
你的假期已餘額不足!
大資料(ID:hzdashuju)在長假期間
給你推送6篇入門級科普,包括:
另外還為既聰明又努力的孩子們
準備了一份充電書單
不知你這幾天看了幾篇?
今天是我們一起充電的第7天

導讀: 對資料科學這個詞給出一個一致認可的定義,就像品嘗紅酒然後在朋友之間分辨其口感一樣,每個人都不一樣。每個人都會有他自己的定義,沒有誰的更準確。
然而就其本質而言,資料科學是向資料提問的藝術:問聰明的問題,得到聰明的有用的回答。不幸的是,反過來也是成立的:笨的問題將得到糟糕的回答!因此,認真構造你的問題是從資料中提取出有價值洞見的關鍵。因為這個原因,公司現在都僱傭資料科學家來幫助構建這些問題。
作者:亞歷克斯·特列斯(Alex Tellez)、馬克斯·帕普拉(Max Pumperla)、邁克爾·馬洛赫拉瓦(Michal Malohlava)
本文摘編自《Spark機器學習:核心技術與實踐》,如需轉載請聯絡我們
據估計,到2018年,全世界的公司在大資料有關的專案上花費將達到1140億美元,相比2013年大約增長300%。

▲持續增長的大資料和資料科學Google Trend
01 資料科學家:21世紀最性感的職業
要給出一個典型資料科學家的古板肖像是很容易的:T恤衫,寬鬆的運動褲,邊框厚厚的眼鏡,在IntelliJ裡除錯大段的程式碼……大致如此。不過,除了外表之外,資料科學家的特徵還有哪些?下圖是我們最喜歡的海報之一,它描述了這個角色:

▲現代資料科學家
資料科學家,21世紀最性感的職業,需要各學科的複合技能,包括數學,統計學,電腦科學,溝通力以及商業技能。找到一位資料科學家是不容易的。找到一位伯樂也同樣困難。為此這裡提供了一個表格來描述什麼是真正的資料科學家。
|
數學和統計學 機器學習 統計建模 實驗設計 貝葉斯推斷 監督學習:決策樹,隨機森林,邏輯回歸 非監督學習:聚類,降維 最佳化:梯度下降及其變種 |
程式設計和資料庫 電腦科學基礎 指令碼語言,如Python 統計計算包,如R 資料庫:SQL和NoSQL 關係代數 並行資料庫和並行查詢處理 MapReduce概念 Hadoop和Hive/Pig 自定義reducers xaaS經驗,如AWS |
|
領域知識和軟技能 對於業務的激情 對於資料的好奇 無權威影響力 駭客精神 問題解決者 有策略,前瞻性和創造力,有創新性和合作精神 |
溝通力和視野 能與資深經理合作 講故事的能力 轉換資料視野為決策和行動 視覺化藝術設計 R包如ggplot或是lattice 任何視覺化工具的知識,如Flare,D3.js,Tableau |
數學、統計學和電腦科學的一般知識都列出了,但是一個常常在職業資料科學家中見到的困難是對業務問題的理解。這又回到向資料提問的問題上來,這一點怎麼強調也不為過:一個資料科學家只有理解了業務問題,理解了資料的侷限性,才能夠向資料問出更多聰明的問題;沒有這些根本的理解,即使是最聰明的演演算法也無法在一個脆弱的基礎上得出可靠的結論。
1. 資料科學家的一天
對你們中間的一些人來說,這個事實可能會讓你驚訝 – 資料科學家不只是喝著濃縮咖啡忙於閱讀學術論文、研究新工具和建模直到凌晨;事實上,這些只佔資料科學家相當少的一部分時間(濃縮咖啡倒是100%真的)。一天中的絕大部分時間,都花在各種會議裡,以更好地理解業務問題,分析資料的侷限性(打起精神,無數特徵工程(feature engineering)和特徵提取(feature extraction)的任務),以及如何能夠把結果最好地呈現給非資料科學家們,是個繁雜的過程,最好的資料科學家也需要能夠樂在其中;因為這樣才能更好地理解需求和衡量成功。事實上,要從頭到尾描述這個過程,我們完全能夠寫一本新書!
那麼,向資料提問到底涉及哪些方面呢?有時,只是把資料存到關係型資料庫裡,執行一些SQL查詢陳述句:“購買這個產品的幾百萬消費者同時購買哪些其他產品?找出最多的前三種。”有時問題會更複雜,如“分析一個電影評論是正面的還是負面的?”對這些複雜問題的回答是大資料專案對業務真正產生影響的地方,同時我們也看到新技術的快速湧現,讓這些問題的回答更加簡單,功能加更豐富。
一些試圖幫助回答資料問題的最流行的開源框架包括R、Python、Julia和Octave,所有這些框架在處理小規模(小於100GB)資料集時表現良好。在這裡我們對資料規模(大資料VS小資料)給出一個清晰的界定,在工作中一個總的原則是這樣的:
如果你能夠用Excel來開啟你的資料集,那麼你處理的是小規模資料。
2. 大資料處理
如果要處理的資料集太大放不進單個計算機的記憶體,從而必須分佈到一個叢集的多個節點上,該怎麼處理?比方說,難道不能僅僅透過修改擴充套件一下原來的R程式碼,來適應多個計算節點的情況?要是事情能這麼簡單就好了。把單機演演算法擴充套件到多臺機器的困難原因有很多。設想如下一個簡單的例子,一個檔案包含了一系列名字:
B
D
X
A
D
A
我們想算出檔案中每個名字出現的次數。如果這個檔案能夠裝進單機,你可以透過Unix命令組合sort和uniq來解決:

