前言
我是來自滴滴平臺的陶文,今天很高興能夠在這裡給大家做一些 golang 相關的分享和交流,我的演講主要分為三個模組:
一、為什麼不手寫測試?
二、流量錄製和回放方案的取捨。
三、golang 實現的相關問題。
為何不手寫測試?
兩種手寫測試的風格
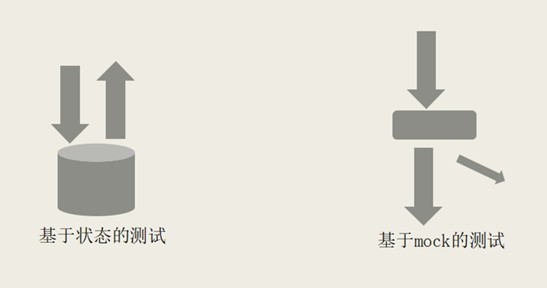
大家都知道一般技術測試是寫的而不是錄的,那麼我們為什麼不選擇手寫呢?這個問題我們也思考了很久。在十多年前我工作那會,大部分的測試都是手寫的,一般來說有兩種:一種是先把你的伺服器建立起來,之後往資料庫灌資料跑測試,看資料庫的狀態是不是和預想的一樣。其中最好寫的是基於狀態的測試。如果需要在測試裡面訪問郵件伺服器、發個郵件,這時候就可以把一個介面做個 mock,以確保在測試的過程中發送了郵件。雖然大部分的測試都可以由 mock 完成的,但是這種方式風險很大。我們曾經花了將近一年的時間用 mock 寫測試,後來發現這種方式下只要稍微改一點程式碼,基於 mock 的測試就掛了。所以一般來說,寫測試的話如果絕大多數驗證條件都是基於 mock 來測的話是有問題的。
跨組織邊界的整合測試
為什麼不用手寫,而是用最傳統的基於狀態去測試?其中有兩個原因,第一個是在微服務的結構下,我們的模組越分越細。需要測一個完整功能的時候,就會呼叫多個團隊的服務。比如說我們會把訂單的服務變成所謂的訂單系統,除了跑程式碼還要跑系統,稍微複雜一點的程式碼甚至還要跑策略,種種理由,你的程式碼少則幾個依賴,多則二三十個。這時候面臨的將會是一個跨團隊的整合問題,需要融合很多團隊的程式碼一起合作才能形成最簡單的對外 rpc 介面。另外,當這個問題和前面的問題耦合之後,當我們的程式碼本身就是有前後依賴關係的時候,比如你清楚我的程式碼依賴什麼前置狀態,但是未必清楚你所依賴的服務就像某某團隊的服務可能依賴某個詞典。但在載入到某個伺服器時你是不知道的,這時候測試就很難按照你真正的想法跑起來。

更加困難的是,一旦測試失敗了,最關鍵的問題是誰來定位,如果整合七個模組的程式碼,那麼找哪個模組的負責人去問?其中會有各種各樣的問題:語言不熟悉、框架看不懂、模組不清晰,這時候你就會想這到底是不是我的事情,我是不是應該負責這些事情。最後還是倒在了這句話:不是我的問題。
單模組流量錄製和回放
而流量錄製回放要解決的問題就是在我們沒有辦法改變團隊分工狀態的情況下,把我們負責的部分隔離出來,然後把它們周邊的模組互動,全部錄製下來之後再回放,這種處理方式的核心就在於它沒有辦法推卸責任,如果掛了就肯定是你的問題,而且它對環境問題的依賴非常小,如果出了問題一定不是由於環境問題導致的,大機率是程式碼有邏輯上的偏差,或者是實現新功能、做程式碼重構的情況,這樣一來,測試失敗的問題就可以變得更加容易定位。

