作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
在這個系列中,我們嘗試從能量的視角理解 GAN。我們會發現這個視角如此美妙和直觀,甚至讓人拍案叫絕。
本視角直接受啟發於 Bengio 團隊的新作 Maximum Entropy Generators for Energy-Based Models [1],這篇文章前幾天出現在 arXiv 上。

當然,能量模型與 GAN 的聯絡由來已久,並不是這篇文章的獨創,只不過這篇文章做得仔細和完善一些。另外本文還補充了自己的一些理解和思考上去,力求更為易懂和完整。
作為第一篇文章,我們先來給出一個直白的類比推導:GAN 實際上就是一場前僕後繼(前挖後跳?)的“挖坑”與“跳坑”之旅。

▲ “看那挖坑的人,有啥不一樣~”
總的來說,本文大致內容如下:
1. 給出了 GAN/WGAN 的清晰直觀的能量影象;
2. 討論了判別器(能量函式)的訓練情況和策略;
3. 指出了梯度懲罰一個非常漂亮而直觀的能量解釋;
4. 討論了 GAN 中最佳化器的選擇問題。
前“挖”後“跳”
在這部分中,我們以儘量通俗的比喻來解釋什麼是能量視角下的 GAN。
首先我們有一批樣本 x1, x2, … , xn,我們希望能找到一個生成模型,這個模型有能力造出一批新的樣本 ,我們希望這批新樣本跟原樣本很相似。怎麼造呢?很簡單,分兩步走。
,我們希望這批新樣本跟原樣本很相似。怎麼造呢?很簡單,分兩步走。
“挖坑”
第一步,挖坑:我們挖很多坑,這些坑的分佈可以用一個能量函式 U(x) 描述,然後我們要把真實樣本 x1, x2, … , xn 都放在坑底,然後把造出來的假樣本放到“坑腰”:

▲ GAN第一步:“挖坑”

▲ 然後我們把真假樣本放到適當的位置
“跳坑”
第二步,跳坑:把 U(x) 固定住,也就是不要再動坑了,然後把假樣本鬆開,顯然它們就慢慢從滾到坑底了,而坑底代表著真實樣本,所以都變得很像真樣本了:
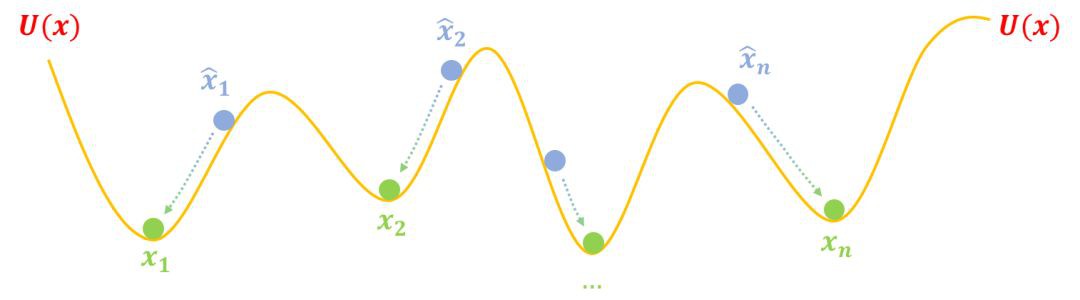
▲ GAN第二步:“跳坑”
這便是 GAN 的工作流程。
把GAN寫下來
註意,上述兩步不僅僅是簡單的比喻,而是 GAN 的完整描述了。根據上述兩個步驟,我們甚至可以直接把 GAN 訓練公式寫出來。
判別器
首先看“挖坑”,我們說了要將真樣本放到坑底,假樣本放到坑腰,以便後面假樣本可以滾到坑底,這意味著假樣本的“平均海拔”要高於真樣本的“平均海拔”,也就是說:

儘量小,這裡我們用 p(x) 表示真實樣本的分佈,q(x) 表示假樣本的分佈。假樣本透過 x=G(z) 生成,而 z∼q(z) 是標準正態分佈。
梯度懲罰
另外,我們還說真樣本要在坑底,用數學的話說,坑底就是一個極小值點,導數等於 0 才好,即要滿足 是最理想的,換成最佳化標的的話,那就是
是最理想的,換成最佳化標的的話,那就是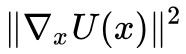 越小越好。兩者綜合起來,我們就得到 U 的最佳化標的:
越小越好。兩者綜合起來,我們就得到 U 的最佳化標的:

註:以往對於梯度懲罰,我們總會有兩個困惑:1)梯度懲罰究竟是以 0 為中心好還是以 1 為中心好;2)梯度懲罰要對真樣本、假樣本還是真假插值樣本進行?
現在,基於能量視角,我們可以得到“對真樣本進行以 0 為中心的梯度懲罰”比較好,因為這意味著(整體上)要把真樣本放在極小值點處。
至此,在能量視角下,我們對梯度懲罰有了一個非常直觀的回答。
生成器
然後看“跳坑”,也就是坑挖好了, U 固定了,我們讓假樣本滾到坑底,也就是讓 U(x) 下降,滾到最近的一個坑,所以:

