關註我們獲得更多內容
回顧本系列的第一部分,重點講述了作業系統排程器的各個方面,這些知識對於理解和分析 Go 排程器的語意是非常重要的。
在本文中,我將從語意層面解析 Go 排程器是如何工作的,並重點介紹其高階特性。
Go 排程器是一個非常複雜的系統,我們不會過分關註一些細節,而是側重於剖析它的設計模型和工作方式。
我們透過學習它的優點以便夠做出更好的工程決策。
開始
當 Go 程式啟動時,它會為主機上標識的每個虛擬核心提供一個邏輯處理器(P)。如果處理器每個物理核心可以提供多個硬體執行緒(超執行緒),那麼每個硬體執行緒都將作為虛擬核心呈現給 Go 程式。為了更好地理解這一點,下麵實驗都基於如下配置的 MacBook Pro 的系統。

可以看到它是一個 4 核 8 執行緒的處理器。這將告訴 Go 程式有 8 個虛擬核心可用於並行執行系統執行緒。
用下麵的程式來驗證一下:
package main
import (
"fmt"
"runtime"
)
func main() {
// NumCPU 傳回當前可用的邏輯處理核心的數量
fmt.Println(runtime.NumCPU())
}當我執行該程式時,NumCPU() 函式呼叫的結果將是 8 。意味著在我的機器上執行的任何 Go 程式都將被賦予 8 個 P。
每個 P 都被分配一個系統執行緒 M 。M 代表機器(machine),它仍然是由作業系統管理的,作業系統負責將執行緒放在一個核心上執行。這意味著當在我的機器上執行 Go 程式時,有 8 個執行緒可以執行我的工作,每個執行緒單獨連線到一個 P。
每個 Go 程式都有一個初始 G。G 代表 Go 協程(Goroutine),它是 Go 程式的執行路徑。Goroutine 本質上是一個 Coroutine,但因為是 Go 語言,所以把字母 “C” 換成了 “G”,我們得到了這個詞。你可以將 Goroutines 看作是應用程式級別的執行緒,它在許多方面與系統執行緒都相似。正如系統執行緒在物理核心上進行背景關係切換一樣,Goroutines 在 M 上進行背景關係切換。
最後一個重點是執行佇列。Go 排程器中有兩個不同的執行佇列:全域性執行佇列(GRQ)和本地執行佇列(LRQ)。每個 P 都有一個LRQ,用於管理分配給在P的背景關係中執行的 Goroutines,這些 Goroutine 輪流被和P系結的M進行背景關係切換。GRQ 適用於尚未分配給P的 Goroutines。其中有一個過程是將 Goroutines 從 GRQ 轉移到 LRQ,我們將在稍後討論。
