來自:Java3y(微訊號:java3y)
索引和鎖在資料庫中可以說是非常重要的知識點了,在面試中也會經常會被問到的。
本文力求簡單講清每個知識點,希望大家看完能有所收穫
宣告:如果沒有說明具體的資料庫和儲存引擎,預設指的是MySQL中的InnoDB儲存引擎
一、索引
在之前,我對索引有以下的認知:
- 索引可以加快資料庫的檢索速度
- 表經常進行
INSERT/UPDATE/DELETE操作就不要建立索引了,換言之:索引會降低插入、刪除、修改等維護任務的速度。 - 索引需要佔物理和資料空間。
- 瞭解過索引的最左匹配原則
- 知道索引的分類:聚集索引和非聚集索引
- Mysql支援Hash索引和B+樹索引兩種
看起來好像啥都知道,但面試讓你說的時候可能就GG了:
- 使用索引為什麼可以加快資料庫的檢索速度啊?
- 為什麼說索引會降低插入、刪除、修改等維護任務的速度。
- 索引的最左匹配原則指的是什麼?
- Hash索引和B+樹索引有什麼區別?主流的使用哪一個比較多?InnoDB儲存都支援嗎?
- 聚集索引和非聚集索引有什麼區別?
- ……..
1.1聊聊索引的基礎知識
首先Mysql的基本儲存結構是頁(記錄都存在頁裡邊):

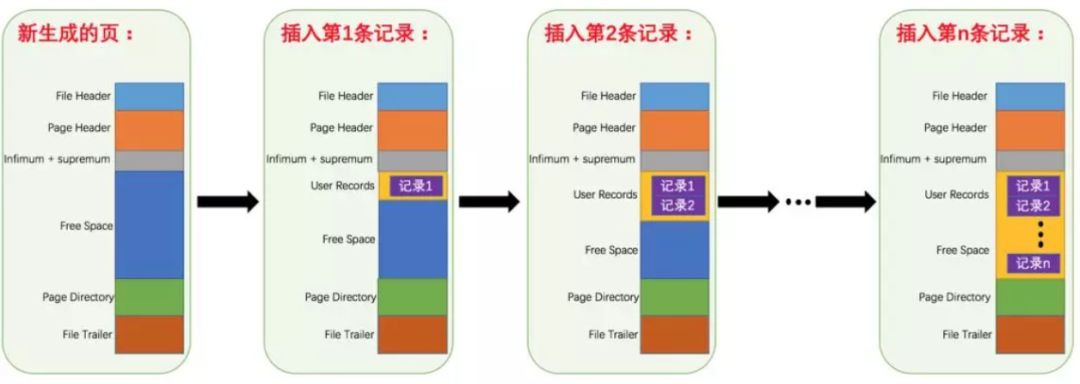
- 各個資料頁可以組成一個雙向連結串列
- 而每個資料頁中的記錄又可以組成一個單向連結串列
- 每個資料頁都會為儲存在它裡邊兒的記錄生成一個頁目錄,在透過主鍵查詢某條記錄的時候可以在頁目錄中使用二分法快速定位到對應的槽,然後再遍歷該槽對應分組中的記錄即可快速找到指定的記錄
- 以其他列(非主鍵)作為搜尋條件:只能從最小記錄開始依次遍歷單連結串列中的每條記錄。
所以說,如果我們寫 select*fromuserwhereusername='Java3y'這樣沒有進行任何最佳化的sql陳述句,預設會這樣做:
- 定位到記錄所在的頁
- 需要遍歷雙向連結串列,找到所在的頁
- 從所在的頁內中查詢相應的記錄
- 由於不是根據主鍵查詢,只能遍歷所在頁的單連結串列了
很明顯,在資料量很大的情況下這樣查詢會很慢!
1.2索引提高檢索速度
索引做了些什麼可以讓我們查詢加快速度呢?
