-
強大的多維度資料模型:
-
時間序列資料透過 metric 名和鍵值對來區分。
-
所有的 metrics 都可以設定任意的多維標簽。
-
資料模型更隨意,不需要刻意設定為以點分隔的字串。
-
可以對資料模型進行聚合,切割和切片操作。
-
支援雙精度浮點型別,標簽可以設為全 unicode。
-
靈活而強大的查詢陳述句(PromQL):在同一個查詢陳述句,可以對多個 metrics 進行乘法、加法、連線、取分數位等操作。
-
易於管理: Prometheus server 是一個單獨的二進位制檔案,可直接在本地工作,不依賴於分散式儲存。
-
高效:平均每個取樣點僅佔 3.5 bytes,且一個 Prometheus server 可以處理數百萬的 metrics。
-
使用 pull 樣式採集時間序列資料,這樣不僅有利於本機測試而且可以避免有問題的伺服器推送壞的 metrics。
-
可以採用 push gateway 的方式把時間序列資料推送至 Prometheus server 端。
-
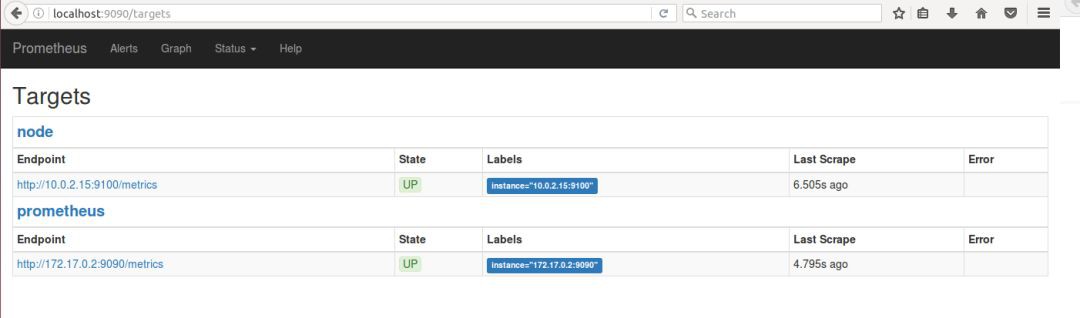
可以透過服務發現或者靜態配置去獲取監控的 targets。
-
有多種視覺化圖形介面。
-
易於伸縮。
-
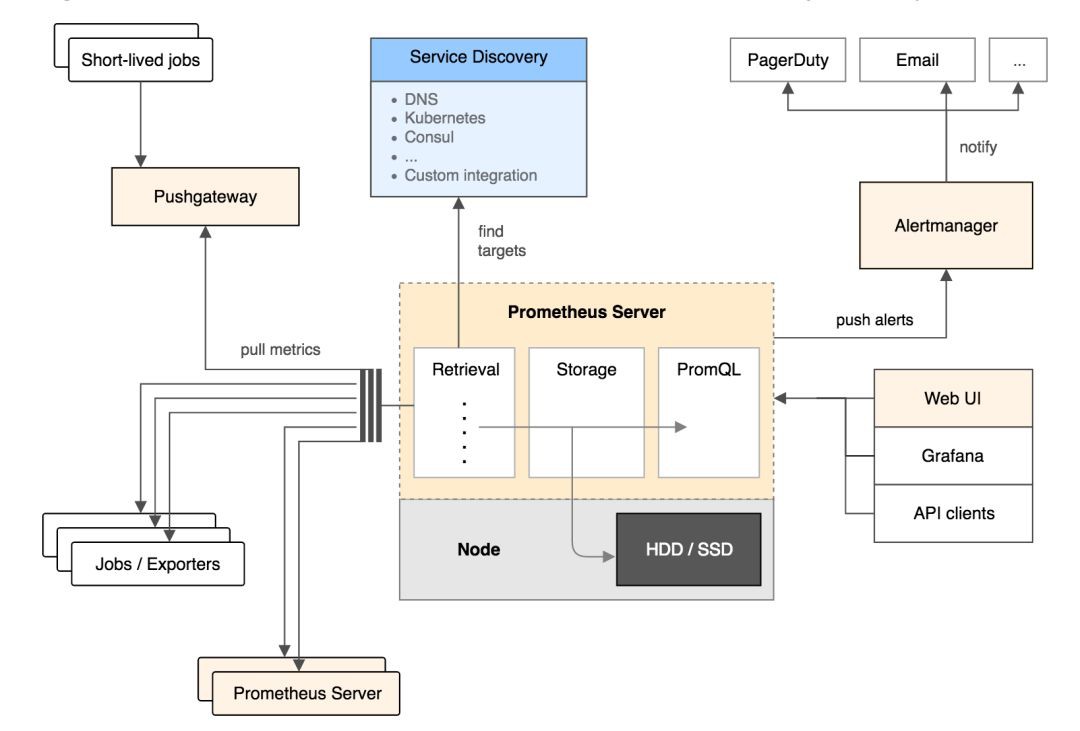
Prometheus Server:用於收集和儲存時間序列資料。
-
Client Library: 客戶端庫,為需要監控的服務生成相應的 metrics 並暴露給 Prometheus server。當 Prometheus server 來 pull 時,直接傳回實時狀態的 metrics。
-
Push Gateway:主要用於短期的 jobs。由於這類 jobs 存在時間較短,可能在 Prometheus 來 pull 之前就消失了。為此,這次 jobs 可以直接向 Prometheus server 端推送它們的 metrics。這種方式主要用於服務層面的 metrics,對於機器層面的 metrices,需要使用 node exporter。
-
Exporters:用於暴露已有的第三方服務的 metrics 給 Prometheus。
-
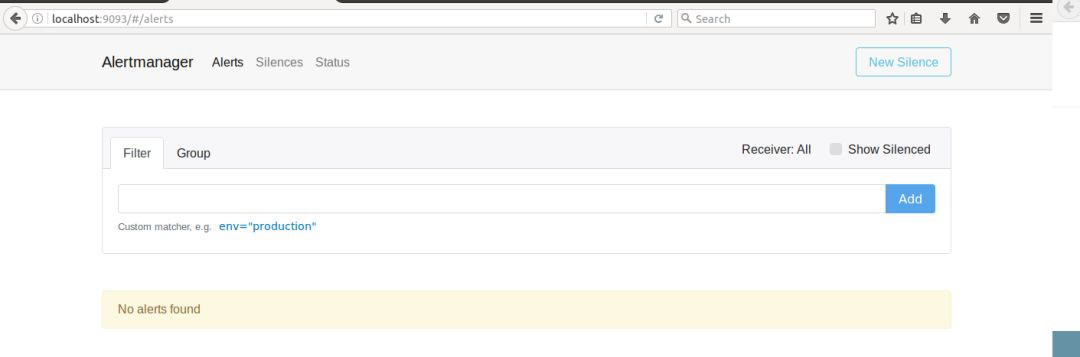
Alertmanager:從 Prometheus server 端接收到 alerts 後,會進行去除重覆資料,分組,並路由到對收的接受方式,發出報警。常見的接收方式有:電子郵件,pagerduty,OpsGenie, webhook 等。