下麵圖示展示了它們之間的關係:
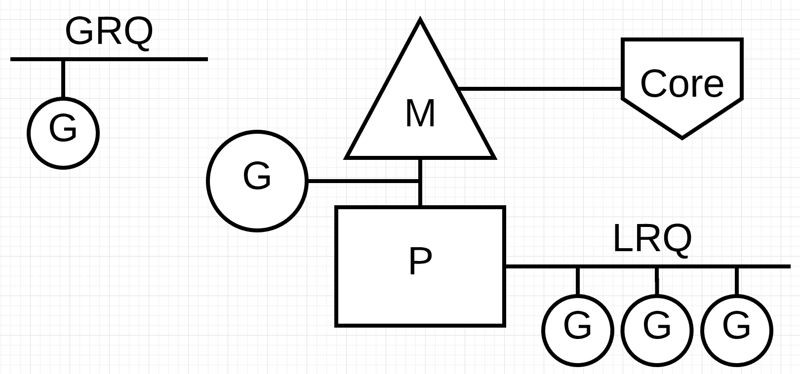
協作式排程器
正如我們在第一篇文章中所討論的,OS 排程器是一個搶佔式排程器。從本質上看,這意味著你無法預測排程程式在任何給定時間將執行的操作。由核心做決定,一切都是不確定的。在作業系統之上執行的應用程式無法透過排程控制核心內部發生的事情,除非它們利用像 atomic 指令 和 mutex 呼叫之類的同步原語。
Go 排程器是 Go 執行時的一部分,Go 執行時內建在應用程式中。這意味著 Go 排程器在核心之上的使用者空間中執行。Go 排程器的當前實現不是搶佔式排程器,而是協作式排程器。作為一個協作的排程器,意味著排程器需要明確定義使用者空間事件,這些事件發生在程式碼中的安全點,以做出排程決策。
Go 協作式排程器的優點在於它看起來和感覺上都是搶佔式的。你無法預測 Go 排程器將會執行的操作。這是因為這個協作排程器的決策不掌握在開發人員手中,而是在 Go 執行時。將 Go 排程器視為搶佔式排程器是非常重要的,並且由於排程程式是非確定性的,因此這並不是一件容易的事。
Goroutine 狀態
就像執行緒一樣,Goroutines 有相同的三個高階狀態。它們標識了 Go 排程器在任何給定的 Goroutine 中所起的作用。Goroutine 可以處於三種狀態之一:Waiting(等待狀態)、Runnable(可執行狀態)或Executing(執行中狀態)。
Waiting:這意味著 Goroutine 已停止並等待一些事情以繼續。這可能是因為等待作業系統(系統呼叫)或同步呼叫(原子和互斥操作)等原因。這些型別的延遲是效能下降的根本原因。
Runnable :這意味著 Goroutine 需要M上的時間片,來執行它的指令。如果同一時間有很多 Goroutines 在競爭時間片,它們都必須等待更長時間才能得到時間片,而且每個 Goroutine 獲得的時間片都縮短了。這種型別的排程延遲也可能導致效能下降。
Executing :這意味著 Goroutine 已經被放置在M上並且正在執行它的指令。與應用程式相關的工作正在完成。這是每個人都想要的。
背景關係切換
