陳哲
西安郵電大學在讀研一學生。在陳老師的帶領下開啟了自己的核心之旅。

本學期在陳老師的帶領下,第一次踏進內核的殿堂,第一堂課就是閱讀list.h。
首先交代下我閱讀的核心版本是linux-4.18.7。list.h是核心中的一個頭檔案,主要有兩大部分:以list_ 命名的雙鏈表相關的操作和以hlist_命名的雜湊表的相關操作。我這裡主要記錄的是hlist部分一些我覺得有趣的地方與大家分享。
雜湊表:
雜湊表簡單的說就是將關鍵字與其儲存位置建立一種函式關係。實現雜湊表有兩個關鍵的步驟:
一是構造雜湊函式。
二是解決衝突問題。
雜湊函式的構造因人而異,而解決衝突則是每個雜湊表需要面臨的問題。
核心為我們提供了用於實現鏈地址法的各種資料結構,函式和宏,有了它們我們可以很方便的造出雜湊表。這裡體現了一種抽象的思想。
-
我們先來看看核心中對於雜湊表結構體的定義:
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};這段程式碼在
types.h中。核心中對於雜湊表,定義了兩種節點,一個是表頭的_head節點,它只有一個指向第一個連結點的first指標。另一個則是用於組成連結串列的_node節點。有趣的是這個_node節點,它不像一般的單連結串列只有一個指向下一節點的
next指標,也不像雙連結串列那樣有一個指向前驅節點的pre指標。 它有一個獨特的二級指標pprev,它是指向哪裡的呢?我們接著往下看。
-
為了瞭解
hlist_node中二級指標的作用,我們去list.h中找找答案 -
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct name = { .first = NULL } //宣告並初始化
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)幾個宏都是對_head進行初始化的宏,在雙連結串列
list_也有類似的寫法,沒有我們想要的二級指標。 -
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}初始化
hlist_node的函式,將_node的連個指標都指向NULL。還是看不出什麼。 -
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
WRITE_ONCE(*pprev, next);
if (next)
next->pprev = pprev;
}刪除某一
hlist_node節點的函式。看看我們找到了什麼:WRITE_ONCE(*pprev, next);這不正是對
pprev進行操作的陳述句嗎。我們知道,鏈地址法就是將產生衝突的若干資料用連結串列串起來儲存,那麼不論是單連結串列,雙連結串列還是其他的什麼,它總歸是個連結串列,對其中節點的刪除也無外乎對其前驅後繼節點指標的修改。