一些其他的工具。
-
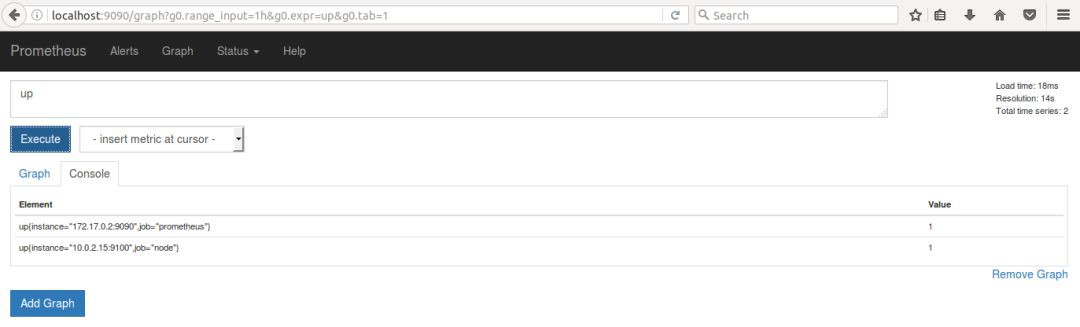
Prometheus server 定期從配置好的 jobs 或者 exporters 中拉 metrics,或者接收來自 Pushgateway 發過來的 metrics,或者從其他的 Prometheus server 中拉 metrics。
-
Prometheus server 在本地儲存收集到的 metrics,並執行已定義好的 alert.rules,記錄新的時間序列或者向 Alertmanager 推送警報。
-
Alertmanager 根據配置檔案,對接收到的警報進行處理,發出告警。
-
在圖形介面中,視覺化採集資料。
-
metric 名字:該名字應該具有語意,一般用於表示 metric 的功能,例如:http_requests_total, 表示 http 請求的總數。其中,metric 名字由 ASCII 字元,數字,下劃線,以及冒號組成,且必須滿足正則運算式 [a-zA-Z_:][a-zA-Z0-9_:]*。
-
標簽:使同一個時間序列有了不同維度的識別。例如 http_requests_total{method=”Get”} 表示所有 http 請求中的 Get 請求。當 method=”post” 時,則為新的一個 metric。標簽中的鍵由 ASCII 字元,數字,以及下劃線組成,且必須滿足正則運算式 [a-zA-Z_:][a-zA-Z0-9_:]*。
-
樣本:實際的時間序列,每個序列包括一個 float64 的值和一個毫秒級的時間戳。
-
格式:{=, …},例如:http_requests_total{method=”POST”,endpoint=”/api/tracks”}。

-
類似於 Histogram,典型的應用如:請求持續時間,響應大小。
-
提供觀測值的 count 和 sum 功能。
-
提供百分位的功能,即可以按百分比劃分跟蹤結果。
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671

cd /home/lilly/prom/exporters/
wget https://github.com/prometheus/node_exporter/releases/download/v0.14.0/node_exporter-0.14.0.linux-amd64.tar.gz