Go 排程器需要有明確定義的使用者空間事件,這些事件發生在要切換背景關係的程式碼中的安全點上。這些事件和安全點在函式呼叫中表現出來。函式呼叫對於 Go 排程器的執行狀況是至關重要的。現在(使用 Go 1.11或更低版本),如果你執行任何未進行函式呼叫的緊湊迴圈,你會導致排程器和垃圾回收有延遲。讓函式呼叫在合理的時間範圍內發生是至關重要的。
註意:在 Go 1.12 版本中有一個提議被接受了,它可以使 Go 排程器使用非協作搶佔技術,以允許搶佔緊密迴圈。
在 Go 程式中有四類事件,它們允許排程器做出排程決策:
-
使用關鍵字
go -
垃圾回收
-
系統呼叫
-
同步和編配
使用關鍵字 go
關鍵字 go 是用來建立 Goroutines 的。一旦建立了新的 Goroutine,它就為排程器做出排程決策提供了機會。
垃圾回收
由於 GC 使用自己的 Goroutine 執行,所以這些 Goroutine 需要在 M 上執行的時間片。這會導致 GC 產生大量的排程混亂。但是,排程程式非常聰明地瞭解 Goroutine 正在做什麼,它將智慧地做出一些決策。
系統呼叫
如果 Goroutine 進行系統呼叫,那麼會導致這個 Goroutine 阻塞當前M,有時排程器能夠將 Goroutine 從M換出並將新的 Goroutine 換入。然而,有時需要新的M繼續執行在P中排隊的 Goroutines。這是如何工作的將在下一節中更詳細地解釋。
同步和編配
如果原子、互斥量或通道操作呼叫將導致 Goroutine 阻塞,排程器可以將之切換到一個新的 Goroutine 去執行。一旦 Goroutine 可以再次執行,它就可以重新排隊,並最終在M上切換回來。
非同步系統呼叫
當你的作業系統能夠非同步處理系統呼叫時,可以使用稱為網路輪詢器的東西來更有效地處理系統呼叫。這是透過在這些作業系統中使用 kqueue(MacOS),epoll(Linux)或 iocp(Windows)來實現的。
基於網路的系統呼叫可以由我們今天使用的許多作業系統非同步處理。這就是為什麼我管它叫網路輪詢器,因為它的主要用途是處理網路操作。透過使用網路輪詢器進行網路系統呼叫,排程器可以防止 Goroutine 在進行這些系統呼叫時阻塞M。這可以讓M執行P的 LRQ 中其他的 Goroutines,而不需要建立新的M。有助於減少作業系統上的排程負載。
下圖展示它的工作原理:G1正在M上執行,還有 3 個 Goroutine 在 LRQ 上等待執行。網路輪詢器空閑著,什麼都沒乾。
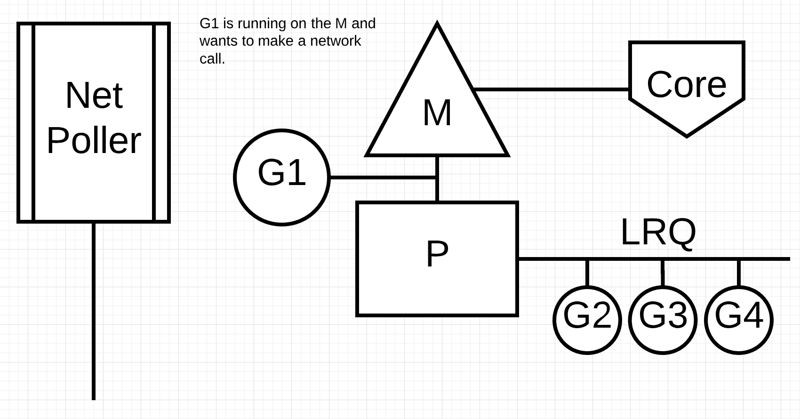
