(給資料分析與開發加星標,提升資料技能)
來源:iceman1952
blog.csdn.net/iceman1952/article/details/85504278
本文中,我們詳細介紹MySQL InnoDB儲存引擎各種不同型別的鎖,以及不同SQL陳述句分別會加什麼樣的鎖。
閱讀提示
1、本文所參考的MySQL檔案版本是8.0,做實驗的MySQL版本是8.0.13
2、本文主要參考了MySQL官方檔案 InnoDB鎖定和事務機制
3、本文還參考了何登成的 MySQL加鎖處理分析、一個最不可思議的MySQL死鎖分析 以及阿裡雲RDS-資料庫核心組的 常用SQL陳述句的MDL加鎖原始碼分析
4、MySQL是外掛式的表儲存引擎,資料庫的鎖是和儲存引擎相關的,本文討論的鎖都是InnoDB儲存引擎的鎖
文章正文開始
“加什麼樣的鎖”與以下因素相關
1、當前事務的隔離級別
2、SQL是一致性非鎖定讀(consistent nonlocking read)還是DML(INSERT/UPDATE/DELETE)或鎖定讀(locking read)
3、SQL執行時是否使用了索引,所使用索引的型別(主鍵索引,輔助索引、唯一索引)
我們先分別介紹這幾個因素
一、隔離級別(isolation level)
資料庫事務需要滿足ACID原則,“I”即隔離性,它要求兩個事務互不影響,不能看到對方尚未提交的資料。資料庫有4種隔離級別(isolation level),按著隔離性從弱到強(相應的,效能和併發性從強到弱)分別是
1、Read Uncommitted。下麵簡稱RU
2、Read Committed。下麵簡稱RC
3、Repeatable Read(MySQL的預設隔離級別)。下麵簡稱RR
4、Serializable
“I”即隔離性正是透過鎖機制來實現的。提到鎖就會涉及到死鎖,需要明確的是死鎖的可能性並不受隔離級別的影響,因為隔離級別改變的是讀操作的行為,而死鎖是由於寫操作產生的。
— 檢視事務的 全域性和session 隔離級別( MySQL 5.7.19及之前使用tx_isolation)
select @@global.transaction_isolation, @@session.transaction_isolation;
— 設定 全域性 事務隔離級別為repeatable read
set global transaction isolation level repeatable read
— 設定 當前session 事務隔離級別為read uncommitted
set session transaction isolation level read uncommitted
事務隔離級別設定和檢視的詳細語法請見:
https://dev.mysql.com/doc/refman/8.0/en/set-transaction.html
二、一致性非鎖定讀和鎖定讀
InnoDB有兩種不同的SELECT,即普通SELECT 和 鎖定讀SELECT。鎖定讀SELECT 又有兩種,即SELECT … FOR SHARE 和 SELECT … FOR UPDATE;鎖定讀SELECT 之外的則是 普通SELECT 。
不同的SELECT是否都需要加鎖呢?
1、普通SELECT 時使用一致性非鎖定讀,不加鎖;
2、鎖定讀SELECT 使用鎖定讀,加鎖;
3、此外,DML(INSERT/UPDATE/DELETE)時,需要先查詢表中的記錄,此時也使用鎖定讀,加鎖;
FOR SHARE 語法是 MySQL 8.0 時加入的,FOR SHARE 和 LOCK IN SHARE MODE 是等價的,但,FOR SHARE 用於替代 LOCK IN SHARE MODE,不過,為了向後相容,LOCK IN SHARE MODE依然可用。
1、一致性非鎖定讀(consistent nonlocking read)
InnoDB採用多版本併發控制(MVCC, multiversion concurrency control)來增加讀操作的併發性。MVCC是指,InnoDB使用基於時間點的快照來獲取查詢結果,讀取時在訪問的表上不設定任何鎖,因此,在事務T1讀取的同一時刻,事務T2可以自由的修改事務T1所讀取的資料。這種讀操作被稱為一致性非鎖定讀。這裡的讀操作就是普通SELECT。
隔離級別為RU和Serializable時不需要MVCC,因此,只有RC和RR時,才存在MVCC,才存在一致性非鎖定讀。
一致性非鎖定讀在兩種隔離級別RC和RR時,是否有什麼不同呢?是的,兩種隔離級別下,拍得快照的時間點不同
1、RC時,同一個事務內的每一個一致性讀總是設定和讀取它自己的最新快照。也就是說,每次讀取時,都再重新拍得一個最新的快照(所以,RC時總是可以讀取到最新提交的資料)。
2、RR時,同一個事務內的所有的一致性讀 總是讀取同一個快照,此快照是執行該事務的第一個一致性讀時所拍得的。
2、鎖定讀(locking read)
如果你先查詢資料,然後,在同一個事務內 插入/更新 相關資料,普通的SELECT陳述句是不能給你足夠的保護的。其他事務可以 更新/刪除 你剛剛查出的資料行。InnoDB提供兩種鎖定讀,即:SELECT … FOR SHARE 和 SELECT … FOR UPDATE。它倆都能提供額外的安全性。
這兩種鎖定讀在搜尋時所遇到的(註意:不是最終結果集中的)每一條索引記錄(index record)上設定排它鎖或共享鎖。此外,如果當前隔離級別是RR,它還會在每個索引記錄前面的間隙上設定排它的或共享的gap lock(排它的和共享的gap lock沒有任何區別,二者等價)。
看完背景介紹,我們再來看一下InnoDB提供的各種鎖。
三、InnoDB提供的8種不同型別的鎖
InnoDB一共有8種鎖型別,其中,意向鎖(Intention Locks)和自增鎖(AUTO-INC Locks)是表級鎖,剩餘全部都是行級鎖。此外,共享鎖或排它鎖(Shared and Exclusive Locks)儘管也作為8種鎖型別之一,它卻並不是具體的鎖,它是鎖的樣式,用來“修飾”其他各種型別的鎖。
MySQL5.7及之前,可以透過information_schema.innodb_locks檢視事務的鎖情況,但,只能看到阻塞事務的鎖;如果事務並未被阻塞,則在該表中看不到該事務的鎖情況。
MySQL8.0刪除了information_schema.innodb_locks,添加了performance_schema.data_locks,可以透過performance_schema.data_locks檢視事務的鎖情況,和MySQL5.7及之前不同,performance_schema.data_locks不但可以看到阻塞該事務的鎖,還可以看到該事務所持有的鎖,也就是說即使事務並未被阻塞,依然可以看到事務所持有的鎖(不過,正如文中最後一段所說,performance_schema.data_locks並不總是能看到全部的鎖)。表名的變化其實還反映了8.0的performance_schema.data_locks更為通用了,即使你使用InnoDB之外的儲存引擎,你依然可以從performance_schema.data_locks看到事務的鎖情況。
performance_schema.data_locks的列LOCK_MODE表明瞭鎖的型別,下麵在介紹各種鎖時,我們同時指出鎖的LOCK_MODE。
1、共享鎖或排它鎖(Shared and Exclusive Locks)
它並不是一種鎖的型別,而是其他各種鎖的樣式,每種鎖都有shard或exclusive兩種樣式。
當我們說到共享鎖(S鎖)或排它鎖(X鎖)時,一般是指行上的共享鎖或者行上的排它鎖。需要註意的是,表鎖也存在共享鎖和排它鎖,即表上的S鎖和表上的X鎖,表上的鎖除了這兩種之外,還包括下麵將會提到的意向共享鎖(Shard Intention Locks)即IS鎖、意向排它鎖(Exclusive Intention Locks)即IX鎖。表上的鎖,除了這四種之外,還有其他型別的鎖,這些鎖都是在訪問表的元資訊時會用到的(create table/alter table/drop table等),本文不討論這些鎖,詳細可見:常用SQL陳述句的MDL加鎖原始碼分析。
資料行r上共享鎖(S鎖)和排它鎖(X鎖)的相容性如下:
假設T1持有資料行r上的S鎖,則當T2請求r上的鎖時:
1、T2請求r上的S鎖,則,T2立即獲得S鎖。T1和T2同時都持有r上的S鎖。
2、T2請求r上的X鎖,則,T2無法獲得X鎖。T2必須要等待直到T1釋放r上的S鎖。
假設T1持有r上的X鎖,則當T2請求r上的鎖時:
T2請求r上的任何型別的鎖時,T2都無法獲得鎖,此時,T2必須要等待直到T1釋放r上的X鎖
2、意向鎖(Intention Locks)
表鎖。含義是已經持有了表鎖,稍候將獲取該表上某個/些行的行鎖。有shard或exclusive兩種樣式。
LOCK_MODE分別是:IS或IX。
意向鎖用來鎖定層級資料結構,獲取子層級的鎖之前,必須先獲取到父層級的鎖。可以這麼看InnoB的層級結構:InnoDB所有資料是schema的集合,schema是表的集合,表是行的集合。意向鎖就是獲取子層級(資料行)的鎖之前,需要首先獲取到父層級(表)的鎖。
意向鎖的目的是告知其他事務,某事務已經鎖定了或即將鎖定某個/些資料行。事務在獲取行鎖之前,首先要獲取到意向鎖,即:
1、事務在獲取行上的S鎖之前,事務必須首先獲取 表上的 IS鎖或表上的更強的鎖。
2、事務在獲取行上的X鎖之前,事務必須首先獲取 表上的 IX鎖。
事務請求鎖時,如果所請求的鎖 與 已存在的鎖相容,則該事務 可以成功獲得 所請求的鎖;如果所請求的鎖 與 已存在的鎖衝突,則該事務 無法獲得 所請求的鎖。
表級鎖(table-level lock)的相容性矩陣如下:

對於上面的相容性矩陣,一定註意兩點:
1、在上面的相容性矩陣中,S是表的(不是行的)共享鎖,X是表的(不是行的)排它鎖。
2、意向鎖IS和IX 和任何行鎖 都相容(即:和行的X鎖或行的S鎖都相容)。
所以,意向鎖只會阻塞 全表請求(例如:LOCK TABLES … WRITE),不會阻塞其他任何東西。因為LOCK TABLES … WRITE需要設定X表鎖,這會被意向鎖IS或IX所阻塞。
InnoDB允許表鎖和行鎖共存,使用意向鎖來支援多粒度鎖(multiple granularity locking)。意向鎖如何支援多粒度鎖呢,我們舉例如下
T1: SELECT * FROM t1 WHERE i=1 FOR UPDATE;
T2: LOCK TABLE t1 WRITE;
T1執行時,需要獲取i=1的行的X鎖,但,T1獲取行鎖前,T1必須先要獲取t1表的IX鎖,不存在衝突,於是T1成功獲得了t1表的IX鎖,然後,又成功獲得了i=1的行的X鎖;T2執行時,需要獲取t1表的X鎖,但,T2發現,t1表上已經被設定了IX鎖,因此,T2被阻塞(因為表的X鎖和表的IX鎖不相容)。
假設不存在意向鎖,則:
T1執行時,需要獲取i=1的行的X鎖(不需要獲取t1表的意向鎖了);T2執行時,需要獲取t1表的X鎖,T2能否獲取到T1表的X鎖呢?T2無法立即知道,T2不得不遍歷表t1的每一個資料行以檢查,是否某個行上已存在的鎖和自己即將設定的t1表的X鎖衝突,這種的判斷方法效率實在不高,因為需要遍歷整個表。
所以,使用意向鎖,實現了“表鎖是否衝突”的快速判斷。意向鎖就是協調行鎖和表鎖之間的關係的,或者也可以說,意向鎖是協調表上面的讀寫鎖和行上面的讀寫鎖(也就是不同粒度的鎖)之間的關係的。
3、索引記錄鎖(Record Locks)
也就是所謂的行鎖,鎖定的是索引記錄。行鎖就是索引記錄鎖,所謂的“鎖定某個行”或“在某個行上設定鎖”,其實就是在某個索引的特定索引記錄(或稱索引條目、索引項、索引入口)上設定鎖。有shard或exclusive兩種樣式。
LOCK_MODE分別是:S,REC_NOT_GAP或X,REC_NOT_GAP。
行鎖就是索引記錄鎖,索引記錄鎖總是鎖定索引記錄,即使表上並未定義索引。表未定義索引時,InnoDB自動建立隱藏的聚集索引(索引名字是GEN_CLUST_INDEX),使用該索引執行record lock。
4、間隙鎖(Gap Locks)
索引記錄之間的間隙上的鎖,鎖定尚未存在的記錄,即索引記錄之間的間隙。有shard或exclusive兩種樣式,但,兩種樣式沒有任何區別,二者等價。
LOCK_MODE分別是:S,GAP或X,GAP。
gap lock可以共存(co-exist)。事務T1持有某個間隙上的gap lock 並不能阻止 事務T2同時持有 同一個間隙上的gap lock。shared gap lock和exclusive gap lock並沒有任何的不同,它倆並不衝突,它倆執行同樣的功能。
gap lock鎖住的間隙可以是第一個索引記錄前面的間隙,或相鄰兩條索引記錄之間的間隙,或最後一個索引記錄後面的間隙。
索引是B+樹組織的,因此索引是從小到大按序排列的,在索引記錄上查詢給定記錄時,InnoDB會在第一個不滿足查詢條件的記錄上加gap lock,防止新的滿足條件的記錄插入。