而二級指標就是一個指向指標的指標,*pperv 一次指向運算表示它指向的那個指標,**pperv連次指向運算則表示它指向的指標所指向的地址。
再來看程式碼,首先建立的兩個指標
next和pprev儲存了當前節點指標的指向。而
write_once(a,b)即是a=b;這樣看來我們的
pprev指向的那個指標,就是用來指向當前節點的後繼;最後一步是當後繼節點不為空時,將其
pprev指向當前節點的pprev;結合我們對一般連結串列的刪除操作,當我們刪除一個節點時,用來指向其後繼的應當是其前驅的
next指標。所以pprev正是一個指向前驅節點next指標的指標。下麵是刪除過程的草圖。
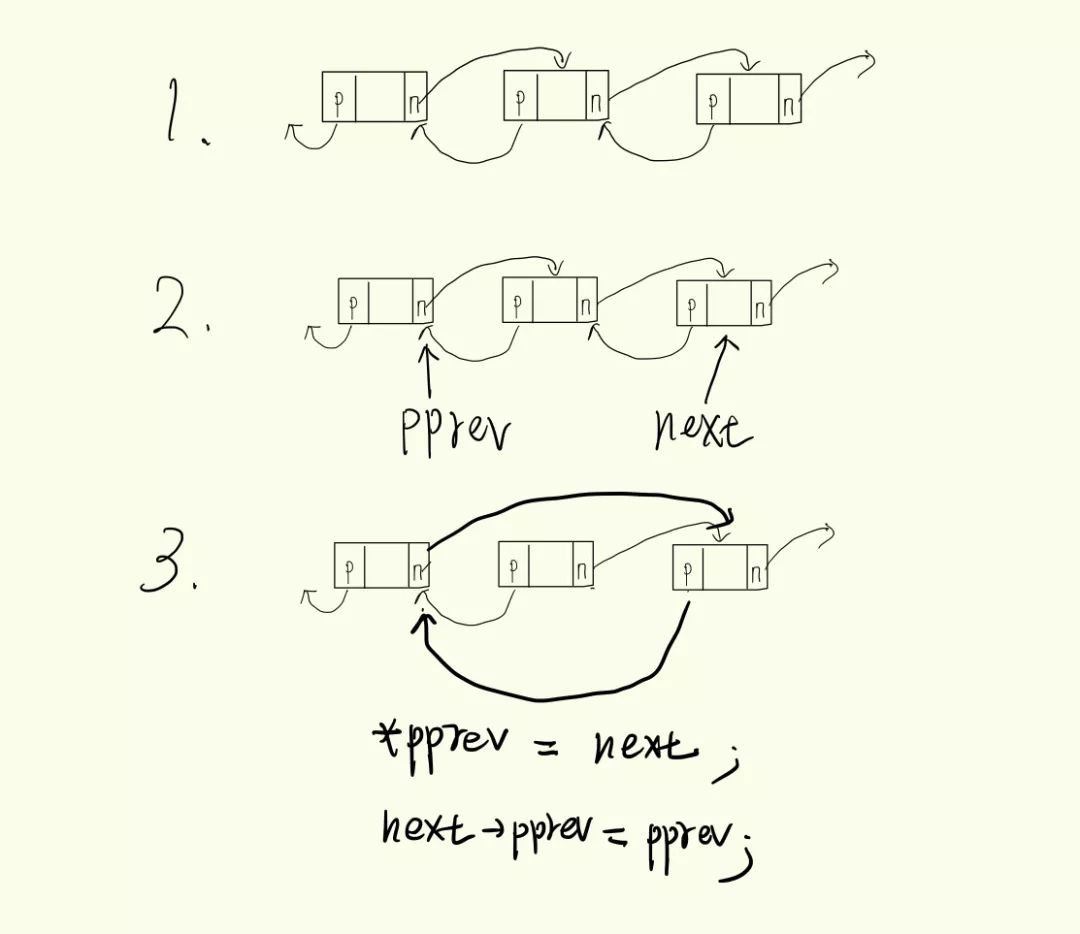
-
搞明白了
hlist_node中的指標,我們終於可以對核心中的雜湊表有一個形象的概念了。
現在,有個問題需要我們仔細想想,為什麼
hlist_node要這樣設計? -
只用一個單連結串列不好嗎?用單連結串列把衝突的節點連起來是沒什麼問題,但是對其進行操作就很煩了,插入還好說,若是刪除某個特定節點,還需要從頭遍歷找到它的前驅才行。
-
那用雙連結串列不就行了嗎?確實,用雙連結串列可以很方便的進行插入刪除等操作,而且list.h中也有現成的函式和宏可以使用。但是,我們對比下hlist和list就能發現它兩最大的區別就在其節點的定義上。list的結構體只有一個節點
list_node,而hlist則是兩種hlist_head和hlist_node。假設我們的hlist_node也是一個雙連結串列結構,有一個指向前驅的pre指標,那麼這個指標在指向hlist_head還時需要進行一次型別轉換,所以在每次操作前都需要判斷其指向節點的型別,這很是麻煩。 -
那索性把
hlist_head也改成hlist_node不就完了麼。這樣一改後的確不再有上述的麻煩,但是又有新的問題,我們的“頭結點”需要這個
pre指標嗎?雜湊表中的“頭節點”不存放資料,只用來指向相應連結串列。給它多增加一個無用的指標,相當於將其空間佔用提高了一倍,雜湊表中頭結點數量與資料總數是在一個數量級上,這將造成巨大的浪費。 -
綜上,linux核心雜湊表無疑是一個非常優秀的設計。
-
list.h中讓我很費解的函式
為雜湊表增加一個虛假節點和判斷一個節點是否是虛假的函式。
static inline void hlist_add_fake(struct hlist_node *n)
{
n->pprev = &n-;>next;
}
static inline bool hlist_fake(struct hlist_node *h)
{
return h->pprev == &h-;>next;
}我只能從陳述句上試著理解其作用,hlish_add_fake函式將一個節點的
pprev指標指向自己的next指標,但這個節點仍可能在hlish節點連結串列上,從而成為一個”虛假節點“。而這樣的”虛假節點“ 仍會被 hlist_unhashed 判斷為已 hash。剛經過初始化的節點,其pprev指向NULL,即未hash。