其實就是將無序的資料變成有序(相對):

要找到id為8的記錄簡要步驟:

很明顯的是:沒有用索引我們是需要遍歷雙向連結串列來定位對應的頁,現在透過“目錄”就可以很快地定位到對應的頁上了!
其實底層結構就是B+樹,B+樹作為樹的一種實現,能夠讓我們很快地查找出對應的記錄。
參考資料:
1.3索引降低增刪改的速度
B+樹是平衡樹的一種。
平衡樹:它是一棵空樹或它的左右兩個子樹的高度差的絕對值不超過1,並且左右兩個子樹都是一棵平衡二叉樹。
如果一棵普通的樹在極端的情況下,是能退化成連結串列的(樹的優點就不復存在了)

B+樹是平衡樹的一種,是不會退化成連結串列的,樹的高度都是相對比較低的(基本符合矮矮胖胖(均衡)的結構)【這樣一來我們檢索的時間複雜度就是O(logn)】!從上一節的圖我們也可以看見,建立索引實際上就是建立一顆B+樹。
- B+樹是一顆平衡樹,如果我們對這顆樹增刪改的話,那肯定會破壞它的原有結構。
- 要維持平衡樹,就必須做額外的工作。正因為這些額外的工作開銷,導致索引會降低增刪改的速度
B+樹刪除和修改具體可參考:
- https://www.cnblogs.com/wade-luffy/p/6292784.html
1.4雜湊索引
除了B+樹之外,還有一種常見的是雜湊索引。
雜湊索引就是採用一定的雜湊演演算法,把鍵值換算成新的雜湊值,檢索時不需要類似B+樹那樣從根節點到葉子節點逐級查詢,只需一次雜湊演演算法即可立刻定位到相應的位置,速度非常快。
- 本質上就是把鍵值換算成新的雜湊值,根據這個雜湊值來定位。

看起來雜湊索引很牛逼啊,但其實雜湊索引有好幾個侷限(根據他本質的原理可得):
- 雜湊索引也沒辦法利用索引完成排序
- 不支援最左匹配原則
- 在有大量重覆鍵值情況下,雜湊索引的效率也是極低的—->雜湊碰撞問題。
- 不支援範圍查詢
參考資料:
- hash索引和b+tree索引
- http://www.cnblogs.com/zengkefu/p/5647279.html
1.5InnoDB支援雜湊索引嗎?
主流的還是使用B+樹索引比較多,對於雜湊索引,InnoDB是自適應雜湊索引的(hash索引的建立由InnoDB儲存引擎引擎自動最佳化建立,我們幹預不了)!

參考資料:
- https://blog.csdn.net/doctor_who2004/article/details/77414742
1.6聚集和非聚集索引
簡單概括:
- 聚集索引就是以主鍵建立的索引
- 非聚集索引就是以非主鍵建立的索引
區別:
- 聚集索引在葉子節點儲存的是表中的資料
- 非聚集索引在葉子節點儲存的是主鍵和索引列
- 使用非聚集索引查詢出資料時,拿到葉子上的主鍵再去查到想要查詢的資料。(拿到主鍵再查詢這個過程叫做回表)
非聚集索引也叫做二級索引,不用糾結那麼多名詞,將其等價就行了~
非聚集索引在建立的時候也未必是單列的,可以多個列來建立索引。
- 此時就涉及到了哪個列會走索引,哪個列不走索引的問題了(最左匹配原則–>後面有說)
- 建立多個單列(非聚集)索引的時候,會生成多個索引樹(所以過多建立索引會佔用磁碟空間)
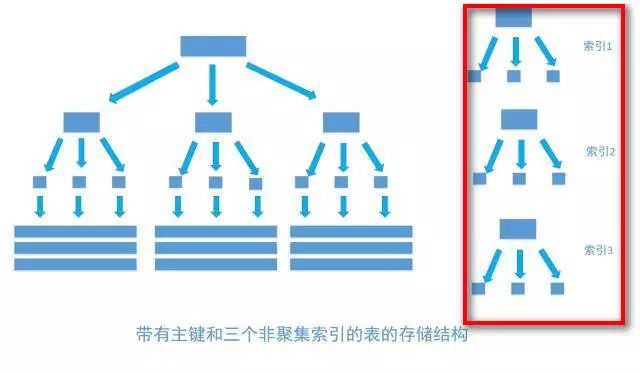
在建立多列索引中也涉及到了一種特殊的索引–>改寫索引
- 我們前面知道了,如果不是聚集索引,葉子節點儲存的是主鍵+列值
- 最終還是要“回表”,也就是要透過主鍵再查詢一次。這樣就會比較慢
- 改寫索引就是把要查詢出的列和索引是對應的,不做回表操作!