tar -xvzf node_exporter-0.14.0.linux-amd64.tar.gz
vim /etc/init/node_exporter.conf
#Prometheus Node Exporter Upstart script
start on startup
script
/home/lilly/prom/exporters/node_exporter/node_exporter
end script
root@ubuntu1404-dev:~/alertmanager# service node_exporter start
node_exporter start/running, process 11017
root@ubuntu1404-dev:~/alertmanager# service node_exporter status
node_exporter start/running, process 11017
此時,node exporter 已經監聽在 9100 埠。
root@ubuntu1404-dev:~/prom# netstat -anp | grep 9100
tcp6 0 0 :::9100 :::* LISTEN 155/node_exporter
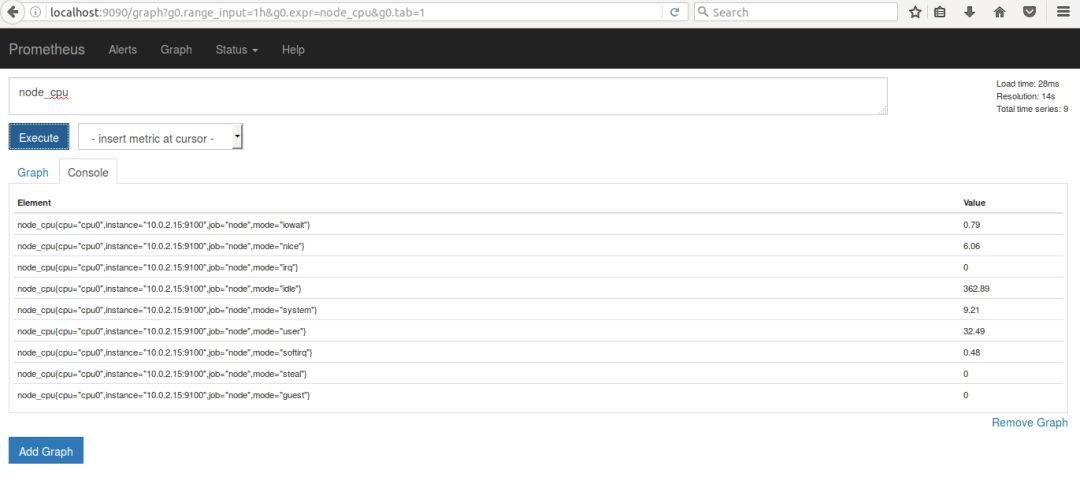
root@ubuntu1404-dev:~/prom# curl http://localhost:9100/metrics
……
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="guest"} 0
node_cpu{cpu="cpu0",mode="idle"} 30.02
node_cpu{cpu="cpu0",mode="iowait"} 0.5
node_cpu{cpu="cpu0",mode="irq"} 0
node_cpu{cpu="cpu0",mode="nice"} 0
node_cpu{cpu="cpu0",mode="softirq"} 0.34
node_cpu{cpu="cpu0",mode="steal"} 0
node_cpu{cpu="cpu0",mode="system"} 5.38
node_cpu{cpu="cpu0",mode="user"} 11.34
# HELP node_disk_bytes_read The total number of bytes read successfully.
# TYPE node_disk_bytes_read counter
node_disk_bytes_read{device="sda"} 5.50009856e+08
node_disk_bytes_read{device="sr0"} 67584
# HELP node_disk_bytes_written The total number of bytes written successfully.
# TYPE node_disk_bytes_written counter
node_disk_bytes_written{device="sda"} 2.0160512e+07
node_disk_bytes_written{device="sr0"} 0
# HELP node_disk_io_now The number of I/Os currently in progress.
# TYPE node_disk_io_now gauge
node_disk_io_now{device="sda"} 0
node_disk_io_now{device="sr0"} 0
# HELP node_disk_io_time_ms Total Milliseconds spent doing I/Os.
# TYPE node_disk_io_time_ms counter
node_disk_io_time_ms{device="sda"} 3484
node_disk_io_time_ms{device="sr0"} 12
……
# HELP node_memory_MemAvailable Memory information field MemAvailable.
# TYPE node_memory_MemAvailable gauge
node_memory_MemAvailable 1.373270016e+09
# HELP node_memory_MemFree Memory information field MemFree.
# TYPE node_memory_MemFree gauge
node_memory_MemFree 9.2403712e+08
# HELP node_memory_MemTotal Memory information field MemTotal.
# TYPE node_memory_MemTotal gauge
node_memory_MemTotal 2.098388992e+09
……
# HELP node_network_receive_drop Network device statistic receive_drop.
# TYPE node_network_receive_drop gauge
node_network_receive_drop{device="docker0"} 0
node_network_receive_drop{device="eth0"} 0
node_network_receive_drop{device="eth1"} 0
node_network_receive_drop{device="lo"} 0
docker run -d -p 9090:9090 \
-v $PWD/prometheus.yml:/etc/prometheus/prometheus.yml \
-v $PWD/alert.rules:/etc/prometheus/alert.rules \
--name prometheus \
prom/prometheus \
-config.file=/etc/prometheus/prometheus.yml \
-alertmanager.url=http://10.0.2.15:9093
global: # 全域性設定,可以被改寫
scrape_interval: 15s # 預設值為 15s,用於設定每次資料收集的間隔
external_labels: # 所有時間序列和警告與外部通訊時用的外部標簽
monitor: 'codelab-monitor'