輸出如下:

然而,如果檔案很大需要分佈到多臺機器上,就有必要採用一種稍微不同的策略,比如把檔案進行拆分,每個分片能夠裝入記憶體,對每個分片分別進行計算,最後將結果進行彙總。因此,即使是簡單的任務,像這個統計名字出現次數的例子,在分散式環境中也會變得複雜。
3. 分散式環境下的機器學習演演算法
機器學習演演算法把簡單任務組合為複雜樣式,在分散式環境下變得更為複雜。以一個簡單的決策樹演演算法為例。這個演演算法建立一個二叉樹來擬合訓練資料和最小化預測錯誤。要構造這個二叉樹,必須決定樹有哪些分支,這樣每個資料點都能夠分派到一個分支上。我們用一個簡單的示例來闡述這個演演算法:
這是什麼顏色?

▲二維空間上的紅色和藍色資料點示例
考慮這張圖所描述的情況:一個二維平面上分佈著一些資料點,著色為紅色和藍色。決策樹的標的是學習和概括資料的特徵,幫助判斷新資料點的顏色。在我們這個例子裡,可以很容易地看出來這些資料點大致遵循一種國際象棋棋盤的樣式,但是演演算法必須靠自己學習出來。它從找到一個最佳的能把紅點和藍點劃分開的水平線或者豎直線開始。將這條線儲存在決策樹的根節點裡,然後遞迴地在分塊中執行這個步驟,直到分塊中只有一個資料點時演演算法結束。