上圖演示了:InnoDB在索引上掃描時,找到了c2=11的記錄,然後,InnoDB接著掃描,它發現下一條記錄是c2=18,不滿足條件,InnoDB遇到了第一個不滿足查詢條件的記錄18,於是InnoDB在18上設定gap lock,此gap lock鎖定了區間(11, 18)。
為什麼需要gap lock呢?gap lock存在的唯一目的就是阻止其他事務向gap中插入資料行,它用於在隔離級別為RR時,阻止幻影行(phantom row)的產生;隔離級別為RC時,搜尋和索引掃描時,gap lock是被禁用的,只在 外來鍵約束檢查 和 重覆key檢查時gap lock才有效,正是因為此,RC時會有幻影行問題。
gap lock是如何阻止其他事務向gap中插入資料行的呢?看下圖

索引是B+樹組織的,因此索引是從小到大按序排列的,如果要插入10,那麼能插入的位置只能是上圖中標紅的區間。在10和10之間插入時,我們就認為是插入在最後面的10的後面。如果封鎖了標紅的區間,那麼其他事務就無法再插入10啦。
問題一:當T2要插入 10時,上圖哪些地方允許插入(註意:索引是有序的哦)?
答:(8, 10)和(10,11)。在10和10之間插入,我們就認為是插入在最後的10後面。
只要封鎖住圖中標紅的區間,T2就無法再插入10啦。上面這兩個區間有什麼特點嗎?對,這兩個區間就是:滿足條件的每一條記錄前面的間隙,及,最後一條不滿足條件的記錄前面的間隙。InnoDB使用下一個鍵鎖(Next-Key Locks)或間隙鎖(Gap Locks)來封鎖這種區間。
問題二:gap lock是用來阻塞插入新資料行的,那麼,T2, insert into g values(‘z’, 9) 會被阻塞嗎?插入(‘z’, 8),(‘z’, 10),(‘z’, 11)呢?
答:上圖中,T1的update設定的gap lock是 (8, 10)和(10,11),而,insert intention lock的範圍是(插入值, 向下的一個索引值)。insert intention lock的詳細介紹請見下麵的6. 插入意向鎖(Insert Intention Locks)。
於是,對於上面這些插入值,得到的insert intention lock如下:
插入 (‘z’, 8)時,insert intention lock 是 (8, 10) — 衝突,與gap lock (8, 10)重疊了
插入 (‘z’, 9)時,insert intention lock 是 (9, 10) — 衝突,與gap lock (8, 10)重疊了
插入 (‘z’, 10)時,insert intention lock 是 (10, 11) — 衝突,與gap lock (10, 11)重疊了
插入 (‘z’, 11)時,insert intention lock 是 (11, 15) — 不衝突
事實是不是這樣呢,看下圖
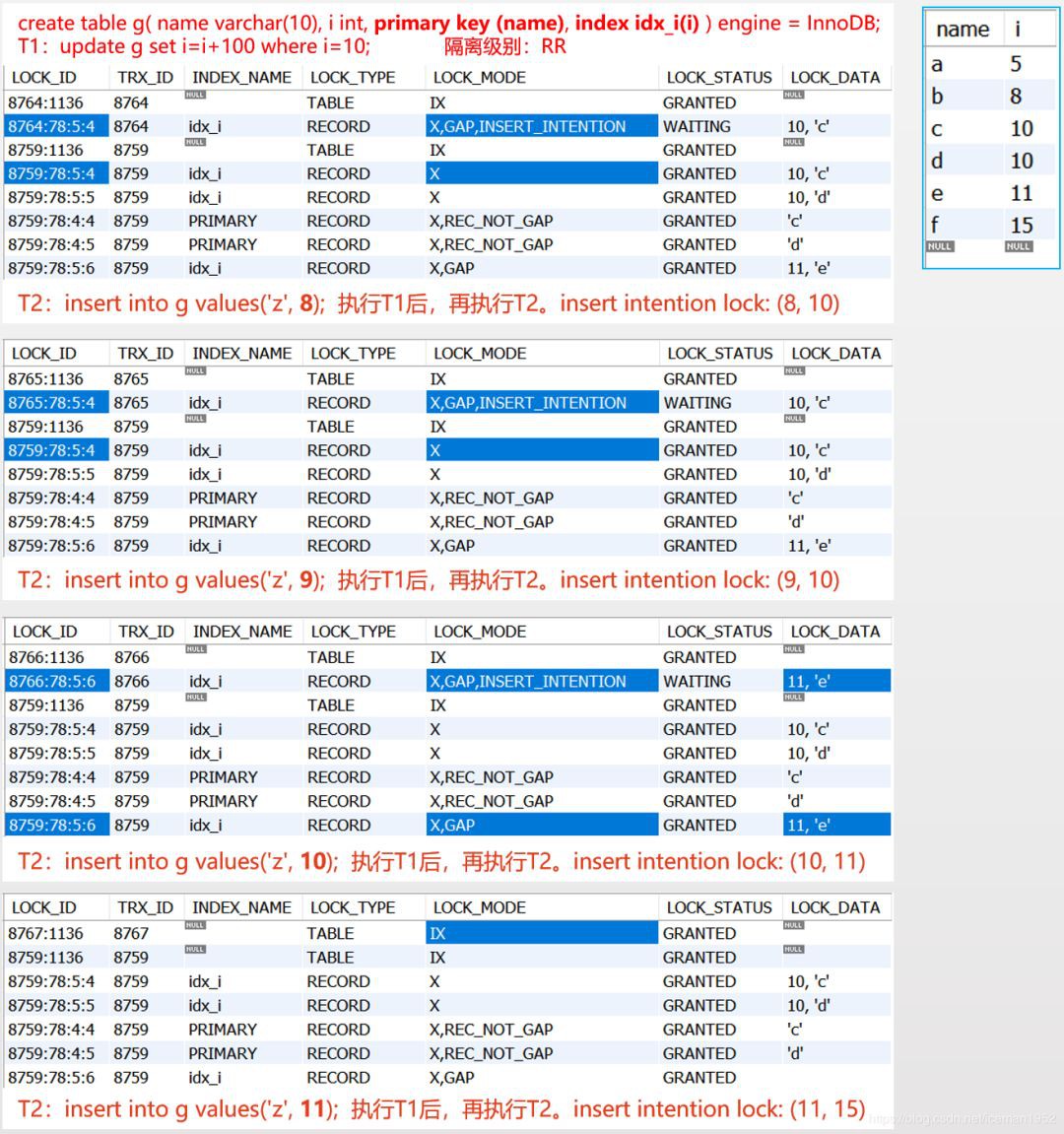
是的,和我們分析的一致,為了看的更清楚,我們把結果列成圖表如下