可以看到,判別器實際上就是在“造勢”,而生成器就是讓勢能最低,這便是能量 GAN 的主要思想。
交替訓練
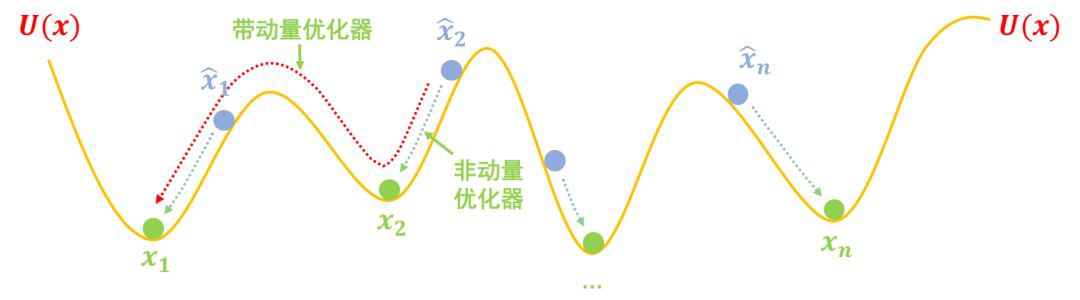
如果真實情況的坑都像上面的圖那麼簡單,那麼可能就只需要兩步就能訓練完一個生成模型了。
但是真實情況下的坑可能是很複雜的,比如下圖中假樣本![]() 慢慢下滑,並不一定能到達 x1 的坑,而是到達一個中間的坑,這個中間的坑並非代表真樣本,可能僅僅是“次真”的樣本,所以我們需要不斷地改進假樣本,也需要不斷地把坑修正過來(比如爭取能下一步把阻礙前進的峰“削掉”)。
慢慢下滑,並不一定能到達 x1 的坑,而是到達一個中間的坑,這個中間的坑並非代表真樣本,可能僅僅是“次真”的樣本,所以我們需要不斷地改進假樣本,也需要不斷地把坑修正過來(比如爭取能下一步把阻礙前進的峰“削掉”)。
這也就是說,我們需要反覆、交替地執行 (1)、(3) 兩步。

▲ 真實情況下坑的分佈可能更複雜
坑的學問
看,頭腦中想象著幾個坑,我們就可以把 GAN 的完整框架匯出來了,而且還是先進的 WGAN-GP 的升級版:以 0 為中心的梯度懲罰。GAN 不過是一場坑的學問。
對這個GAN的進一步討論,可以參考我之前寫的文章WGAN-div:默默無聞的WGAN填坑者或者論文 Which Training Methods for GANs do actually Converge? [2]。
進一步思考
上述圖景還能幫助我們回答很多問題。比如判別器能不能不要梯度懲罰?為什麼 GAN 的訓練、尤其是生成器的訓練多數都不用帶動量的最佳化器,或者就算用帶動量的最佳化器,也要把動量調小一點?還有 mode collapse(樣式坍縮)是怎麼發生呢?
Hinge Loss
梯度懲罰在理論上很漂亮,但是它確實太慢,所以從實踐角度來看,其實能不用梯度懲罰的話最好不用梯度懲罰。但是如果不用梯度懲罰,直接最小化式 (1),很容易數值不穩定。
這不難理解,因為沒有約束情況下,很容易對於真樣本有 U(x)→−∞ ,對於假樣本有 U(x)→+∞ ,也就是判別器最佳化得太猛了,差距拉得太大(無窮大)了。
那麼一個很自然的想法是,分別給真假樣本分別設定一個閾值,U(x) 的最佳化超過這個閾值就不要再優化了,比如:

這樣一來,對於 x∼p(x),如果 U(x)1,則 max(0,1−U(x))=0,這兩種情況下都不會在最佳化 U(x) 了,也就是說對於真樣本 U(x) 不用太小,對於假樣本 U(x) 不用太大,從而防止了 U(x) 過度優化了。
這個方案就是 SNGAN、SAGAN、BigGAN 都使用的 hinge loss 了。
當然,如果 U(x) 本身就是非負的(比如 EBGAN 中用自編碼器的 MSE 作為 U(x)),那麼可以稍微修改一下式 (4) :