比如說:
- 現在我建立了索引
(username,age),在查詢資料的時候:selectusername,agefromuserwhereusername='Java3y'andage=20。 - 很明顯地知道,我們上邊的查詢是走索引的,並且,要查詢出的列在葉子節點都存在!所以,就不用回表了~
- 所以,能使用改寫索引就儘量使用吧~
1.7索引最左匹配原則
最左匹配原則:
- 索引可以簡單如一個列
(a),也可以複雜如多個列(a,b,c,d),即聯合索引。 - 如果是聯合索引,那麼key也由多個列組成,同時,索引只能用於查詢key是否存在(相等),遇到範圍查詢
(>、between、like左匹配)等就不能進一步匹配了,後續退化為線性查詢。 - 因此,列的排列順序決定了可命中索引的列數。
例子:
- 如有索引
(a,b,c,d),查詢條件a=1andb=2andc>3andd=4,則會在每個節點依次命中a、b、c,無法命中d。(c已經是範圍查詢了,d肯定是排不了序了)
為什麼能命中c?
舉個簡單例子: select*fromuserwhereage>30; 如果在age列建立索引,那你說會走索引嗎?
1.8=、in自動最佳化順序
不需要考慮=、in等的順序,mysql會自動最佳化這些條件的順序,以匹配盡可能多的索引列。
例子:
- 如有索引
(a,b,c,d),查詢條件c>3andb=2anda=1andd<4與a=1andc>3andb=2andd<4等順序都是可以的,MySQL會自動最佳化為a=1andb=2andc>3andd<4,依次命中a、b、c。
1.9索引總結
索引在資料庫中是一個非常重要的知識點!上面談的其實就是索引最基本的東西,要創建出好的索引要顧及到很多的方面:
- 1,最左字首匹配原則。這是非常重要、非常重要、非常重要(重要的事情說三遍)的原則,MySQL會一直向右匹配直到遇到範圍查詢
(>,BETWEEN,LIKE)就停止匹配。 - 3,儘量選擇區分度高的列作為索引,區分度的公式是
COUNT(DISTINCT col)/COUNT(*)。表示欄位不重覆的比率,比率越大我們掃描的記錄數就越少。 - 4,索引列不能參與計算,儘量保持列“乾凈”。比如,
FROM_UNIXTIME(create_time)='2016-06-06'就不能使用索引,原因很簡單,B+樹中儲存的都是資料表中的欄位值,但是進行檢索時,需要把所有元素都應用函式才能比較,顯然這樣的代價太大。所以陳述句要寫成 :create_time=UNIX_TIMESTAMP('2016-06-06')。 - 5,盡可能的擴充套件索引,不要新建立索引。比如表中已經有了a的索引,現在要加(a,b)的索引,那麼只需要修改原來的索引即可。
- 6,單個多列組合索引和多個單列索引的檢索查詢效果不同,因為在執行SQL時,~~MySQL只能使用一個索引,會從多個單列索引中選擇一個限制最為嚴格的索引~~(經指正,在MySQL5.0以後的版本中,有“合併索引”的策略,翻看了《高效能MySQL 第三版》,書作者認為:還是應該建立起比較好的索引,而不應該依賴於“合併索引”這麼一個策略)。
- “合併索引”策略簡單來講,就是使用多個單列索引,然後將這些結果用“union或者and”來合併起來
參考資料:
- 簡單理解索引
- https://zhuanlan.zhihu.com/p/23624390
- MySQL學習之——索引(普通索引、唯一索引、全文索引、索引匹配原則、索引命中等)
- https://blog.csdn.net/mysteryhaohao/article/details/51719871
- 淺談MySQL的B樹索引與索引最佳化
- https://monkeysayhi.github.io/2018/03/06/%E6%B5%85%E8%B0%88MySQL%E7%9A%84B%E6%A0%91%E7%B4%A2%E5%BC%95%E4%B8%8E%E7%B4%A2%E5%BC%95%E4%BC%98%E5%8C%96/
二、鎖

在mysql中的鎖看起來是很複雜的,因為有一大堆的東西和名詞:排它鎖,共享鎖,表鎖,頁鎖,間隙鎖,意向排它鎖,意向共享鎖,行鎖,讀鎖,寫鎖,樂觀鎖,悲觀鎖,死鎖。這些名詞有的部落格又直接寫鎖的英文的簡寫—>X鎖,S鎖,IS鎖,IX鎖,MMVC…
鎖的相關知識又跟儲存引擎,索引,事務的隔離級別都是關聯的….