問題三:“gap是解決phantom row問題的”,插入會導致phantom row,但更新也一樣也會產生phantom row啊。
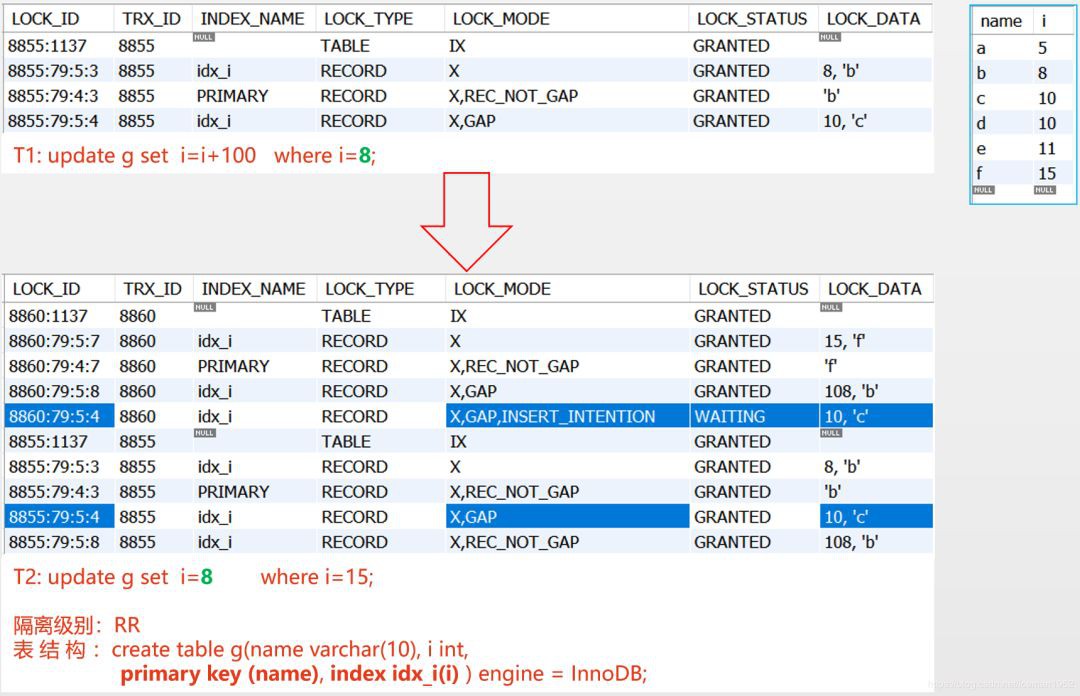
例如,上圖的T1和T2,T1把所有i=8的行更新為108,T2把i=15的行更新為8,如果T2不被阻塞,T1的WHERE條件豈不是多出了一行,即:T1出現了phantom row?
答:nice question。我們自己來分析下T1和T2分別加了哪些鎖
T1加的鎖:idx_i上的next-key lock (5, 8],PRIMARY上的’b’,以及idx_i上的gap lock (8,10)
T2加的鎖:idx_i上的next-key lock (11, 15],PRIMARY上的’f’,以及idx_i上的gap lock (15,108),最後這個gap lock是因為T1在idx_i上加了新值108
根據上面的分析,T1和T2的鎖並沒有重疊,即我們分析的結果是:T2不會被阻塞。
但,上圖清楚的表明T2確實被阻塞了,原因竟然是:T2 insert intention lock和T1 gap lock(8, 10)衝突了。很奇怪,T2是更新陳述句,為什麼會有insert intention lock呢?
我不知道確切的原因,因為我沒找到檔案說這事。根據我的推斷,update … set 成功找到結果集然後執行更新時,在即將被更新進入行的新值上設定了insert intention lock(如果找不到結果集,則就不存在insert intention lock啦),因此,T2在idx_i上的新值8上設定了insert intention lock(8, 10)。最終,T2 insert intention lock(8, 10) 與 T1 gap lock(8, 10)衝突啦,T2被阻塞。
因此,update … set 成功找到結果集時,會在即將被更新進入行的新值上設定 index record lock 以及 insert intention lock。如前所述,insert intention lock的範圍是(插入值,下一個值),如果T2是 update g set i=9 where i=15; 那麼update … set 所設定的新值是9,則T2 insert intention lock就是(9, 10)啦,它依然會和 T1 gap lock(8, 10)衝突,是這樣嗎?確實是的,感興趣的同學可以試試。
5、下一個鍵鎖(Next-Key Locks)
next-key lock 是 (索引記錄上的索引記錄鎖) + (該索引記錄前面的間隙上的鎖) 二者的合體,它鎖定索引記錄以及該索引記錄前面的間隙。有shard或exclusive兩種樣式。
LOCK_MODE分別是:S或X。
當InnoDB 搜尋或掃描索引時,InnoDB在它遇到的索引記錄上所設定的鎖就是next-key lock,它會鎖定索引記錄本身以及該索引記錄前面的gap(“gap” immediately before that index record)。即:如果事務T1 在索引記錄r 上有一個next-key lock,則T2無法在 緊靠著r 前面的那個間隙中 插入新的索引記錄(gap immediately before r in the index order)。
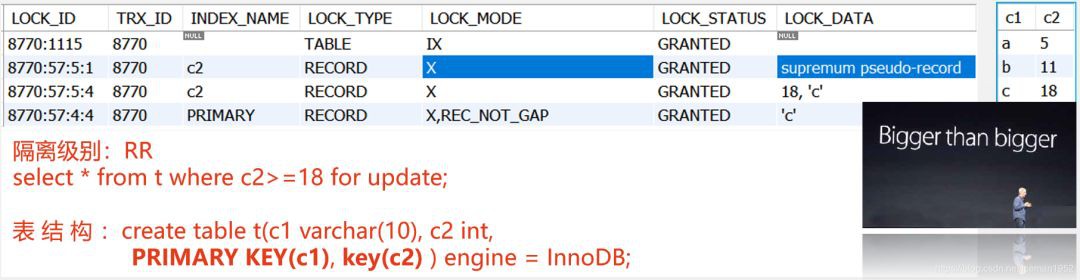
next-key lock還會加在“supremum pseudo-record”上,什麼是supremum pseudo-record呢?它是索引中的偽記錄(pseudo-record),代表此索引中可能存在的最大值,設定在supremum pseudo-record上的next-key lock鎖定了“此索引中可能存在的最大值”,以及 這個值前面的間隙,“此索引中可能存在的最大值”在索引中是不存在的,因此,該next-key lock實際上鎖定了“此索引中可能存在的最大值”前面的間隙,也就是此索引中當前實際存在的最大值後面的間隙。例如,下圖中,supremum pseudo-record上的next-key lock鎖定了區間(18, 正無窮),正是此next-key lock阻止其他事務插入例如19, 100等更大的值。
supremum pseudo-record上的next-key lock鎖定了“比索引中當前實際存在的最大值還要大”的那個間隙,“比大還大”,“bigger than bigger”
6、插入意向鎖(Insert Intention Locks)
一種特殊的gap lock。INSERT操作插入成功後,會在新插入的行上設定index record lock,但,在插入行之前,INSERT操作會首先在索引記錄之間的間隙上設定insert intention lock,該鎖的範圍是(插入值, 向下的一個索引值)。有shard或exclusive兩種樣式,但,兩種樣式沒有任何區別,二者等價。
LOCK_MODE分別是:S,GAP,INSERT_INTENTION或X,GAP,INSERT_INTENTION。
insert intention lock發出按此方式進行插入的意圖:多個事務向同一個index gap併發進行插入時,多個事務無需相互等待。
假設已存在值為4和7的索引記錄,事務T1和T2各自嘗試插入索引值5和6,在得到被插入行上的index record lock前,倆事務都首先設定insert intention lock,於是,T1 insert intention lock (5, 7),T2 insert intention lock (6, 7),儘管這兩個insert intention lock重疊了,T1和T2並不互相阻塞。
如果gap lock或next-key lock 與 insert intention lock 的範圍重疊了,則gap lock或next-key lock會阻塞insert intention lock。隔離級別為RR時正是利用此特性來解決phantom row問題;儘管insert intention lock也是一種特殊的gap lock,但它和普通的gap lock不同,insert intention lock相互不會阻塞,這極大的提供了插入時的併發性。總結如下:
1、gap lock會阻塞insert intention lock。事實上,gap lock的存在只是為了阻塞insert intention lock
2、gap lock相互不會阻塞
3、insert intention lock相互不會阻塞
4、insert intention lock也不會阻塞gap lock
INSERT插入行之前,首先在索引記錄之間的間隙上設定insert intention lock,操作插入成功後,會在新插入的行上設定index record lock。
我們用下麵三圖來說明insert intention lock的範圍和特性