接下來,情況發生了變化:G1想要進行網路系統呼叫,因此它被移動到網路輪詢器並且處理非同步網路系統呼叫。然後,M可以從 LRQ 執行另外的 Goroutine。此時,G2就被背景關係切換到M上了。

最後:非同步網路系統呼叫由網路輪詢器完成,G1被移回到P的 LRQ 中。一旦G1可以在M上進行背景關係切換,它負責的 Go 相關程式碼就可以再次執行。這裡的最大優勢是,執行網路系統呼叫不需要額外的M。網路輪詢器使用系統執行緒,它時刻處理一個有效的事件迴圈。

同步系統呼叫
如果 Goroutine 要執行同步的系統呼叫,會發生什麼?在這種情況下,網路輪詢器無法使用,而進行系統呼叫的 Goroutine 將阻塞當前M。這是不幸的,但是沒有辦法防止這種情況發生。需要同步進行的系統呼叫的一個例子是基於檔案的系統呼叫。如果你正在使用 CGO,則可能還有其他情況,呼叫 C 函式也會阻塞M。
註意:Windows 作業系統確實能夠非同步進行基於檔案的系統呼叫。從技術上講,在 Windows 上執行時,可以使用網路輪詢器。
讓我們來看看同步系統呼叫(如檔案I/O)會導致M阻塞的情況:G1將進行同步系統呼叫以阻塞M1。
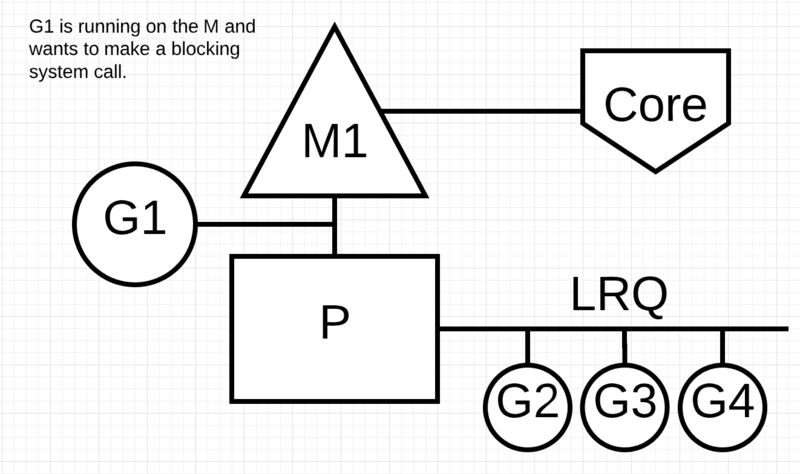
排程器介入後:識別出G1已導致M1阻塞,此時,排程器將M1與P分離,同時也將G1帶走。然後排程器引入新的M2來服務P。此時,可以從 LRQ 中選擇G2併在M2上進行背景關係切換。
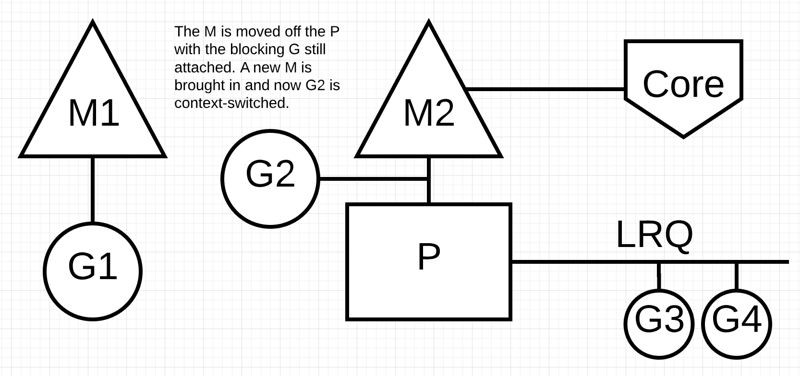
阻塞的系統呼叫完成後:G1可以移回 LRQ 並再次由P執行。如果這種情況需要再次發生,M1將被放在旁邊以備將來使用。
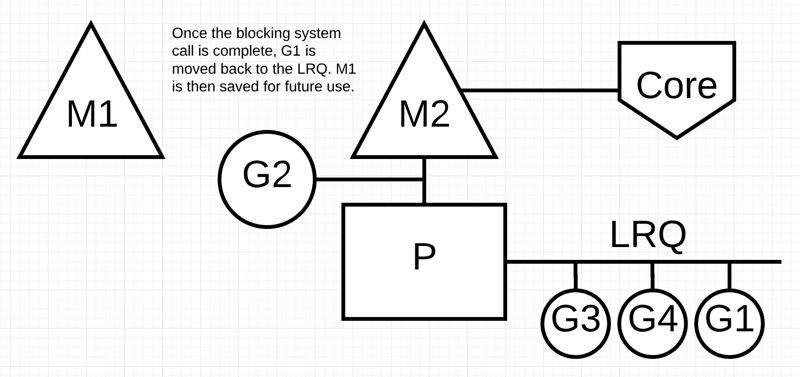
任務竊取(負載均衡思想)
排程器的另一個方面是它是一個任務竊取的排程器。這有助於在一些領域保持高效率的排程。首先,你最不希望的事情是M進入等待狀態,因為一旦發生這種情況,作業系統就會將M從核心切換出去。這意味著P無法完成任何工作,即使有 Goroutine 處於可執行狀態也不行,直到一個M被背景關係切換回核心。任務竊取還有助於平衡所有P的 Goroutines 數量,這樣工作就能更好地分配和更有效地完成。
看下麵的一個例子:這是一個多執行緒的 Go 程式,其中有兩個P,每個P都服務著四個 Goroutine,另在 GRQ 中還有一個單獨的 Goroutine。如果其中一個P的所有 Goroutines 很快就執行完了會發生什麼?