流量錄製和回放方案的取捨
攔截層次的選擇
明確這個標的之後,我們的下一個任務是選擇一個實現方式。流量錄製和回放有很多實現的可能,從最上層來說,我們的業務程式碼裡面,每一個程式碼訪問,沒有函式在入口和出口都可以 load,這是最容易實現的方式,在網絡卡驅動上,可以實現一個虛擬網絡卡,像 vpn 一樣把所有經過網絡卡的流量錄下來,中間有很多層次可以攔截,比如可以在業務框架可以放在 rpc 框架裡,可以在語言標準庫,可以在語言標準庫所基於程式設計環境的語言上搞,也可以在進入核心之前搞,我們可以在各個層次上做攔截,攔截的東西有深有淺。在網絡卡驅動層面只能攔截網絡卡的流量,甚至不能區分出來到底是 tcp 還是還是別的類別,但是如果在業務程式碼裡面搞的,你可以把相關資訊錄下來並訪問某個記憶體裡面的配置服務,但是如果在網路層面的話就無法錄製。

根據這個選擇,我們要做一個標準,首先要解決這個問題:就是在我們生產環境的伺服器當中,流量很嘈雜,需要從生產環境上把這些流量錄下來,再分門別類,比如說一個伺服器每秒鐘至少有兩百個並行請求,如果全都串了的話,這將對我們接下來的回放有很高的要求,不能做到精確匹配的話,回放的時候就會弄錯流量,一百萬執行緒上面跑了一萬個,這種情況下怎麼區分請求,這就是我們要解決的問題。
分散式追蹤技術
大多數公司的解決方案是用分散式追蹤技術,透過修改程式碼來取得 trace ID,如果沒有生成一個 trace ID 的話,在訪問訂單系統各種各樣其他服務的時候把入口帶上,這樣就可以有一個完整的請求,再把各種請求關聯上。其實大部分公司所謂分散式追蹤技術的實現方式,要麼是去手工修改程式碼,要麼是取得當前執行緒關聯的背景關係,但是如果依賴這種技術,就需要我們對上面的業務有一定的掌控,因為滴滴目前來說是多語言多框架的技術站,我們很難在語言和框架層面做出統一,所以我們最後的選擇是利用執行緒 ID。我們要拿到當前的執行緒 ID,關聯入口和出口的流量,比較現實的方式是在使用者程式中間做攔截,這樣我們實際上是在業務的行程內部進行攔截,從而拿到執行緒 ID。

還有一個問題,就是多業務繪畫可能用同一個執行緒的情況,一個執行緒 ID上跑的東西未必是連續的業務請求,這樣就相當於說是一個分時租賃的樣式,可能在一個時間段內跑一個業務,在另外一個時間段跑另外一個業務,產生一種對映關係,每次發生切換會有標記,可以把一個完整的 rpc 請求鏈錄製下來。

golang實現的相關問題
整體架構
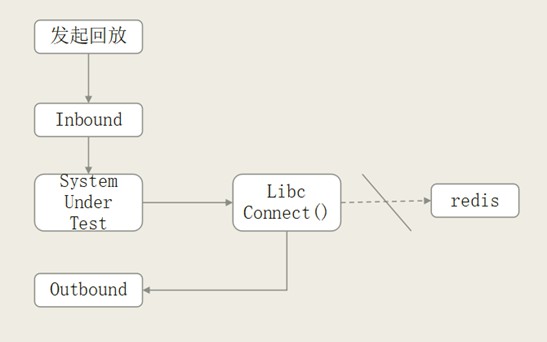
從實現角度講,整體架構的錄製本身是 SO,是動態執行庫,可以註入 SUT,可以理解為外部的行程,可能是 Java 這樣的一個虛擬機器,可能是一個 php 虛擬機器,也可能是 golang 本身,或者其他語言的執行環境。而在這個環境的外面兩側,我們去做攔截,所有的請求都透過 infound 進來做回放。所有的對外的請求是在 outfound,攔截所有外部服務。所以從 infound、outfound 角度來講,infound 是接受 replay,可以用編碼進行回放,而 outfound 是 TCP 伺服器,外面只要是 TCP 的服務都會被 mock 掉,再根據全域性的指令碼做回放,大概的回放的結構就是這樣。