static inline int hlist_unhashed(const struct hlist_node *h)
{
return !h->pprev;
}而對它進行 hlist_del操作則不會將其從連結串列上刪除,如下圖。其他的用法還不是很清楚。
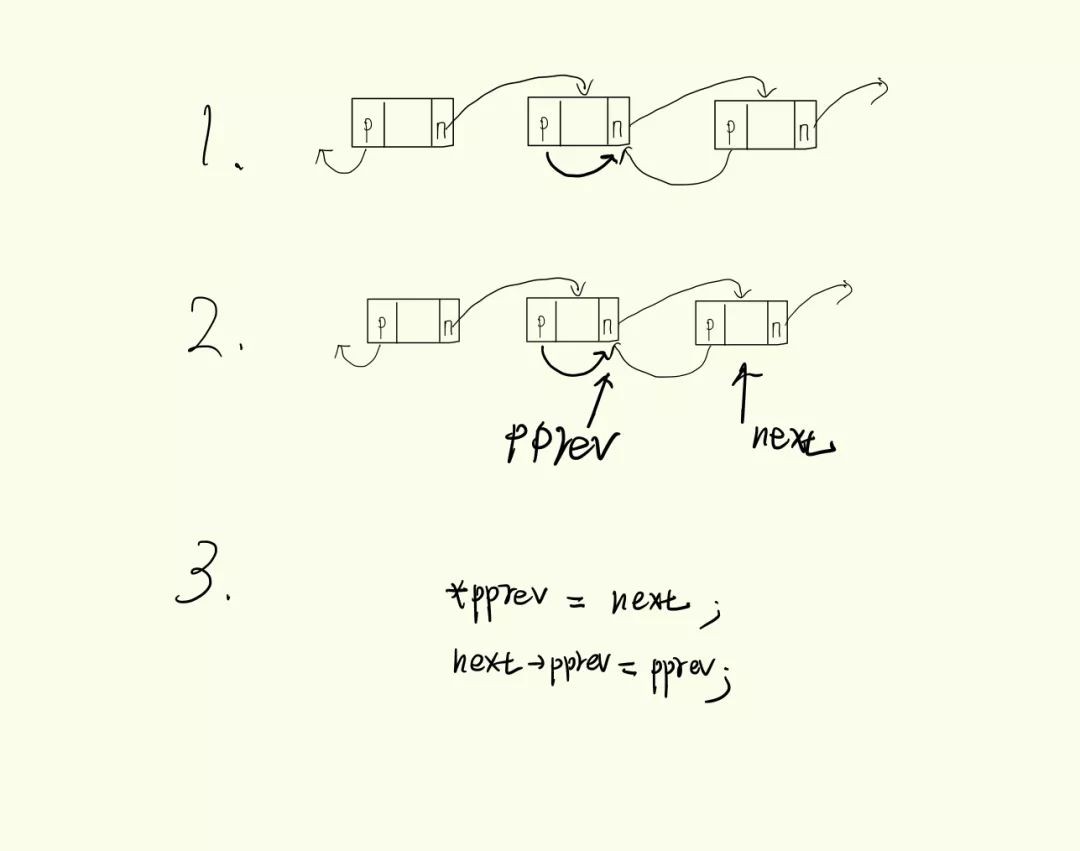
-
遍歷宏
#define hlist_for_each(pos, head)
for (pos = (head)->first; pos ; pos = pos->next)
#define hlist_for_each_safe(pos, n, head)
for (pos = (head)->first; pos && ({ n = pos->next; 1; });
pos = n)兩者的區別與雙連結串列中類似,hlist_for_each_safe 可以在遍歷的過程中對節點進行新增/刪除操作,而前者則不能。
值得一提的是hlist_for_each_safe中的
({ n = pos->next; 1; })它是一條複合陳述句。C語言中複合陳述句:({exp1; exp2; exp3})它的值等於exp3的值。如果exp3不能求值,得到的結果就是void。複合陳述句在核心程式碼中的宏定義中很常見。透過一個複合陳述句將賦值陳述句
n=pos->next寫在for迴圈的判斷條件中,使程式碼更簡潔。
關於hlist大概就是這些,下麵我們看看另一個有趣的宏。
ACCESS_ONCE()宏
-
在閱讀list.h的過程中,經常碰到兩個宏
WRITE_ONCE(a,b)和READ_ONCE(x)。中
#define WRITE_ONCE(var, val)
(*((volatile typeof(val) *)(&(var))) = (val))
#define READ_ONCE(var) (*((volatile typeof(var) *)(&(var))))直接看宏的定義就很複雜,就
READ_ONCE(x)而言,它執行了取地址,強制轉換成某種指標型別,再指向這個指標。從程式碼上來看,WRITE_ONCE(a,b)就等價於a=b,READ_ONCE(x)就是讀取x的值。為什麼要把簡答的陳述句弄的這麼複雜,這背後的原因非常令我好奇。在網上查閱了一些資料後,對這個問題有了一個大致的瞭解。 -
首先
WRITE_ONCE(a,b)和READ_ONCE(x)都屬於ACCESS_ONCE()宏。在LWN上有一篇專門對該宏的介紹(https://lwn.net/Articles/508991/)。該宏的目的確保作為引數傳遞的的值僅由生成的程式碼訪問一次。如果不是,C編譯器則會假定它正在編譯的程式的地址空間中只有一個執行執行緒,通俗的說就是C編譯器認為該程式只會由一個執行緒來執行。這會導致一些併發性上的問題,而C語言本身並沒有併發的概念。所以需要在C語言之上構建處理併發訪問的機制,ACCESS_ONCE()宏就是這樣一種機制。