▲最終的決策樹及其預測與原空間資料點的對映
4. 將資料拆分到多臺機器
現在我們假設資料點非常多,單機記憶體容納不下,因此我們必須把資料分片,每臺機器都只包含一部分資料點。這樣我們解決了記憶體問題,但這也意味著我們現在需要把計算分佈到一個叢集的機器上。這是和單機計算的第一個不同點。如果資料能夠裝進一個單機的記憶體,對資料做決策會比較容易,因為演演算法能夠同時訪問所有資料,但是在分散式演演算法的情況下,這一點就不再成立了,演演算法就訪問資料而言必須足夠“聰明”。既然我們的標的是構造一個決策樹來預測平面上新資料點的顏色,因此我們需要設法構造出一個和單機上一樣的樹。
最原始的解決方案是構造一個簡單樹,把資料點按照機器邊界分片。不過很顯然不好,因為資料點分佈完全沒有考慮到資料點的顏色。
另一種解法是在X軸和Y軸方向上嘗試所有的分片可能,找到把顏色區分開的最佳劃分,也就是說,能夠把資料點分為兩組,每組中一種顏色盡可能多而另一種顏色盡可能少。設想演演算法正在測試按照X = 1.6這條線來分割資料。這意味著演演算法需要詢問叢集中的每一臺機器,得到每臺機器按照這條線分片的結果,然後彙總決定這條線是不是合適。當它找到了一個最佳的分片方法,它也需要把這個決定通知集群裡所有的機器,這樣每臺機器才能夠知道自己本地每個資料點現在的分片情況。
和單機情況相比,這個分散式決策樹構造演演算法更複雜,而且需要一種分散式計算方式。如今,隨著叢集的普及和對大資料集分析需求的增長,這已經是一個基本需求了。
即便是這樣兩個簡單的例子也可以說明,對於大資料集,合適的分散式計算框架是必須的。具體包括:
-
分散式儲存,即,如果單個節點容納不下所有的資料,需要一種方式來把資料分佈到多臺機器上處理
-
一個計算正規化(paradigm),用於處理和轉換分散式資料,使用數學(和統計學)演演算法和工作流
-
支援持久化和重用定義好的工作流和模型
-
支援在生產環境中部署統計模型
簡言之,我們需要一個框架來支援常見的資料科學任務。有人會覺得這不是必需的,因為資料科學家更喜歡用一些已有的工具,比如R、Weka,或者Python scikit。但是,這些工具並不是為大規模分散式資料處理和平行計算設計的。即便R和Python有一些庫提供了分散式和平行計算的有限支援,這些庫都受到一個根本性的限制,那就是它們的基礎平臺,R和Python,根本不是為這種大規模資料處理和計算而設計的。
5. 從Hadoop MapReduce到Spark
隨著資料量的增長,單機工具已不再能夠滿足工業界的需求,這給新的資料處理方法和工具提供了機會,尤其是Hadoop MapReduce。MapReduce是基於Google一篇論文提出的想法,MapReduce: Simplified Data Processing on Large Clusters (https://research.google.com/archive/mapreduce.html)。另一方面,MapReduce是一個通用框架,沒有為建立機器學習工作流提供庫或者任何顯式支援。經典MapReudce實現的另一個侷限是在計算過程中有很多磁碟I/O操作,沒有充分利用大記憶體帶來的益處。
你已經看到了,雖然已經有了幾個機器學習工具和分散式平臺,但沒有哪個能充分滿足在分散式環境下進行大資料機器學習的需求。這為Apache Spark開啟了大門。

▲進屋來吧,Apache Spark!
Spark在2010年建立於UC Berkeley AMP(Algorithms, Machines, People,演演算法,機器,人)實驗室,在建立時就考慮了速度、易用性和高階分析功能。Spark和其他分散式框架如Hadoop的一個關鍵區別在於資料集可以快取在記憶體裡,這讓它很適合用作機器學習,因為機器學習天然需要迭代計算,而且資料科學家總是需要對同一塊資料進行多次訪問。
Spark能夠以多種方式執行,包括:
-
本地樣式:在一個單獨的主機上執行單個Java虛擬機器(JVM)
-
獨立Spark叢集:在多臺主機上執行多個JVM
-
透過資源管理器,如Yarn/Mesos:應用部署由資源管理器管理。資源管理器負責控制節點的分配、應用、分發和部署
6. 什麼是Databricks
如果你瞭解Spark專案,你很可能也聽說過一個叫作Databricks的公司,不過也許不知道Databricks和Spark具體是什麼關係。概要說來, Apache Spark專案的建立者們建立了Databricks公司,貢獻了超過75%的Spark程式碼。除了是推動Spark開發的巨大力量之外,Databricks也為開發人員,管理人員,培訓人員和資料分析師等提供Spark認證。不過Spark程式碼庫並不僅僅是由Databricks貢獻的,IBM、Cloudera和微軟也積極參與了Spark的開發。
順便說來,Databricks也在歐洲和美國組織Spark峰會,一個頂級的Spark會議,一個瞭解Spark最新開發進展和他人是如何在各自的生態裡使用Spark的好地方。
7. Spark包含的內容
好了,現在假設你已經下載了最新版本的Spark(具體哪個版本取決於你打算以哪種方式執行Spark)而且已經運行了經典的”Hello, World!”程式了……接下來呢?
Spark帶有5個庫,這些庫既能夠單獨使用,也能一起工作,取決於具體需要解決的問題。盡可能廣泛地接觸Spark平臺,這樣對每一個庫的功能(和侷限)有更好的理解。這5個庫是:
-
核心:Spark的核心基礎設施,提供了表示和儲存資料的原始資料型別,稱為RDD(Resilient Distributed Dataset,彈性分散式資料集),運算元據的任務(task)和作業(job)。
-
SQL:在RDD基礎上提供的使用者友好的API,引入了DataFrame和SQL來操作儲存的資料。
-
MLlib(Machine Learning Library,機器學習庫):這是Spark自身內建的機器學習演演算法庫,可以在Spark應用程式中直接使用。
-
GraphX:供圖和圖相關計算使用。在後續章節中我們將深入探討。
-
流(Streaming):支援來自多種資料源的實時資料流,如Kafka、Twitter、Flume、TCP套接字,等等。
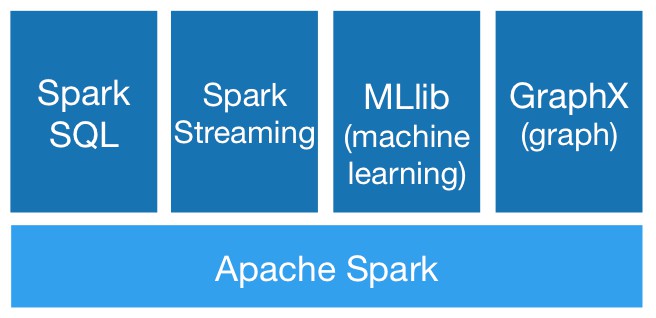
Spark平臺也支援第三方庫擴充套件。現在已經有很多的第三方庫,如支援讀取CSV或Avro格式的檔案,與Redshift整合的,以及封裝了H2O機器學習庫的Sparkling Water。
02 H2O.ai簡介
H2O是一個開源機器學習平臺,在Spark上執行得非常好;事實上它是第一批被Spark認證的第三方擴充套件包。