如你所見:P1的 Goroutines 都執行完了。但是還有 Goroutines 處於可執行狀態,在 GRQ 中有,在P2的 LRQ 中也有。
這時P1就需要竊取任務。

竊取的規則在這裡定義了:https://golang.org/src/runtim…
if gp == nil { // 1/61的機率檢查一下全域性可執行佇列,以確保公平。否則,兩個 goroutine 就可以透過不斷地相互替換來完全佔據本地執行佇列。
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock;)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock;)
}
}
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
gp, inheritTime = findrunnable()
}根據規則,P1將竊取P2中一半的 Goroutines,竊取完成後的樣子如下:
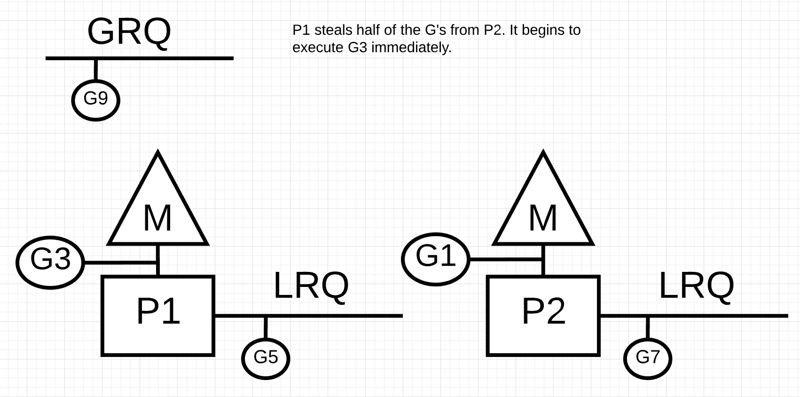
我們再來看一種情況,如果P2完成了對所有 Goroutine 的服務,而P1的 LRQ 也什麼都沒有,會發生什麼?

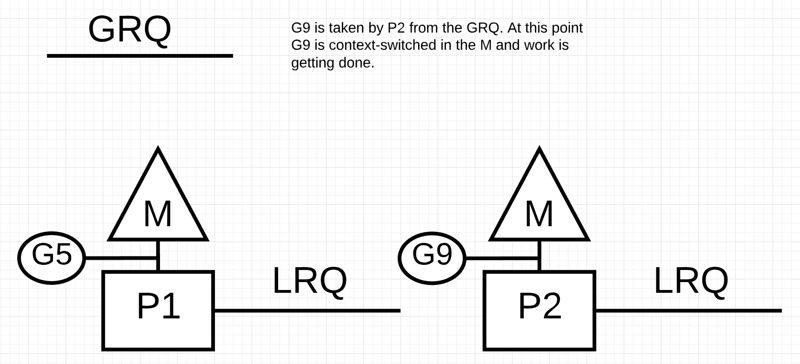
P2完成了所有任務,現在需要竊取一些。首先,它將檢視P1的 LRQ,但找不到任何 Goroutines。接下來,它將檢視 GRQ。
在那裡它會找到G9,P2從 GRQ 手中搶走了G9並開始執行。以上任務竊取的好處在於它使M不會閑著。在竊取任務時,M是自旋的。這種自旋還有其他的好處,可以參考 work-stealing 。
實體
有了相應的機制和語意,我將向你展示如何將所有這些結合在一起,以便 Go 排程程式能夠執行更多的工作。設想一個用 C 編寫的多執行緒應用程式,其中程式管理兩個作業系統執行緒,這兩個執行緒相互傳遞訊息。