這就給初學資料庫鎖的人帶來不少的麻煩~~~於是我下麵就簡單整理一下資料庫鎖的知識點,希望大家看完會有所幫助。
2.1為什麼需要學習資料庫鎖知識
不少人在開發的時候,應該很少會註意到這些鎖的問題,也很少會給程式加鎖(除了庫存這些對數量準確性要求極高的情況下)
一般也就聽過常說的樂觀鎖和悲觀鎖,瞭解過基本的含義之後就沒了~~~
定心丸:即使我們不會這些鎖知識,我們的程式在一般情況下還是可以跑得好好的。因為這些鎖資料庫隱式幫我們加了
- 對於
UPDATE、DELETE、INSERT陳述句,InnoDB會自動給涉及資料集加排他鎖(X) - MyISAM在執行查詢陳述句
SELECT前,會自動給涉及的所有表加讀鎖,在執行更新操作(UPDATE、DELETE、INSERT等)前,會自動給涉及的表加寫鎖,這個過程並不需要使用者幹預
只會在某些特定的場景下才需要手動加鎖,學習資料庫鎖知識就是為了:
- 能讓我們在特定的場景下派得上用場
- 更好把控自己寫的程式
- 在跟別人聊資料庫技術的時候可以搭上幾句話
- 構建自己的知識庫體系!在面試的時候不虛
2.2表鎖簡單介紹
首先,從鎖的粒度,我們可以分成兩大類:
- 表鎖
- 開銷小,加鎖快;不會出現死鎖;鎖定力度大,發生鎖衝突機率高,併發度最低
- 行鎖
- 開銷大,加鎖慢;會出現死鎖;鎖定粒度小,發生鎖衝突的機率低,併發度高
不同的儲存引擎支援的鎖粒度是不一樣的:
- InnoDB行鎖和表鎖都支援!
- MyISAM只支援表鎖!
InnoDB只有透過索引條件檢索資料才使用行級鎖,否則,InnoDB將使用表鎖
- 也就是說,InnoDB的行鎖是基於索引的!
表鎖下又分為兩種樣式:
- 表讀鎖(Table Read Lock)
- 表寫鎖(Table Write Lock)
- 從下圖可以清晰看到,在表讀鎖和表寫鎖的環境下:讀讀不阻塞,讀寫阻塞,寫寫阻塞!
- 讀讀不阻塞:當前使用者在讀資料,其他的使用者也在讀資料,不會加鎖
- 讀寫阻塞:當前使用者在讀資料,其他的使用者不能修改當前使用者讀的資料,會加鎖!
- 寫寫阻塞:當前使用者在修改資料,其他的使用者不能修改當前使用者正在修改的資料,會加鎖!