Sparkling Water(H2O + Spark)把H2O平臺整合進Spark,因此同時具有H2O的機器學習能力和Spark的全部功能,也就是說,使用者可以在Spark RDD/DataFrame上跑H2O演演算法,既可以出於實驗目的,也可以用於部署。之所以成為可能,是因為H2O和Spark共享JVM,因此在兩個平臺之間,資料可以無縫傳輸。H2O以H2O frame的格式儲存資料,是Spark RDD/DataFrame經過列壓縮後的資料集表示形式。
Sparkling Water的功能簡要包括:
-
在Spark工作流中使用H2O演演算法
-
在Spark和H2O資料結構之間做資料轉換
-
使用Spark RDD/DataFrame 作為H2O演演算法輸入
-
使用H2O frame作為MLlib演演算法輸入(在我們在以後做特徵工程時會很方便)
-
在Spark上透明執行Sparkling Water程式(比如,我們可以在Spark Streaming內執行Sparkling Water程式)
-
使用H2O使用者介面來瀏覽Spark資料
Sparkling Water的設計
Sparkling Water設計為一個普通的Spark程式執行。因此,它作為一個程式提交給Spark,在Spark執行器中啟動。隨後H2O啟動它的各種服務,包括一個鍵值儲存器(key-value store)和一個記憶體管理器,並把它們組織成一個雲,其拓撲和底層的Spark 叢集拓撲一致。
如前所述,Sparkling Water支援在不同型別的RDD/DataFrame和H2O frame之間來迴轉換。在把hex frame轉換為RDD時,資料並沒有做複製,而是在hex frame外做了一層包裝,提供一個類似RDD的API,支援此API的是裡面的hex frame。而把RDD/DataFrame轉換為H2O frame則需要做資料複製,因為需要把資料從Spark轉換進H2O自身的儲存。不過,儲存在H2O frame中的資料高度壓縮,不再需要保持在RDD中。
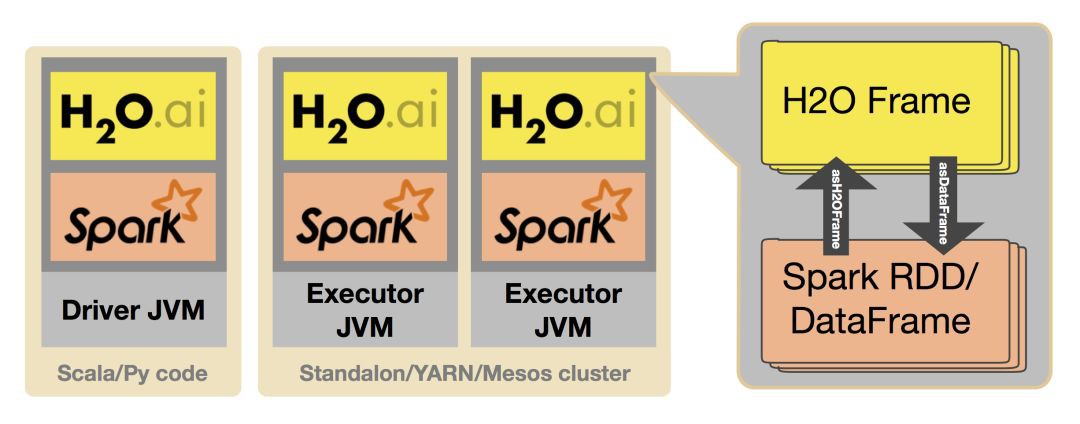
▲sparkling water和 Spark之間共享資料
03 H2O和Spark MLlib的區別
如前所述,MLlib是一個用Spark構建的庫,包含流行的機器學習演演算法。一點也不奇怪,H2O和MLlib有很多共同的演演算法,但是在實現和功能上有所區別。H2O提供了一個非常方便的功能,允許使用者視覺化資料和執行特徵工程任務,這一點我們在後續章節中會深入討論。其資料視覺化是基於一個web友好的圖形介面,可以在code shell和一個類似記事本的環境之間無縫切換。下圖是一個H2O記事本示例 – 稱為Flow – 你很快就會熟悉:

