同執行了一次,肯定不會出錯。
後來我們才知道,人類把這個特性叫做冪等性。
一般來說,在後端資料不變的情況下,讀操作都是冪等的,不管讀取多少次,得到的結果都是一樣的。 但是寫操作就不同了,每次操作都會導致資料發生變化。要想讓一個操作可以執行多次,而沒有副作用,一定得想辦法記錄下這個操作執行過沒有。
我把新API告訴大家: 一定要給我傳遞過來一個TxID啊, 否則別怪我不處理!
這一天,我接收到了兩個HTTP的呼叫,第一次是這樣的:
POST /xxx/BonusPoint/U0002
{“txid”:”T0010″,“value”:”200″}
於是我很高興地執行了,並且把T0010這個txid給儲存了下來。
然後第二個呼叫又來了, 和第一個一模一樣:
POST /xxx/BonusPoint/U0002
{“txid”:”T0010″,“value”:”200″}
我用T0010一查,資料庫已經存在,我就知道,不用再處理了, 直接告訴對方:處理完成。
沒想到的是, 使用者很快就抱怨了:為什麼我增加了兩次積分(每次200),但實際上只增加了一次呢?
這肯定不是我的鍋, 我這邊沒有任何問題,一切按照設計執行。 我說:“剛才是誰發起的呼叫,檢查下呼叫的日誌!”
調查了呼叫方的日誌才發現,那兩次呼叫是兩個系統發出的!
碰巧,這兩個系統生成了相同的TxID : T0010 ,這就導致我認為是同一個呼叫的兩次嘗試, 實際上這是這是完全不同的兩次呼叫。
真相大白,TxID是罪魁禍首,可見這個TxID在整個分散式的系統中不能重覆,一定得是唯一的才行。
怎麼在一個分散式的系統中生成為一個唯一的ID呢?
訂單小夥說:“這很簡單,我們使用UUID就可以了,UUID中包含了網絡卡的MAC地址,時間戳,隨機數等資訊, 從時間和空間上保證了唯一性, 肯定不會重覆。 ”
UUID可以在本機輕鬆生成,不用再發起什麼遠端呼叫,效率極高。
844A6D2B-CF7B-47C9-9B2B-2AC5C1B1C56B
我說:“只是這長達128位數字和字母顯得很凌亂,沒法排序,也無法保證有序遞增(尤其是在資料庫中,有序的ID更容易確定位置)。”
大家紛紛點頭,UUID被否定。
MySQL提議:“你們竟然把我忘了! 我可以支援自增的(auto_increment)列啊, 天然的ID啊,同志們,絕對可以保證有序性。”

“啊? 用資料庫? 你萬一要是罷工了怎麼辦? 我們沒有ID可用,什麼事兒都乾不成了!” 大家一想到慢吞吞的老頭兒,讓大家去依賴它,把生殺大權交到它的手上,都有點不樂意。
Ngnix說:“你們怕他罷工,就多弄幾個MySQL唄,比如2個。
第一個的初始值是1,每次增加2,它產生的ID就是 1, 3, 5,7……
第二個的初始值是2,每次也增加2,它產生的ID就是 2,4,6,8,10……
再弄一個ID生成服務,如果一個MySQL罷工了,就訪問另外一個。”

“如果這個ID生成服務也完蛋了呢?” 有人問道。
“那可以多部署幾個ID生成服務啊, 這不就是你們微服務的優勢所在嗎?” Nginx反問。
Ngnix不虧是搞負載均衡的,這個方法可是相當地妙, 不但提高了可用性, ID還能保持趨勢遞增。
“可是,我每次需要一個TxID,都需要訪問一次資料庫啊,這該多慢啊!” 訂單小夥說道。
負責快取的Redis說道:“不要每次都訪問資料庫,學我,快取一些資料到記憶體中。”
“快取? 怎麼快取?”
Redis 說:“每次訪問資料庫的時候,可以獲取一批ID,比如10個, 然後儲存的記憶體中,這樣別人就可以直接使用,不用訪問資料庫了, 當然,資料庫需要記錄下當前的最大ID是多少。”
假設初始的最大ID是1 , 獲取10個ID, 即 1,2,3……10 ,儲存到記憶體中, 此時 最大ID變成10。
下次再獲取10個,即11,12,13……20 , 最大ID變成20。

“可是,你這個唯一的MySQL罷工了,系統還是要停擺啊!” 我說。
Ngnix說:“這種事情很簡單,多加一個MySQL,弄一個一主一從的結構, 嗯,如果資料沒有及時從Master複製到Slave的時候,Master就罷工了,此時Slave的中的Max ID就不是最新的,那接下來就可能出問題,也許可以搞一個雙主的結構……”
唉,搞一個分散式的唯一ID這麼複雜啊!
Ngnix在那裡嘟嘟囔囔,大家都沒有註意到,一個新的服務上線了,一上來就說:“嗨,大家好,我是snowflake……”
(註:篇幅太長了,就此打住,下次再寫snowflake……)
●編號814,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。