劫持網路請求
錄製就是把流量錄下來,但是走的是同一個程式碼,比如同一個 SO 既做錄製也做回放,關鍵原理就是:首先我們劫持網路請求,發起 infound,php 監聽,然後它會去呼叫其他方法,會被我們重新定向到 outfound TCP的 mock 上,它本身就是一個迴圈,把它跟所有錄製流量做匹配,匹配到了再把之前線上錄製的內容放上去。
匹配請求的演演算法
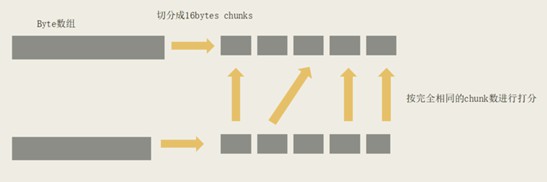
匹配演演算法要求要快,因為線上很多請求超時非常短,不可能幾十毫秒匹配出來,這樣就會超時。那麼我們做了一個非常難的 if 匹配的演演算法,就是把它切開,只要這裡面沒有出現大規模的重排序或是 key 的顛倒,大部分情況都是能夠匹配的,如果中間稍微有一兩個不見或者多出來的都是可以被近似掉的。
攔截的實現
攔截本身就是通用機制,常用的符號機制,當我們註入 SO 之後,如果實現了同樣的符號,就會在系結函式指正的時候,不會系結到真正的 libc,也就不會系結到我們 SO 上面。
所以其實真正關鍵的技術很簡單,就是你怎麼用 GO 寫一個連結庫,然後曝露符號,編輯的時候如果 mock 是這個的話,就可以寫出一個 SO,可改寫。
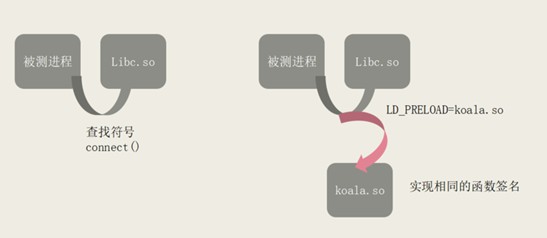

暴露符號
用 go 直接去寫的話會有一些限制,主要是函式簽名很難一一對應 C 的函式簽名,完整的模擬 C 的函式簽名有一定難度,所以更簡單的辦法是在程式碼裡面寫一個 cgo 實現符號的曝露,攔截之後轉交給 go,曝露符號也可以用 cgo 來寫,起到的類似作用,但掌控會更高一點,因為我們是攔截下來的,並不是完全的把它 mock 掉,所以還要回到原來的 libc 函式。再透過 som 可以直接達到原來的 libc 函式指正。

php-fpm 父子行程
當然,我們也遇到了幾個問題,一個是 php 和 fpm 父子行程問題,我們主要的線上伺服器是 php 寫的,當我們要註入的時候,發現它不好使,因為 php 副行程是透過轉交形式完成的,但是 fpm 行程會引起 golang 錯亂,出於某種原因 golang 歇菜了,不會有任何 go 的行為的觸發,雖然是被攔截下了,但是 go 整個虛擬機器就不再往前走了。

跳板loader
解決方法是透過跳板,我們在副行程註入的不是 go 寫的 so 檔案,而副行程寫的 so 檔案是用純 C 寫的,這樣副行程裡面的 so 就沒有 go wrong time,當副行程的註入發現 tcp,再去調由 go 寫的 so,再去做攔截,就可以避免問題。

支援mac
另外一個興趣點就是,由於這種開發方式比較方便,可以支援不用把所有的依賴環境搭建起來,於是我們的很多同事就用 mac 做開發,做出了一個能夠在 mac 本地起圖形化的 php storm 的介面,能夠直接把整個環境的流量做回放,mac 上有一個類似的東西叫做 dldyld,這種機制可以達到類似於 ld 的效果,可以使用同樣的用一套程式碼支援兩種平臺,我們在 go 上面和 mac 上面都可以實現同樣的攔截效果。