H2O提供的另一個非常好的功能是允許資料科學家使用網格搜尋很多演演算法自帶的超引數。網格搜尋是一個為了簡化模型配置,最佳化演演算法所有超引數的方式。想知道哪個超引數需要修改和如何修改通常是困難的,網格搜尋允許我們同時試驗很多超引數,測量其輸出,然後根據質量需求選擇最好的模型。H2O網格搜尋可以和模型交叉驗證及多種停止條件組合,產生一些高階策略,如從一個超空間許多的引數中選擇1000個隨機引數,找到一個最佳模型,可以在2分鐘內完成訓練並使AUC大於0.7。
04 資料整理
問題域的原始資料常常來自不同的源,有著不同且往往不相容的格式。Spark程式設計模型的美在於它擁有自定義資料操作來處理輸入資料,轉換為一個可供將來特徵工程和模型構建使用的普通格式的能力。這個過程通常稱為資料整理,也是很多資料科學專案成功的關鍵所在。
05 資料科學:一個迭代過程
大資料專案的處理流程通常是迭代的,即反覆測試新的想法、新的功能,調整各種超引數等,保持一種快速失敗(fast fail)的想法。這些專案的最終結果通常是一個模型,能夠回答提出的問題。註意我們並沒有說要精確回答。如今很多大資料科學家碰到一個陷阱,他們的模型不能泛化來適應新的資料,也就是說他們過度擬合了已有資料,導致模型在處理新資料時表現糟糕。精確性是極度任務相關的,通常取決於業務的需要,加上對模型輸出的成本收益敏感度分析。
關於作者:亞歷克斯·特列斯,一名終身的資料駭客/愛好者,對資料科學及其在商業問題上的應用充滿了激情。他在多個行業擁有豐富的經驗,包括銀行業、醫療保健、線上約會、人力資源和線上遊戲。
馬克斯·帕普拉,一名資料科學家和工程師,專註於深度學習及其應用。他目前在Skymind擔任深度學習工程師,並且是aetros.com的聯合創始人。Max是幾個Python軟體包的作者和維護者,包括elephas,一個使用Spark的分散式深度學習庫。他的開源足跡包括對許多流行的機器學習庫的貢獻,如keras、deeplearning4j和hyperopt。
邁克爾·馬洛赫拉瓦,Sparkling Water的建立者、極客和開發者,Java、Linux、程式語言愛好者,擁有10年以上的軟體開發經驗。他於2012年在布拉格的查爾斯大學獲得博士學位,併在普渡大學攻讀博士後。
本文摘編自《Spark機器學習:核心技術與實踐》,經出版方授權釋出。
延伸閱讀《Spark機器學習》
點選上圖瞭解及購買
轉載請聯絡微信:togo-maruko
推薦語:以實踐方式助你掌握Spark機器學習技術。

更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 乾貨 | 數學
猜你想看
Q: 你的職業夠性感嗎?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

 點選閱讀原文,瞭解更多
點選閱讀原文,瞭解更多