上圖演示了:T1設定了gap lock(13, 18),T2設定了insert intention lock(16, 18),兩個鎖的範圍重疊了,於是T1 gap lock(13, 18)阻塞了T2 insert intention lock(16, 18)。

上圖演示了:T1設定了insert intention lock(13, 18)、index record lock 13;T2設定了gap lock(17, 18)。儘管T1 insert intention lock(13, 18) 和 T2 gap lock(17, 18)重疊了,但,T2並未被阻塞。因為 insert intention lock 並不阻塞 gap lock。

上圖演示了:T1設定了insert intention lock(11, 18)、index record lock 11;T2設定了next-key lock(5, 11]、PRIMARY上的index record lock ‘b’、gap lock(11, 18)。此時:T1 index record lock 11 和 T2 next-key lock(5, 11]衝突了,因此,T2被阻塞。
7、自增鎖(AUTO-INC Locks)
表鎖。向帶有AUTO_INCREMENT列 的表時插入資料行時,事務需要首先獲取到該表的AUTO-INC表級鎖,以便可以生成連續的自增值。插入陳述句開始時請求該鎖,插入陳述句結束後釋放該鎖(註意:是陳述句結束後,而不是事務結束後)。
你可能會想,日常開發中,我們所有表都使用AUTO_INCREMENT作主鍵,所以會非常頻繁的使用到該鎖。不過,事情可能並不像你想的那樣。在介紹AUTO-INC表級鎖之前,我們先來看下和它密切相關的SQL陳述句以及系統變數innodb_autoinc_lock_mode
INSERT-like陳述句
1、insert
2、insert … select
3、replace
4、replace … select
5、load data
外加,simple-inserts, bulk-inserts, mixed-mode-inserts
simple-inserts
待插入記錄的條數,提前就可以確定(陳述句初始被處理時就可以提前確定)因此所需要的自增值的個數也就可以提前被確定。
包括:不帶嵌入子查詢的 單行或多行的insert, replace。不過,insert … on duplicate key update不是
bulk-inserts
待插入記錄的條數,不能提前確定,因此所需要的自增值的個數 也就無法提前確定
包括:insert … select, replace … select, load data
在這種情況下,InnoDB只能每次一行的分配自增值。每當一個資料行被處理時,InnoDB為該行AUTO_INCREMENT列分配一個自增值
mixed-mode-inserts
也是simple-inserts陳述句,但是指定了某些(非全部)自增列的值。也就是說,待插入記錄的條數提前能知道,但,指定了部分的自增列的值。
INSERT INTO t1 (c1,c2) VALUES (1,’a’), (NULL,’b’), (5,’c’), (NULL,’d’);
INSERT … ON DUPLICATE KEY UPDATE也是mixed-mode,最壞情況下,它就是INSERT緊跟著一個UPDATE,此時,為AUTO_INCREMENT列所分配的值在UPDATE階段可能用到,也可能用不到。
再看一下系統變數innodb_autoinc_lock_mode,它有三個候選值0,1,和2
8.0.3之前,預設值是1,即“連續性的鎖定樣式(consecutive lock mode)”;8.0.3及之後預設值是2,即“交織性鎖定樣式(interleaved lock mode)”
a. 當innodb_autoinc_lock_mode=0時,INSERT-like陳述句都需要獲取到AUTO-INC表級鎖;
b. 當innodb_autoinc_lock_mode=1時,如果插入行的條數可以提前確定,則無需獲得AUTO-INC表級鎖;如果插入行的條數無法提前確定,則就需要獲取AUTO-INC表級鎖。因此,simple-inserts和mixed-mode inserts都無需AUTO-INC表級鎖,此時,使用輕量級的mutex來互斥獲得自增值;bulk-inserts需要獲取到AUTO-INC表級鎖;
c. 當innodb_autoinc_lock_mode=2時,完全不再使用AUTO-INC表級鎖;
我們生產資料庫版本是5.6.23-72.1,innodb_autoinc_lock_mode=1,而且,我們日常開發中用到大都是simple-inserts,此時根本就不使用AUTO-INC表級鎖,所以,AUTO-INC表級鎖用到的並不多哦。
LOCK_MODE:AUTO-INC表級鎖用到的並不多,且,AUTO-INC鎖是在陳述句結束後被釋放,較難在performance_schema.data_locks中檢視到,因此,沒有進行捕獲。感興趣的同學可以使用INSERT … SELECT捕獲試試。
8、空間索引(Predicate Locks for Spatial Indexes)
我們平時很少用到MySQL的空間索引。所以,本文忽略此型別的鎖
到此為止,MySQL InnoDB 8種型別的鎖我們就介紹完了。我們以一個例子結束8種型別的介紹。