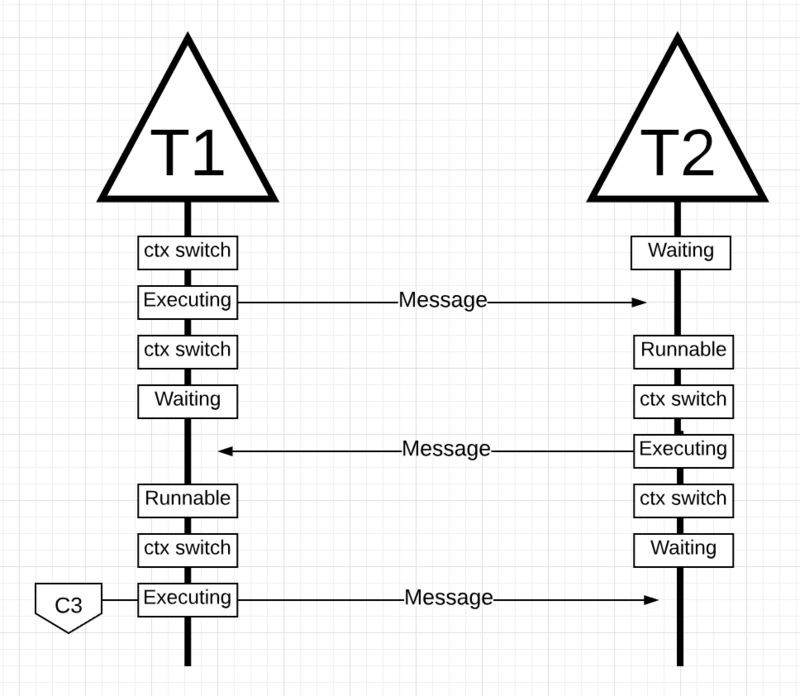
下麵有兩個執行緒,執行緒 T1 在核心 C1 上進行背景關係切換,並且正在執行中,這允許 T1 將其訊息傳送到 T2。
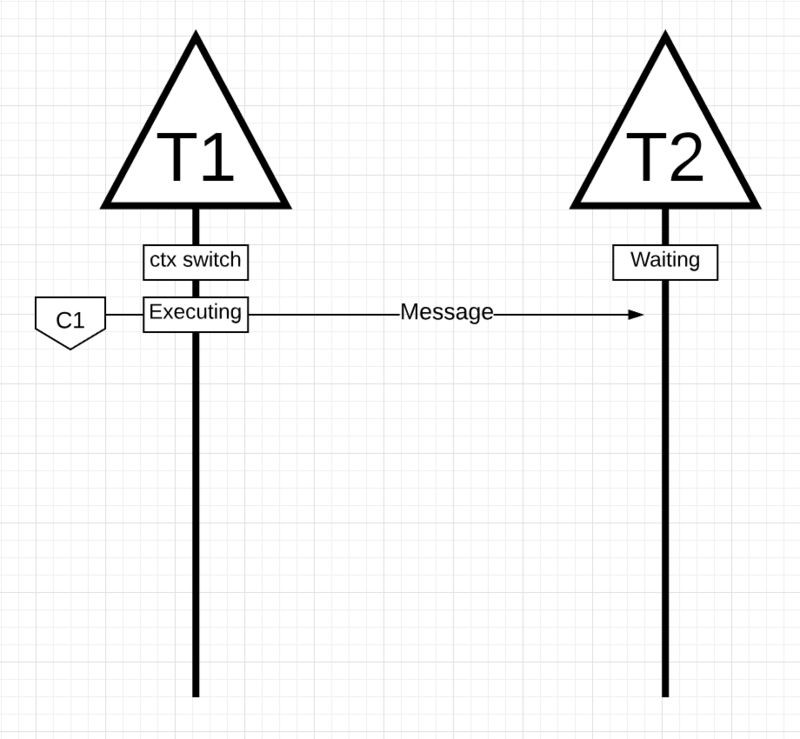
當 T1 傳送完訊息,它需要等待響應。這將導致 T1 從 C1 背景關係換出併進入等待狀態。
當 T2 收到有關該訊息的通知,它就會進入可執行狀態。
現在作業系統可以執行背景關係切換並讓 T2 在一個核心上執行,而這個核心恰好是 C2。接下來,T2 處理訊息並將新訊息發送回 T1。

然後,T2 的訊息被 T1 接收,執行緒背景關係切換再次發生。現在,T2 從執行中狀態切換到等待狀態,T1 從等待狀態切換到可執行狀態,再被執行變為執行中狀態,這允許它處理併發回新訊息。
所有這些背景關係切換和狀態更改都需要時間來執行,這限制了工作的完成速度。
由於每個背景關係切換可能會產生 50 納秒的延遲,並且理想情況下硬體每納秒執行 12 條指令,因此你會看到有差不多 600 條指令,在背景關係切換期間被停滯掉了。並且由於這些執行緒也在不同的核心之間跳躍,因 cache-line 未命中引起額外延遲的可能性也很高。
下麵我們還用這個例子,來看看 Goroutine 和 Go 排程器是怎麼工作的:
有兩個goroutine,它們彼此協調,來回傳遞訊息。G1在M1上進行背景關係切換,而M1恰好執行在C1上,這允許G1執行它的工作。即向G2傳送訊息。

G1傳送完訊息後,需要等待響應。M1就會把G1換出並使之進入等待狀態。一旦G2得到訊息,它就進入可執行狀態。現在 Go 排程器可以執行背景關係切換,讓G2在M1上執行,M1仍然在C1上執行。接下來,G2處理訊息並將新訊息發送回G1。
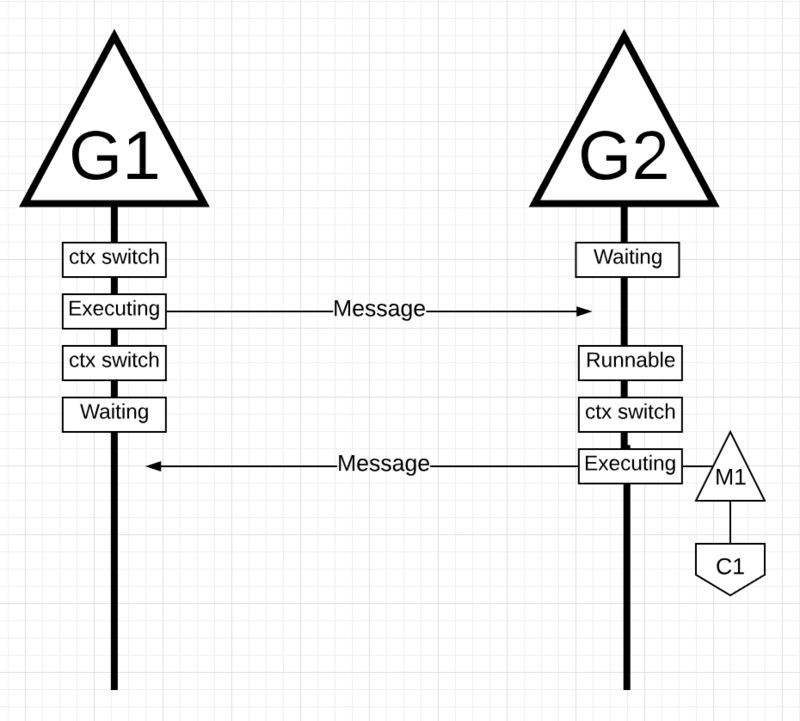