而為了實現這種機制,則需要用到volatile 變數。關於volatile變數,維基百科中解釋的很清楚:
volatile關鍵字宣告的變數或物件通常具有與最佳化、多執行緒相關的特殊屬性。通常,volatile關鍵字用來阻止(偽)編譯器認為的無法“被程式碼本身”改變的程式碼(變數/物件)進行最佳化。如在C語言中,volatile關鍵字可以用來提醒編譯器它後面所定義的變數隨時有可能改變,因此編譯後的程式每次需要儲存或讀取這個變數的時候,都會直接從變數地址中讀取資料。如果沒有volatile關鍵字,則編譯器可能最佳化讀取和儲存,可能暫時使用暫存器中的值,如果這個變數由別的程式更新了的話,將出現不一致的現象。
一個簡單的例子可以幫助我們理解volatile的作用。
在這裡例子中,程式碼將
foo的值設定為0。然後開始不斷地輪詢它的值直到它變成255:
static int foo;
void bar(void) {
foo = 0;
while (foo != 255)
;
}一個執行最佳化的編譯器會提示沒有程式碼能修改
foo的值,並假設它永遠都只會是0.因此編譯器將用類似下列的無限迴圈替換函式體
void bar_optimized(void) {
foo = 0;
while (true)
;
}但是,foo可能指向一個隨時都能被計算機系統其他部分修改的地址,例如一個連線到中央處理器的裝置的硬體暫存器,上面的程式碼永遠檢測不到這樣的修改。如果不使用volatile關鍵字,編譯器將假設當前程式是系統中唯一能改變這個值部分。 為了阻止編譯器像上面那樣最佳化程式碼,需要使用volatile關鍵字:
static volatile int foo;
void bar (void) {
foo = 0;
while (foo != 255)
;
}這樣修改以後迴圈條件就不會被最佳化掉,當值改變的時候系統將會檢測到。
-
然後,結合的
ACCESS_ONCE()宏的定義:先取x的地址,將其強制轉換為 x 型別的volatile 指標,再指向該指標。
#define ACCESS_ONCE(x)(*(volatile typeof(x)*)&(x))下麵這種寫法可能看的更清楚:
volatile typeof(x) *p = &(x);
*p;ACCESS_ONCE()宏的工作原理就是將相關變數的型別臨時轉換為volatile型別,直接對其記憶體地址進行訪問。 -
最後,還有一個問題:在同一個函式內,同樣的賦值操作,為什麼有的地方可以直接賦值,而有的地方卻需要用到
ACCESS_ONCE()宏?LWN中是這樣寫的:
大多數併發訪問資料是(或應該是)由鎖保護。如果程式碼只訪問具有相關鎖的共享變數,並且該變數只能在釋放鎖(並由另一個執行緒持有)時更改,則編譯器不會產生問題。只有在沒有鎖的情況下訪問共享資料的地方才會需要像
ACCESS_ONCE()這樣的宏。那麼新的問題又來了,如何找到這些沒有上鎖的共享資料?