T1先執行,事務ID是8428;T2後執行,事務ID是8429
上圖演示了:
1、任何事務,在鎖定行之前,都需要先加表級鎖intention lock,即:第三行的IX和第一行的IX。
2、idx_c是輔助索引,InnoDB掃描idx_c時遇到了c=222,於是,在idx_c上加了next-key lock,即:第四行的X。next-key lock就是 index record lock+gap lock,於是此next-key lock鎖定了idx_c上值為222的索引記錄,以及222前面的間隙,也就是間隙(22, 222)。
3、idx_c是輔助索引,在主鍵索引之外的任何索引上加index record lock時,都需要在該行的主鍵索引上再加index record lock,於是,又在PRIMARY上添加了index record lock,即:第五行的X,REC_NOT_GAP。
4、InnoDB掃描完c=222後,又掃描到了c=2222,這是idx_c上,第一個不滿足索引掃描條件的索引記錄,於是InnoDB在c=2222上加gap lock,c=2222上的gap lock鎖定的範圍是“idx_c上2222前面的間隙”,這本應該是(222, 2222),但,T1即將在idx_c上插入c=224,於是,c=2222上的gap lock鎖定的範圍是(224, 2222)。即:第六行的X,GAP。
5、InnoDB即將在idx_c上插入c=224,224也是不滿足c=222的,於是InnoDB在c=224上加gap lock,該gap lock鎖定了224前面的間隙,也就是(222, 224),即,第七行的X,GAP。
6、T2執行INSERT成功後,會在新插入行的加index record lock,但,T2在插入之前,首先要作的是得到表級鎖intention lock以及設定表的每個索引的insert intention lock,該鎖的範圍是(插入值, 向下的一個索引值),於是,在設定idx_c上的insert intention lock範圍就是(226, 2222),這個範圍和事務T1第六行gap lock範圍(224, 2222)重疊。於是,事務T2被阻塞了,T2必須等待,直到T1釋放第六行的gap lock。
performance_schema.data_locks表中並不能看到T2的全部鎖,比如,T2也得在iux_b上設定insert intention lock,但,performance_schema.data_locks中並沒有這個鎖。關於performance_schema.data_locks中顯示了哪些鎖,請見本文最後一段。
把這些鎖及其範圍列出來如下圖所示

四、不同的SQL加了什麼樣的鎖?
OK,我們已經瞭解了InnoDB各種不同型別的鎖,那麼,不同SQL陳述句各加了什麼樣的鎖呢
我們用最樸素的想法來思考一下,用鎖作什麼呢?鎖要作的就是達到事務隔離的目的,即:兩個併發執行的事務T1和T2,如果T1正在修改某些行,那麼,T2要併發 讀取/修改/插入 滿足T1查詢條件的行時,T2就必須被阻塞,這是鎖存在的根本原因。index record lock, gap lock, next-key lock都是實現手段,這些手段使得鎖既能達到目的,還能實現最大的併發性。所以,當我們考慮事務T1中的SQL上加了什麼鎖時,就想一下,當T1執行時,如果併發的事務 T2不會觸及到T1的行,則T2無需被阻塞,如果T2的要 讀取/修改/插入 滿足T1條件的行時,T2就得被T1阻塞。而T1阻塞T2的具體實現就是:T1在已存在的行上加index record lock使得T2無法觸碰已存在的行,以及,T1在不存在的行上加gap lock使得T2無法插入新的滿足條件的行。
前面我們說過“加什麼樣的鎖”與以下因素相關
1、當前事務的隔離級別
2、SQL是一致性非鎖定讀(consistent nonlocking read)還是DML或鎖定讀(locking read)
3、SQL執行時是否使用了索引,所使用索引的型別(主鍵索引,輔助索引、唯一索引)
我們來看一下,不同的隔離級別下,使用不同的索引時,分別加什麼鎖。在討論之前,我們先剔除無需討論的情況
首先,普通SELECT 使用一致性非鎖定讀,因此根本不存在鎖。無需討論;
再者,作為開發者,我們幾乎從來不會使用到隔離級別RU和Serializable。這兩個隔離級別無需討論。
於是,剩下的就是 給定鎖定讀SELECT或DML(INSERT/UPDATE/DELETE)陳述句,在不同隔離級別下,使用不同型別的索引時,分別會加什麼樣的鎖?直接給出答案,其加鎖原則如下
一、RR時,如果使用非唯一索引進行搜尋或掃描,則在所掃描的每一個索引記錄上都設定next-key lock。
這裡“所掃描的每一個索引記錄”是指當掃描執行計劃中所使用的索引時,搜尋遇到的每一條記錄。WHERE條件是否排除掉某個資料行並沒有關係,InnoDB並不記得確切的WHERE條件,InnoDB倔強的只認其掃描的索引範圍(index range) 。
你可能覺得InnoDB在設定鎖時蠻不講理,竟然不管WHERE條件排除掉的某些行,這不是大大增加了鎖的範圍了嘛。不過,等我們瞭解了MySQL執行SQL時的流程,這就好理解了。MySQL的執行計劃只會選擇一個索引,使用一個索引來進行掃描,MySQL執行SQL陳述句的流程是,先由InnoDB引擎執行索引掃描,然後,把結果傳回給MySQL伺服器,MySQL伺服器會再對該索引條件之外的其他查詢條件進行求值,從而得到最終結果集,而加鎖時只考慮InnoDB掃描的索引,由MySQL伺服器求值的其他WHERE條件並不考慮。當然,MySQL使用index_merge最佳化時會同時使用多個索引的,不過,這個時候設定鎖時也並不特殊,同樣,對於所用到的每一個索引,InnoDB在所掃描的每一個索引記錄上都設定next-key lock。
加的鎖一般是next-key lock,這種鎖住了索引記錄本身,還鎖住了每一條索引記錄前面的間隙,從而阻止其他事務 向 索引記錄前面緊接著的間隙中插入記錄。
如果在搜尋中使用了輔助索引(secondary index),並且在輔助索引上設定了行鎖,則,InnoDB還會在 相應的 聚集索引 上設定鎖;表未定義聚集索引時,InnoDB自動建立隱藏的聚集索引(索引名字是GEN_CLUST_INDEX),當需要在聚集索引上設定鎖時,就設定到此自動建立的索引上。
二、RR時,如果使用了唯一索引的唯一搜索條件,InnoDB只在滿足條件的索引記錄上設定index record lock,不鎖定索引記錄前面的間隙;如果用唯一索引作範圍搜尋,依然會鎖定每一條被掃描的索引記錄前面的間隙,並且再在聚集索引上設定鎖。
三、RR時,在第一個不滿足搜尋條件的索引記錄上設定gap lock或next-key lock。
一般,等值條件時設定gap lock,範圍條件時設定next-key lock。此gap lock或next-key lock鎖住第一個不滿足搜尋條件的記錄前面的間隙。
四、RR時,INSERT在插入新行之前,必須首先為表上的每個索引設定insert intention lock。
每個insert intention lock的範圍都是(待插入行的某索引列的值, 此索引上從待插入行給定的值向下的第一個索引值)。只有當insert intention lock與某個gap lock或next-key lock衝突時,才能在performance_schema.data_locks看到insert intention lock。
五、RC時,InnoDB只在完全滿足WHERE條件的行上設定index record lock。
六、RC時,禁用了gap lock。
正因為此,RC時不存在gap lock或next-key lock。這是為什麼呢?我們想一想啊,gap lock是用來解決phantom row問題的,gap lock封鎖的區間內不能插入新的行,因為插入時的insert intention lock會和gap lock衝突,從而阻止了新行的插入。但,隔離級別RC是允許phantom row的,因此RC時gap lock是被禁用的。
七、RR或RC時,對於主鍵或唯一索引,當有重覆鍵錯誤(duplicate-key error)時,會在 重覆的索引記錄上 設定 shared next-key lock或shared index record lock。這可能會導致死鎖。
假設T1, T2, T3三個事務,T1已經持有了X鎖,T2和T3發生了重覆鍵錯誤,因此T2和T3都在等待獲取S鎖,這個時候,當T1回滾或提交釋放掉了X鎖,則T2和T3就都獲取到了S鎖,並且,T2和T3都請求X鎖,“T2和T3同時持有S鎖,且都在請求X鎖”,於是死鎖就產生了。
好了,規則都列出來了,是時候實踐一把了。下麵在展示鎖時,我們同時指出了當前所使用的隔離級別,表上的索引以及事務的SQL陳述句。
實踐一:搜尋時無法使用索引,即全表掃描時,InnoDB在表的全部行上都加鎖
上圖演示了:搜尋條件無法使用索引時,InnoDB不得不在表的全部行上都加鎖。所以,索引實在太重要了,查詢時,它能加快查詢速度;更新時,除了快速找到指定行,它還能減少被鎖定行的範圍,提高插入時的併發性。
實踐二:唯一索引和非唯一索引、等值查詢和範圍查詢加鎖的不同
搜尋時使用 唯一索引 作等值查詢時,InnoDB只需要加index record lock;搜尋時使用 唯一索引作範圍查詢時 或 使用非唯一索引作任何查詢時 ,InnoDB需要加next-key lock或gap lock。