當G2傳送的訊息被G1接收時,背景關係切換再次發生。現在G2從執行中狀態切換到等待狀態,G1從等待狀態切換到可執行狀態,最後傳回到執行狀態,這允許它處理和傳送一個新的訊息。

錶面上看起來沒有什麼不同。無論使用執行緒還是 Goroutine,都會發生相同的背景關係切換和狀態變更。然而,使用執行緒和 Goroutine 之間有一個主要區別:
在使用 Goroutine 的情況下,會復用同一個系統執行緒和核心。這意味著,從作業系統的角度來看,作業系統執行緒永遠不會進入等待狀態。因此,在使用系統執行緒時的開銷在使用 Goroutine 時就不存在了。
基本上,Go 已經在作業系統級別將 IO-Bound 型別的工作轉換為 CPU-Bound 型別。由於所有的背景關係切換都是在應用程式級別進行的,所以在使用執行緒時,每個背景關係切換(平均)不至於遲滯 600 條指令。該排程程式還有助於提高 cache-line 效率和 NUMA。在 Go 中,隨著時間的推移,可以完成更多的工作,因為 Go 排程器嘗試使用更少的執行緒,在每個執行緒上做更多的工作,這有助於減少作業系統和硬體的負載。
結論
Go 排程器在設計中考慮到複雜的作業系統和硬體的工作方式,真是令人驚嘆。在作業系統級別將 IO-Bound 型別的工作轉換為 CPU-Bound 型別的能力是我們在利用更多 CPU 的過程中獲得巨大成功的地方。這就是為什麼不需要比虛擬核心更多的作業系統執行緒的原因。你可以合理地期望每個虛擬核心只有一個系統執行緒來完成所有工作(CPU和IO)。對於網路應用程式和其他不會阻塞作業系統執行緒的系統呼叫的應用程式來說,這樣做是可能的。
作為一個開發人員,你當然需要知道程式在執行中做了什麼。你不可能建立無限數量的 Goroutine ,並期待驚人的效能。越少越好,但是透過瞭解這些 Go 排程器的語意,您可以做出更好的工程決策。
在下一篇文章中,我將探討以保守的方式利用併發性以獲得更好的效能,同時平衡可能需要增加到程式碼中的複雜性。