從上面已經看到了:讀鎖和寫鎖是互斥的,讀寫操作是序列。
- 如果某個行程想要獲取讀鎖,同時另外一個行程想要獲取寫鎖。在mysql裡邊,寫鎖是優先於讀鎖的!
- 寫鎖和讀鎖優先順序的問題是可以透過引數調節的:
max_write_lock_count和low-priority-updates
值得註意的是:
The LOCAL modifier enables nonconflicting INSERT statements (concurrent inserts) by other sessions to execute while the lock is held. (See Section 8.11.3, “Concurrent Inserts”.) However, READ LOCAL cannot be used if you are going to manipulate the database using processes external to the server while you hold the lock. For InnoDB tables, READ LOCAL is the same as READ
- MyISAM可以支援查詢和插入操作的併發進行。可以透過系統變數
concurrent_insert來指定哪種樣式,在MyISAM中它預設是:如果MyISAM表中沒有空洞(即表的中間沒有被刪除的行),MyISAM允許在一個行程讀表的同時,另一個行程從表尾插入記錄。 - 但是InnoDB儲存引擎是不支援的!
參考資料:
- 官方手冊
- https://dev.mysql.com/doc/refman/8.0/en/lock-tables.html
- 幾個引數說明
- http://ourmysql.com/archives/564
2.2行鎖細講
上邊簡單講解了表鎖的相關知識,我們使用Mysql一般是使用InnoDB儲存引擎的。InnoDB和MyISAM有兩個本質的區別:
- InnoDB支援行鎖
- InnoDB支援事務
從上面也說了:我們是很少手動加表鎖的。表鎖對我們程式員來說幾乎是透明的,即使InnoDB不走索引,加的表鎖也是自動的!
我們應該更加關註行鎖的內容,因為InnoDB一大特性就是支援行鎖!
InnoDB實現了以下兩種型別的行鎖。
- 共享鎖(S鎖):允許一個事務去讀一行,阻止其他事務獲得相同資料集的排他鎖。
- 也叫做讀鎖:讀鎖是共享的,多個客戶可以同時讀取同一個資源,但不允許其他客戶修改。
- 排他鎖(X鎖):允許獲得排他鎖的事務更新資料,阻止其他事務取得相同資料集的共享讀鎖和排他寫鎖。
- 也叫做寫鎖:寫鎖是排他的,寫鎖會阻塞其他的寫鎖和讀鎖。
看完上面的有沒有發現,在一開始所說的:X鎖,S鎖,讀鎖,寫鎖,共享鎖,排它鎖其實總共就兩個鎖,只不過它們有多個名字罷了~~~
Intention locks do not block anything except full table requests (for example, LOCK TABLES … WRITE). The main purpose of intention locks is to show that someone is locking a row, or going to lock a row in the table.
另外,為了允許行鎖和表鎖共存,實現多粒度鎖機制,InnoDB還有兩種內部使用的意向鎖(Intention Locks),這兩種意向鎖都是表鎖:
- 意向共享鎖(IS):事務打算給資料行加行共享鎖,事務在給一個資料行加共享鎖前必須先取得該表的IS鎖。
- 意向排他鎖(IX):事務打算給資料行加行排他鎖,事務在給一個資料行加排他鎖前必須先取得該表的IX鎖。
- 意向鎖也是資料庫隱式幫我們做了,不需要程式員操心!