用 go 寫 so 的優勢
最後來講一下用 go 寫 so 的優勢,其實主要是我們的團隊對 C 很熟,可以寫很複雜的 C程式碼,基本的資料結構支援要更加全面,同時又比像 Java 這樣高階語言跟 C 的互動更有優勢,又比較簡單,同時我們可以在單執行緒的情況下能夠起多個 service,前面的例子如果要起多個 srd,線上上做有一種跑滿 cpu 的風險,而單執行緒在安全性上面更有優勢。
Q&A;
提問:這個到底好在哪裡?
陶文:traceID 主要是修改原始碼寫 load,我們線上是這樣的方式,需要修改程式碼傳遞 traceID,以及要打 load,修改程式碼本身以及打 load 本身是依賴於你去推廣,這很難保證程式碼不遺漏的。
我們兩套都有,我們並不需要(全量)流量做錄製,只需要取樣部分流量。沒有什麼道理,就是發現這個很好用,我們測試過32和8,沒有16好,所以就改成了16,這個純粹是啟髮式的演演算法。
提問:流量回放能百分之百回放嗎?
陶文:可以修改一下百分之百的定義,就可以百分百。
提問:是不是有可能只回放了90%,但是正好剩下的10%觸發了,就掛了。
陶文:有可能的,線上錄的時候 mac 序列化是 ABC,回放是 CBA,就匹配不上。
提問:回放必須再現上操作碼?最後說的優點是說線上的時候為了防止 CPO 佔滿,所以用了一個 go,但是線下回放,那就沒有什麼關係了。也不能算是優點,如果有人線上誤錯作,算是優點。
陶文:回放在本地,go 在這個例子裡面優點沒有那麼明顯,取決於這種團隊熟不熟。
提問:這個開源了嗎?
陶文:沒有開源,我們有一個更好的版本在內部使用。
提問:用回放有沒有什麼限制?需要依賴回放系統,如果一套系統支援多個自己本身的子服務的話,這樣流量回放是不是一直都需要?golang 否支援?
陶文:流量回放有一定的劣勢,就是說如果你把多個模組合在一起當成一個模組進行回放的話,按照這種方式回放,沒有那麼容易。
提問:這種回放會很花費時間嗎?
陶文:回放速度非常快,比跑單測還快。
提問:相當於你如果改了一個功能,相當於改寫了以前的功能的話,你這個回放是不是就一定跑的快?
陶文:當然是有可能的,所以主要的應用場景還是在重構下麵。
提問:大範圍能 cover,小範圍修 bug 不能 cover?
陶文:新增新的功能,會cover。
提問:剛才您提到的開發新業務,肯定要加新的邏輯,新的邏輯肯定流量也不知道,我們回放的時候,是怎麼把這些邏輯區分開?在真實應用中,因為可能加了一個新邏輯,以前沒有這個流量,這個主要是做回歸測試。我們怎麼把新的業務和老的回歸的老的業務區分開?
陶文:我們主要是用重構的,如果說服他們用這個新的是很有難度的,雖然我們可以構造所有的 mock 請求,如果願意做維護還是比較困難的。
提問:前面的圖裡面有一個錄製點,是線上的嗎?我沒有看明白,就是錄製點流量很多,透過你的 so 攔截,這個 so 是載入線上的伺服器上面是嗎?後面 mock 是一個實時的嗎?
陶文:是,錄製的時候,線上服務,它插入的點就在這裡,在 vc 中間。是真實訪問伺服器,在呼叫函式的時候,在中間攔截一下,會在一個儲存裡面,測試的時候再拉出來。
提問:外部資料都會記錄下去嗎,或者加密的。
陶文:伺服器 rpc 之間還沒有走內網請求,錄製本身來說,對取樣的流量是全量的,沒有取樣的是沒有錄製的。
提問:有對比兩個方案嗎?
陶文:我理解現在 tcp 更多是流量壓制的方式,我們這種方式,我們最後驗證是不是一樣的,中間也是不一樣的,最多是對正確性的校驗而不是流量壓制的校驗。
提問:你們這個流量錄製對線上伺服器的效能有多大,取樣率怎麼考慮的?
陶文:取樣率設的非常低,有些介面是萬分之一。取樣比較低也沒有什麼太大的影響。
提問:怎麼解決回放的資料依賴?
陶文:回放的時候它的依賴並不依賴真實的資料,因為它訪問資料庫本身,也是被 mock 掉的,也是走的錄製流量,所以相當於沒有依賴,唯一的依賴是記憶體中的配置,這個可能是我們還是透過傳統的改程式碼的方式,在程式碼裡面錄下來,訪問了哪些配置,我們在流量回放的時候把配置載入回去。