示例1演示了:使用非唯一索引 idx_c 搜尋或掃描時,InnoDB要鎖住索引本身,還要鎖住索引記錄前面的間隙,即next-key lock: X 和 gap lock: X,GAP。next-key lock既鎖住索引記錄本身,還鎖住該索引記錄前面的間隙,gap lock只鎖住索引記錄前面的間隙。等值條件時,在最後一個不滿足條件的索引記錄上設定gap lock。
示例2演示了:使用唯一索引 iux_b 的唯一搜索條件,即,使用唯一索引執行等值查詢時,InnoDB只需鎖住索引本身,即index record lock: X, REC_NOT_GAP,並不鎖索引前面的間隙。
示例3演示了:使用唯一索引 iux_b 進行範圍掃描時,依然需要鎖定掃描過的每一個索引記錄,並且鎖住每一條索引記錄前面的間隙,即next-key lock: X。範圍條件時,在最後一個不滿足條件的索引記錄上設定next-key lock。
實踐三:不同隔離級別加鎖的不同
無論何種隔離級別,SQL陳述句執行時,都是先由InnoDB執行索引掃描,然後,傳回結果集給MySQL伺服器,MySQL伺服器再對該索引條件之外的其他查詢條件進行求值,從而得到最終結果集。

上圖中,在不同的隔離級別下,執行了相同的SQL。無論何種隔離級別,PRIMARY上的index record lock總是會加的,我們不討論它。在idx_b上,隔離級別為RC時,InnoDB加了index record lock,即:X,REC_NOT_GAP,隔離級別為RR時,InnoDB加了next-key lock,即X。註意:RC時沒有gap lock或next-key lock哦。
上圖演示了:事務的隔離級別也會影響到設定哪種鎖。如我們前面所說,gap lock是用來阻止phantom row的,而RC時是允許phantom row,所以,RC時禁用了gap lock。因此,上圖中,RC時沒有在索引上設定gap lock或next-key lock。
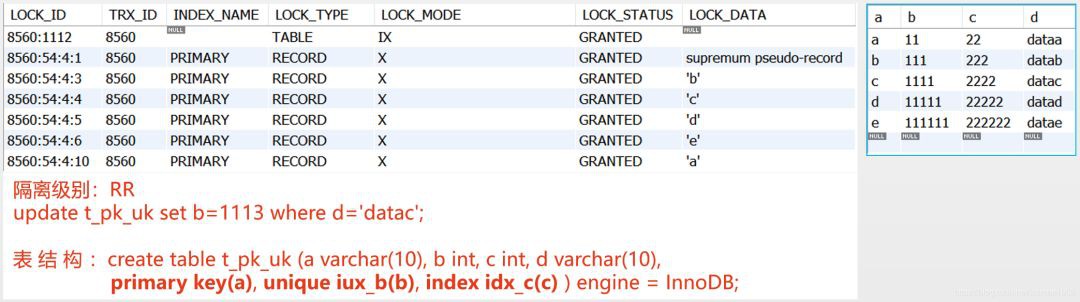
實踐四:操作不存在的索引記錄時,也需要加鎖

上圖中,idx_b上並不存在b=266的索引記錄,那麼,當更新b=266的記錄時,是否需要加鎖呢?是的,也需要加鎖
無論b=266是否存在,RR時,InnoDB在第一個不滿足搜尋條件的索引記錄上設定gap lock或next-key lock。一般,等值條件時設定gap lock,範圍條件時設定next-key lock。上圖中是等值條件,於是InnoDB設定gap lock,即上圖的X,GAP,其範圍是(226, 2222),正是此gap lock使得併發的事務無法插入b列大於等於266的值,RC時,由於gap lock是被禁止的,因此,並不會加gap lock,併發的事務可以插入b列大於等於266的值。
上圖演示了:操作不存在的索引記錄時,也需要加鎖。
實踐五:重覆鍵錯誤(duplicate-key error)時,會加共享鎖。這可能會導致死鎖。
對於主鍵或唯一索引,當有重覆鍵錯誤(duplicate-key error)時,會在 重覆的索引記錄上 設定 shared next-key lock或shared index record lock。這可能會導致死鎖。