參考資料:
- https://www.zhihu.com/question/51513268
- https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
2.2.1MVCC和事務的隔離級別
資料庫事務有不同的隔離級別,不同的隔離級別對鎖的使用是不同的,鎖的應用最終導致不同事務的隔離級別
MVCC(Multi-Version Concurrency Control)多版本併發控制,可以簡單地認為:MVCC就是行級鎖的一個變種(升級版)。
- 事務的隔離級別就是透過鎖的機制來實現,只不過隱藏了加鎖細節
在表鎖中我們讀寫是阻塞的,基於提升併發效能的考慮,MVCC一般讀寫是不阻塞的(所以說MVCC很多情況下避免了加鎖的操作)
- MVCC實現的讀寫不阻塞正如其名:多版本併發控制—>透過一定機制生成一個資料請求時間點的一致性資料快照(Snapshot),並用這個快照來提供一定級別(陳述句級或事務級)的一致性讀取。從使用者的角度來看,好像是資料庫可以提供同一資料的多個版本。
快照有兩個級別:
- 陳述句級
- 針對於
Readcommitted隔離級別
- 針對於
- 事務級別
- 針對於
Repeatableread隔離級別
- 針對於
我們在初學的時候已經知道,事務的隔離級別有4種:
- Read uncommitted
- 會出現臟讀,不可重覆讀,幻讀
- Read committed
- 會出現不可重覆讀,幻讀
- Repeatable read
- 會出現幻讀(但在Mysql實現的Repeatable read配合gap鎖不會出現幻讀!)
- Serializable
- 序列,避免以上的情況!
Readuncommitted會出現的現象—>臟讀:一個事務讀取到另外一個事務未提交的資料
- 例子:A向B轉賬,A執行了轉賬陳述句,但A還沒有提交事務,B讀取資料,發現自己賬戶錢變多了!B跟A說,我已經收到錢了。A回滾事務【rollback】,等B再檢視賬戶的錢時,發現錢並沒有多。
- 出現臟讀的原因是因為在讀的時候沒有加讀鎖,導致可以讀取出還沒釋放鎖的記錄。
Readuncommitted過程:
- 事務A讀取記錄(沒有加任何的鎖)
- 事務B修改記錄(此時加了寫鎖,並且還沒有commit–>也就沒有釋放掉寫鎖)
- 事務A再次讀取記錄(此時因為事務A在讀取時沒有加任何鎖,所以可以讀取到事務B還沒提交的(沒釋放掉寫鎖)的記錄
Readcommitted避免臟讀的做法其實很簡單:
- 在讀取的時候生成一個版本號,直到事務其他commit被修改了之後,才會有新的版本號
Readcommitted過程:
- 事務A讀取了記錄(生成版本號)
- 事務B修改了記錄(此時加了寫鎖)
- 事務A再讀取的時候,是依據最新的版本號來讀取的(當事務B執行commit了之後,會生成一個新的版本號),如果事務B還沒有commit,那事務A讀取的還是之前版本號的資料。
但 Readcommitted出現的現象—>不可重覆讀:一個事務讀取到另外一個事務已經提交的資料,也就是說一個事務可以看到其他事務所做的修改
- 註:A查詢資料庫得到資料,B去修改資料庫的資料,導致A多次查詢資料庫的結果都不一樣【危害:A每次查詢的結果都是受B的影響的,那麼A查詢出來的資訊就沒有意思了】
上面也說了, Readcommitted是陳述句級別的快照!每次讀取的都是當前最新的版本!
Repeatableread避免不可重覆讀是事務級別的快照!每次讀取的都是當前事務的版本,即使被修改了,也只會讀取當前事務版本的資料。
呃…如果還是不太清楚,我們來看看InnoDB的MVCC是怎麼樣的吧(摘抄《高效能MySQL》)


至於虛讀(幻讀):是指在一個事務內讀取到了別的事務插入的資料,導致前後讀取不一致。
- 註:和不可重覆讀類似,但虛讀(幻讀)會讀到其他事務的插入的資料,導致前後讀取不一致
- MySQL的
Repeatableread隔離級別加上GAP間隙鎖已經處理了幻讀了。
參考資料:
- https://www.jianshu.com/p/cb97f76a92fd
- https://www.zhihu.com/question/263820564
擴充套件閱讀:
- https://www.zhihu.com/question/67739617
2.3樂觀鎖和悲觀鎖
無論是 Readcommitted還是 Repeatableread隔離級別,都是為瞭解決讀寫衝突的問題。
單純在 Repeatableread隔離級別下我們來考慮一個問題:
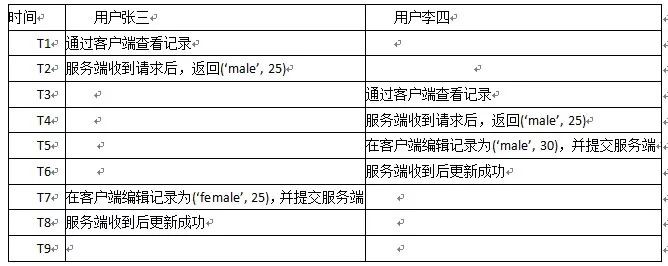
此時,使用者李四的操作就丟失掉了:
- 丟失更新:一個事務的更新改寫了其它事務的更新結果。
(ps:暫時沒有想到比較好的例子來說明更新丟失的問題,雖然上面的例子也是更新丟失,但一定程度上是可接受的..不知道有沒有人能想到不可接受的更新丟失例子呢…)
解決的方法:
- 使用Serializable隔離級別,事務是序列執行的!