其中 m>0。
最佳化器
至於最佳化器的選擇,其實從“跳坑”那張圖我們就可以看出答案來。
帶動量的最佳化器有利於我們更快地找到更好的極小值點,但是對於 GAN 來說,其實我們不需要跑到更好的極小值點,我們只需要跑到最近的極小值點,如果一旦跳出了最近的極小值點,跑到更低的極小值點,那麼可能就喪失了多樣性,甚至出現 mode collapse。
比如下圖中的![]() ,不帶動量的最佳化演演算法能讓
,不帶動量的最佳化演演算法能讓![]() 跑到 x2 處就停下來,如果帶動量的話,那麼可能越過 x2 甚至跑到 x1 去了。儘管 x1 也是真樣本,但是這樣一來
跑到 x2 處就停下來,如果帶動量的話,那麼可能越過 x2 甚至跑到 x1 去了。儘管 x1 也是真樣本,但是這樣一來![]() 同時向 x1 靠攏,也許沒有假樣本能生成 x2 了,從而喪失了多樣性。
同時向 x1 靠攏,也許沒有假樣本能生成 x2 了,從而喪失了多樣性。
▲ 帶動量與不帶動量的最佳化軌跡比較:不帶動量時,假樣本只需要落到最近一個坑,如果帶動量的話,可能越過最近的坑,到達更遠的坑去,導致假樣本聚集在某些真樣本附近,喪失多樣性。
所以,在 GAN 的最佳化器中,動量不能太大,太大反而有可能喪失生成樣本的多樣性,或者造成其他的不穩定情況。
Mode Collapse
什麼是 mode collapse?為什麼會發生 mode collapse?還是可以用這個圖景來輕鬆解釋。
前面我們畫的圖把假樣本![]() 畫得很合理,但是如果一旦初始化不好、最佳化不夠合理等原因,使得
畫得很合理,但是如果一旦初始化不好、最佳化不夠合理等原因,使得![]() 同時聚在個別坑附近,比如:
同時聚在個別坑附近,比如:
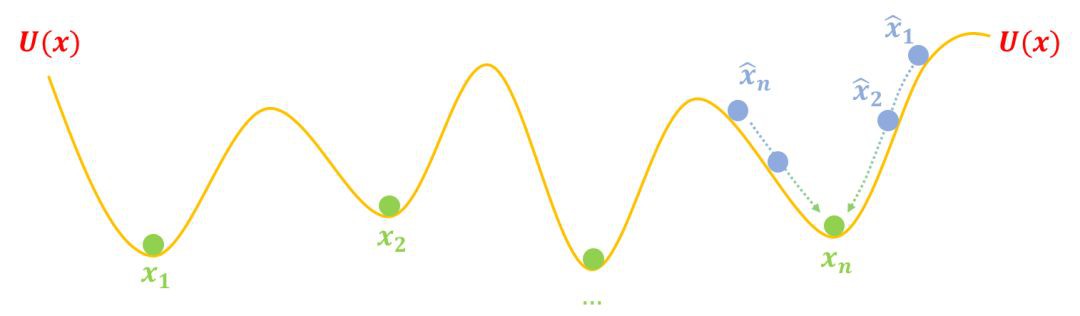
▲ Mode Collapse圖示
這時候按照上述過程最佳化,所有假樣本都都往 xn 奔了,所以模型只能生成單一(個別)樣式的樣本,這就是 mode collapse。
簡單來看,mode collapse 是因為假樣本們太集中,不夠“均勻”,所以我們可以往生成器那裡加一個項,讓假樣本有均勻的趨勢。這個項就是假樣本的熵 H(X)=H(G(Z)),我們希望假樣本的熵越大越好,這意味著越混亂、越均勻,所以生成器的標的可以改為:
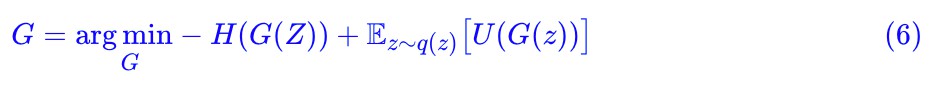
這樣理論上就能解決 mode collapse 的問題。至於 H(X) 怎麼算,我們後面會詳細談到。
能量視角之美
對於 GAN 來說,最通俗易懂的視角當屬“造假者-鑒別者”相互競爭的類比,這個視角直接導致了標準的 GAN。但是,這個通俗的類比無法進一步延伸到 WGAN 乃至梯度懲罰等正則項的理解。
相比之下,能量視角相當靈活,它甚至能讓我們直觀地理解 WGAN、梯度懲罰等內容,這些內容可以說是目前 GAN 領域最“先進”的部分成果了。雖然看起來能量視角比“造假者-鑒別者”形式上複雜一些,但其實它的物理意義也相當清晰,稍加思考,我們會感覺到它其實更為有趣、更具有啟發性,有種“越嚼越有味”的感覺。
參考文獻
[1] Rithesh Kumar, Anirudh Goyal, Aaron Courville, Yoshua Bengio, “Maximum Entropy Generators for Energy-Based Models”, arXiv preprint arXiv:1901.08508, 2019.
[2] Lars Mescheder, Andreas Geiger, Sebastian Nowozin, “Which Training Methods for GANs do actually Converge?”, ICML 2018.