上圖演示了:T1在主鍵1上設定exclusive index record lock。T2和T3插入時,會產生重覆鍵錯誤,於是T2和T3都在主鍵1上設定了shared next-key lock。如上圖所示
如果此時,T1 rollback釋放掉其所持有的index record lock,則T2和T3等待獲取的shared next-key lock都成功了,然後,T2和T3爭奪主鍵1上的index record lock,於是T2和T3就死鎖了,因為它倆都持有shard next-key lock,雙方誰都不會放棄已經得到的shared next-key lock,於是,誰都無法得到主鍵1的index record lock。
需要明確的是死鎖的可能性並不受隔離級別的影響,因為隔離級別改變的是讀操作的行為,而死鎖是由於寫操作產生的。死鎖並不可怕,MySQL會選擇一個犧牲者,然後,在系統變數innodb_lock_wait_timeout指定的秒數達到後,自動回滾犧牲者事務;從MySQL5.7開始,新加入了系統變數innodb_deadlock_detect(預設ON),如果開啟此變數,則MySQL不會再等待,一旦探測到死鎖,就立即回滾犧牲者事務。
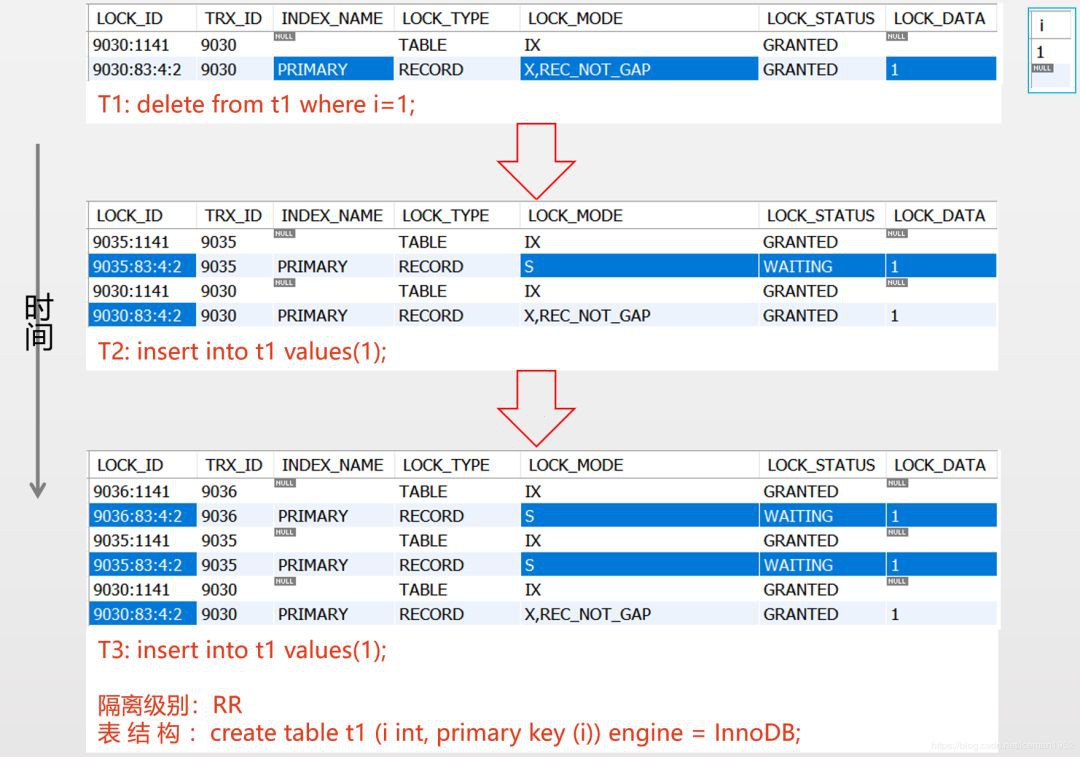
上圖演示了:在上圖的狀態下,當T1 commit時,T1釋放了主鍵1上的index record lock,於是T2和T3等待獲取的shared next-key lock都成功了,然後,T2和T3爭奪主鍵1上的index record lock,於是T2和T3死鎖了,因為它倆都持有shard next-key lock,雙方誰都不會放棄已經得到的shared next-key lock,於是,誰都無法得到主鍵1的index record lock。
五、performance_schema.data_locks中能看到全部的鎖嗎?
顯而易見,performance_schema.data_locks並未顯示全部的鎖,那麼,它顯示了哪些鎖呢?很不幸,我並未找到檔案說這事,儘管檔案(https://dev.mysql.com/doc/refman/8.0/en/innodb-information-schema-transactions.html)說:“事務持有的每一個鎖 以及 事務被阻塞的每一個鎖請求,都在該表中佔據一行”,但,我們很多例子都表明,它並未顯示全部的鎖。根據我的試驗,我猜測performance_schema.data_locks顯示的是WHERE條件所觸碰到的索引上的鎖,“WHERE條件所觸碰到的索引”是指SQL實際執行時所使用的索引,也就是SQL執行計劃的key列所顯示的索引,正因為此,INSERT時看不到任何鎖,update g set a=a+1 where b=22時只看到idx_b上的鎖。需要強調的是,這是我自己試驗並猜測的,我並未在檔案中看到這種說法。
假設T1和T2兩個事務操作同一個表,先執行T1,此時儘管performance_schema.data_locks中只顯示T1的WHERE條件所觸碰到的索引上的鎖,但是,事實上在T1的WHERE條件觸碰不到的索引上,也是會設定鎖的。儘管表的索引idx並未被T1所觸碰到,即performance_schema.data_locks顯示T1在索引idx並沒有設定任何鎖,但,當T2執行 鎖定讀/插入/更新/刪除 時觸碰到了索引idx,T2才恍然發現,原來T1已經在索引idx上加鎖了。
我們來看下麵的三個例子
“performance_schema.data_locks無法看到全部鎖”示例一

上圖演示了:T1執行時,只觸碰到了索引idx_b,T1執行完後,在performance_schema.data_locks中只能看到idx_b上的鎖,看起來T1並未在idx_a上設定任何鎖;但,當T2執行觸碰到了索引idx_a時,T2才恍然發現,原來T1已經在idx_a上設定了index record lock啦。
“performance_schema.data_locks無法看到全部鎖”示例二

插入新行時,會先設定insert intention lock,插入成功後再在插入完成的行上設定index record lock。
上圖演示了:T1插入了新行,但,在performance_schema.data_locks中,我們既看不到T1設定的insert intention lock,也看不到T1設定的index record lock。這是因為T1的WHERE條件並未觸碰到任何索引(T1根本不存在WHERE條件),因此我們看不到T1的這兩個鎖;但,當T2要刪除T1新插入的行時,T2才恍然發現,原來T1已經在索引c2上設定了index record lock啦。
“performance_schema.data_locks無法看到全部鎖”示例三

插入新行時,本來是不會在performance_schema.data_locks中顯示insert intention lock的,因為插入時WHERE條件並未觸碰到任何索引(插入時根本不存在WHERE條件)。
上圖演示了:T2插入新行時的insert intention lock 和 T1的gap lock衝突了,於是,我們得以在performance_schema.data_locks中觀察到T2插入新行時需要請求insert intentin lock。
推薦閱讀 (點選標題可跳轉閱讀)
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」加星標,提升資料技能

喜歡就點一下「好看」唄~