- 樂觀鎖
- 悲觀鎖
- 樂觀鎖是一種思想,具體實現是,表中有一個版本欄位,第一次讀的時候,獲取到這個欄位。處理完業務邏輯開始更新的時候,需要再次檢視該欄位的值是否和第一次的一樣。如果一樣更新,反之拒絕。之所以叫樂觀,因為這個樣式沒有從資料庫加鎖,等到更新的時候再判斷是否可以更新。
- 悲觀鎖是資料庫層面加鎖,都會阻塞去等待鎖。
2.3.1悲觀鎖
所以,按照上面的例子。我們使用悲觀鎖的話其實很簡單(手動加行鎖就行了):
select*fromxxxxforupdate
在select 陳述句後邊加了 forupdate相當於加了排它鎖(寫鎖),加了寫鎖以後,其他的事務就不能對它修改了!需要等待當前事務修改完之後才可以修改.
- 也就是說,如果張三使用
select...forupdate,李四就無法對該條記錄修改了~
2.3.2樂觀鎖
樂觀鎖不是資料庫層面上的鎖,是需要自己手動去加的鎖。一般我們新增一個版本欄位來實現:
具體過程是這樣的:
張三 select*fromtable —>會查詢出記錄出來,同時會有一個version欄位

李四 select*fromtable —>會查詢出記錄出來,同時會有一個version欄位
李四對這條記錄做修改: update AsetName=lisi,version=version+1whereID=#{id}andversion=#{version},判斷之前查詢到的version與現在的資料的version進行比較,同時會更新version欄位
此時資料庫記錄如下:

張三也對這條記錄修改: update AsetName=lisi,version=version+1whereID=#{id}andversion=#{version},但失敗了!因為當前資料庫中的版本跟查詢出來的版本不一致!

參考資料:
- 什麼是悲觀鎖和樂觀鎖
- https://zhuanlan.zhihu.com/p/31537871
- 樂觀鎖和 MVCC 的區別?