rule_files: # 警告規則設定檔案
- '/etc/prometheus/alert.rules'
# 用於配置 scrape 的 endpoint 配置需要 scrape 的 targets 以及相應的引數
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus' # 一定要全域性唯一, 採集 Prometheus 自身的 metrics
# 改寫全域性的 scrape_interval
scrape_interval: 5s
static_configs: # 靜態標的的配置
- targets: ['172.17.0.2:9090']
- job_name: 'node' # 一定要全域性唯一, 採集本機的 metrics,需要在本機安裝 node_exporter
scrape_interval: 10s
static_configs:
- targets: ['10.0.2.15:9100'] # 本機 node_exporter 的 endpoint
# Alert for any instance that is unreachable for >5 minutes.
ALERT InstanceDown # alert 名字
IF up == 0 # 判斷條件
FOR 5m # 條件保持 5m 才會發出 alert
LABELS { severity = "critical" } # 設定 alert 的標簽
ANNOTATIONS { # alert 的其他標簽,但不用於標識 alert
summary = "Instance {{ $labels.instance }} down",
description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.",
}
time="2017-09-05T08:18:02Z" level=info msg="Starting prometheus (version=1.7.1, branch=master,
revision=3afb3fffa3a29c3de865e1172fb740442e9d0133)" source="main.go:88"
time="2017-09-05T08:18:02Z" level=info msg="Build context (go=go1.8.3, user=root@0aa1b7fc430d, date=20170612-
11:44:05)" source="main.go:89"
time="2017-09-05T08:18:02Z" level=info msg="Host details (Linux 3.19.0-75-generic #83~14.04.1-Ubuntu SMP Thu Nov
10 10:51:40 UTC 2016 x86_64 71984d75e6a1 (none))" source="main.go:90"
time="2017-09-05T08:18:02Z" level=info msg="Loading configuration file /etc/prometheus/prometheus.yml"
source="main.go:252"
time="2017-09-05T08:18:03Z" level=info msg="Loading series map and head chunks..." source="storage.go:428"
time="2017-09-05T08:18:03Z" level=info msg="0 series loaded." source="storage.go:439"
time="2017-09-05T08:18:03Z" level=info msg="Starting target manager..." source="targetmanager.go:63"
time="2017-09-05T08:18:03Z" level=info msg="Listening on :9090" source="web.go:259"


root@ubuntu1404-dev:~/alertmanager# cat config.yml
global:
resolve_timeout: 5m
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 1m
repeat_interval: 1m
group_by: ['alertname']
routes:
- match:
severity: critical
receiver: my-slack
receivers:
- name: 'my-slack'
slack_configs:
- send_resolved: true
api_url: https://hooks.slack.com/services/***
channel: '#alertmanager-critical'
text: "{{ .CommonAnnotations.description }}"
- name: 'default-receiver'
slack_configs:
- send_resolved: true
api_url: https://hooks.slack.com/services/***
channel: '#alertmanager-default'
text: "{{ .CommonAnnotations.description }}"
docker run -d -p 9093:9093
–v /home/lilly/alertmanager/config.yml:/etc/alertmanager/config.yml \
--name alertmanager \
prom/alertmanager
docker ps | grep alert
d1b7a753a688 prom/alertmanager "/bin/alertmanager -c" 25 hours ago Up 25 hours
0.0.0.0:9093->9093/tcp alertmanager


root@ubuntu1404-dev:~/prom# service node_exporter stop
node_exporter stop/waiting
root@ubuntu1404-dev:~/prom# service node_exporter status
node_exporter stop/waiting