薛磊:Momenta資深研發工程師,前Sun中國工程研究院工程師,專註於分散式系統、儲存系統、容器等技術,目前從事深度學習訓練平臺的基礎架構研發。熱愛開源和分享,目前是Kubeflow member及多個開源專案contributor。
前言
目前人工智慧非常火,大家所熟知的人臉識別、智慧安防、自動駕駛等領域都在應用人工智慧技術。但在自動駕駛這個行業中我們能用Go語言做什麼事情?今天分享的主要是人工智慧資料流的流轉方式,也是Golang在Momenta大資料平臺當中的應用。
Momenta大資料平臺

Momenta的標的是打造自動駕駛大腦,基於深度學習和海量資料,Momenta已經形成服務多個場景的自動駕駛解決方案,解決了逆光、橋、隧道、雨天、夜間、匝道等複雜道路場景。
在實現自動駕駛的過程中,深度學習的演演算法在訓練模型時得有基礎資料作支撐,需要大量的影象資料。藉助團隊極強的研究能力與工程能力,Momenta已經建立起大資料平臺、大計算平臺、大測試平臺三大基礎平臺,從而實現大資料與AI演演算法的反饋閉環——以強大的計算資源處理豐富的海量資料,得到更精準、更可靠的演演算法模型。
其中,大資料平臺能夠完美處理自動駕駛領域的資料流,具體而言,便是處理收集資料、篩選資料、資料標註、訓練模型、模型測試、封裝釋出的整個過程。
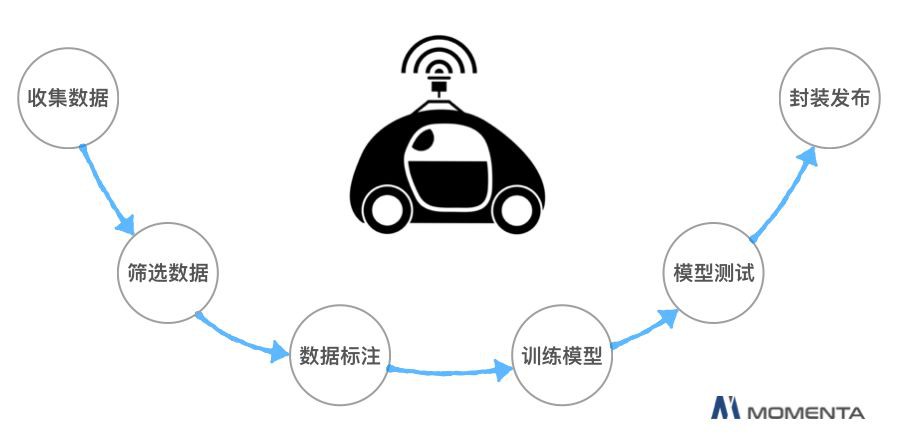
人工智慧資料流
資料篩選

上圖是車輛識別的一個典型,富有中國特色和北京特色——電動車,Momenta目前對電動車、腳踏車、人力三輪車、三輪電動車等,都能進行識別,並且達到很高的準確度。在人工智慧資料流中,資料篩選這一步驟主要有以下作用:
資料標註
經過篩選之後,會有部分圖片需要人工標註。基於極強的工程能力,Momenta開發了線上遠端眾包資料標註系統,實習視覺化操作,即便標註人員不懂程式碼也能遠端完成各類標註任務。資料標註的作用主要是提高模型訓練精度, 獲得更多標註圖片,提取包含識別標的的素材,提高訓練精度。
模型訓練

上圖是模型訓練的流程圖,其中,在資料匯入、模型訓練和模型驗證Momenta都做出了極大的創新。
與傳統方式相比,Momenta採用的共享叢集排程讓使用者(內部的演演算法研發人員)可以編寫任務描述和訓練指令碼,而管理員透過網頁介面進行叢集管理和工作排程。極大地節省人工成本,提高資源利用率,實現集中性管理,提高安全性。

Golang 在人工智慧資料流中的應用
Golang在人工智慧資料流中主要應用在篩選系統、標註系統和訓練系統。
篩選系統

Momenta每天可能需要處理幾千萬張圖片,資料量巨大,如果逐一進行標註將給儲存帶來很大的挑戰。解決這個問題的方法就是篩選系統,透過篩選系統,我們將大的資料集拆分為小的單元,每個單元中包含小的任務,而每個單元對應一個 GPU,使用 GPU進行智慧篩選。最終只有約10%的圖片時需要進行標註的,大大減少了資料標註的成本。
標註系統

Momenta為內部演演算法研發人員服務的標註系統,可以實現使用者管理、任務分發、計費、結算和自動審核。自動審核是比較特殊的,在一般場景和服務中用得比較少,自動審核是指用Momenta的模型來證實使用者(在平臺上兼職標註的人員)的標註結果是否符合需求或預期,主要是應付較大的使用者訪問,特別是節假日的時候。(節假日期間平臺的使用者比較閑,會希望在平臺上賺點零花錢。)
訓練系統

訓練系統是基於K8S搭建使用的,能夠實現自己的排程。K8S作為容器的排程平臺,預設是排程一個pod在不同的機器上面執行的,但是做多機訓練可能需要同時使用多個Pod,每個機器上面一個Pod。這樣就需要相應的管理以及生命週期的維護,我們這套系統是基於K8S做的開發,承擔這樣的工作。
機器學習場景下Golang的發展
如果此前沒有接觸過機器學習?如何能夠加入人工智慧的浪潮中,學習併進入機器學習領域呢?Go Notebooks、Caffe和Caffe2,TensorFlow-Go幾個工具都是很好的工具。接下來將演示如何用TensorFlow的Golang binding做一個簡單工具。
基於已有模型(他人訓練的模型),對圖片進行載入,隨後可輸出帶有標記框的圖片,也是模型識別的效果。
所用的程式碼參考如下:


建議可嘗試用自己的模型或是TensorFlow官方模型形成小的應用,例如人臉識別。但官方公佈的模型精度都不高,原因是資料集較小,Momenta擁有的大資料平臺能有效降低人工標註的成本,但大資料的訓練往往涉及到多機訓練。多機訓練已經經歷了三個重要時期,我們定義為:史前時代、石器時代和現代文明。
史前時代 
多機訓練最原始的階段是直接登入到某幾臺機器,安裝各類訓練框架、驅動和網路配置等,在每臺機器上跑訓練任務,很難進行最佳化。容器出現後,可被用來避免某些重覆的配置,讓多機訓練進入了下一個時代——石器時代。
石器時代

藉助Docker 將智慧框架進行封裝,在每臺機器上面執行命令。
現代文明


在現代文明階段,所有排程和管理工作都透過容器進行,可以同時管理幾百臺機器。能夠進入這個階段主要是靠眾多開源社群的努力和合作,比如 TensorFlow和Kubernetes的強強聯合便誕生了Kubeflow。
KubeFlow其實是一些工具的整合或是一些框架,它有官方的自定義資源以及Caffe2的資源。透過KubeFlow,使用者只需要敲幾行命令便可進行多機的訓練,也可以實現簡單的模型訓練。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式