- https://www.zhihu.com/question/27876575
2.4間隙鎖GAP
當我們用範圍條件檢索資料而不是相等條件檢索資料,並請求共享或排他鎖時,InnoDB會給符合範圍條件的已有資料記錄的索引項加鎖;對於鍵值在條件範圍內但並不存在的記錄,叫做“間隙(GAP)”。InnoDB也會對這個“間隙”加鎖,這種鎖機制就是所謂的間隙鎖。
值得註意的是:間隙鎖只會在 Repeatableread隔離級別下使用~
例子:假如emp表中只有101條記錄,其empid的值分別是1,2,…,100,101
Select * from emp where empid > 100 for update;
上面是一個範圍查詢,InnoDB不僅會對符合條件的empid值為101的記錄加鎖,也會對empid大於101(這些記錄並不存在)的“間隙”加鎖。
InnoDB使用間隙鎖的目的有兩個:
- 為了防止幻讀(上面也說了,
Repeatableread隔離級別下再透過GAP鎖即可避免了幻讀) - 滿足恢復和複製的需要
- MySQL的恢復機制要求:在一個事務未提交前,其他併發事務不能插入滿足其鎖定條件的任何記錄,也就是不允許出現幻讀
2.5死鎖
併發的問題就少不了死鎖,在MySQL中同樣會存在死鎖的問題。
但一般來說MySQL透過回滾幫我們解決了不少死鎖的問題了,但死鎖是無法完全避免的,可以透過以下的經驗參考,來盡可能少遇到死鎖:
- 1)以固定的順序訪問表和行。比如對兩個job批次更新的情形,簡單方法是對id串列先排序,後執行,這樣就避免了交叉等待鎖的情形;將兩個事務的sql順序調整為一致,也能避免死鎖。
- 2)大事務拆小。大事務更傾向於死鎖,如果業務允許,將大事務拆小。
- 3)在同一個事務中,盡可能做到一次鎖定所需要的所有資源,減少死鎖機率。
- 4)降低隔離級別。如果業務允許,將隔離級別調低也是較好的選擇,比如將隔離級別從RR調整為RC,可以避免掉很多因為gap鎖造成的死鎖。
- 5)為表新增合理的索引。可以看到如果不走索引將會為表的每一行記錄新增上鎖,死鎖的機率大大增大。
參考資料:
- http://hedengcheng.com/?p=771#_Toc374698322
- https://www.cnblogs.com/LBSer/p/5183300.html
2.6鎖總結
上面說了一大堆關於MySQL資料庫鎖的東西,現在來簡單總結一下。
表鎖其實我們程式員是很少關心它的:
- 在MyISAM儲存引擎中,當執行SQL陳述句的時候是自動加的。
- 在InnoDB儲存引擎中,如果沒有使用索引,表鎖也是自動加的。
現在我們大多數使用MySQL都是使用InnoDB,InnoDB支援行鎖:
- 共享鎖–讀鎖–S鎖
- 排它鎖–寫鎖–X鎖
在預設的情況下, select是不加任何行鎖的~事務可以透過以下陳述句顯示給記錄集加共享鎖或排他鎖。
- 共享鎖(S):
SELECT*FROM table_name WHERE...LOCK IN SHARE MODE。 - 排他鎖(X):
SELECT*FROM table_name WHERE...FOR UPDATE。
InnoDB基於行鎖還實現了MVCC多版本併發控制,MVCC在隔離級別下的 Readcommitted和 Repeatableread下工作。MVCC能夠實現讀寫不阻塞!
InnoDB實現的 Repeatableread隔離級別配合GAP間隙鎖已經避免了幻讀!
- 樂觀鎖其實是一種思想,正如其名:認為不會鎖定的情況下去更新資料,如果發現不對勁,才不更新(回滾)。在資料庫中往往新增一個version欄位來實現。
- 悲觀鎖用的就是資料庫的行鎖,認為資料庫會發生併發衝突,直接上來就把資料鎖住,其他事務不能修改,直至提交了當前事務
參考資料:
- Mysql鎖總結
- https://zhuanlan.zhihu.com/p/29150809
- MySQL學習之——鎖(行鎖、表鎖、頁鎖、樂觀鎖、悲觀鎖等)
- https://blog.csdn.net/mysteryhaohao/article/details/51669741
- MySQL InnoDB引擎鎖的總結
- https://segmentfault.com/a/1190000015596126
三、總結
本文主要介紹了資料庫中的兩個比較重要的知識點:索引和鎖。他倆可以說息息相關的,鎖會涉及到很多關於索引的知識~
我個人比較重視對整體知識點的把控,一些細節的地方可能就沒有去編寫了。在每一個知識點下都會有很多的內容,有興趣的同學可以在我給出的連結中繼續閱讀學習。當然了,如果有比較好的文章和資料也不妨在評論區分享一下哈~
我只是在學習的過程中,把自己遇到的問題寫出來,整理出來,希望可以對大家有幫助。如果文章有錯的地方,希望大家可以在評論區指正,一起學習交流~
參考資料:
- 《高效能MySQL 第三版》
●編號509,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《25個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
