作者:dannyhoo6688
連結:https://blog.csdn.net/huyuyang6688/article/details/81490570
本文是學習了《深入理解Java虛擬機器》之後的總結,主要內容都來自於書中,也有作者的一些理解。一是為了梳理知識點,歸納總結,二是為了分享交流,如有錯誤之處還望指出。(本文以jdk1.7的規範為基礎)。
文章對JVM記憶體區域分佈、JVM記憶體上限溢位分析、JVM垃圾回收演演算法/垃圾收集器、JVM效能調優工具及技巧、類載入等部分做了詳細描述。
用XMind畫了一張導圖:
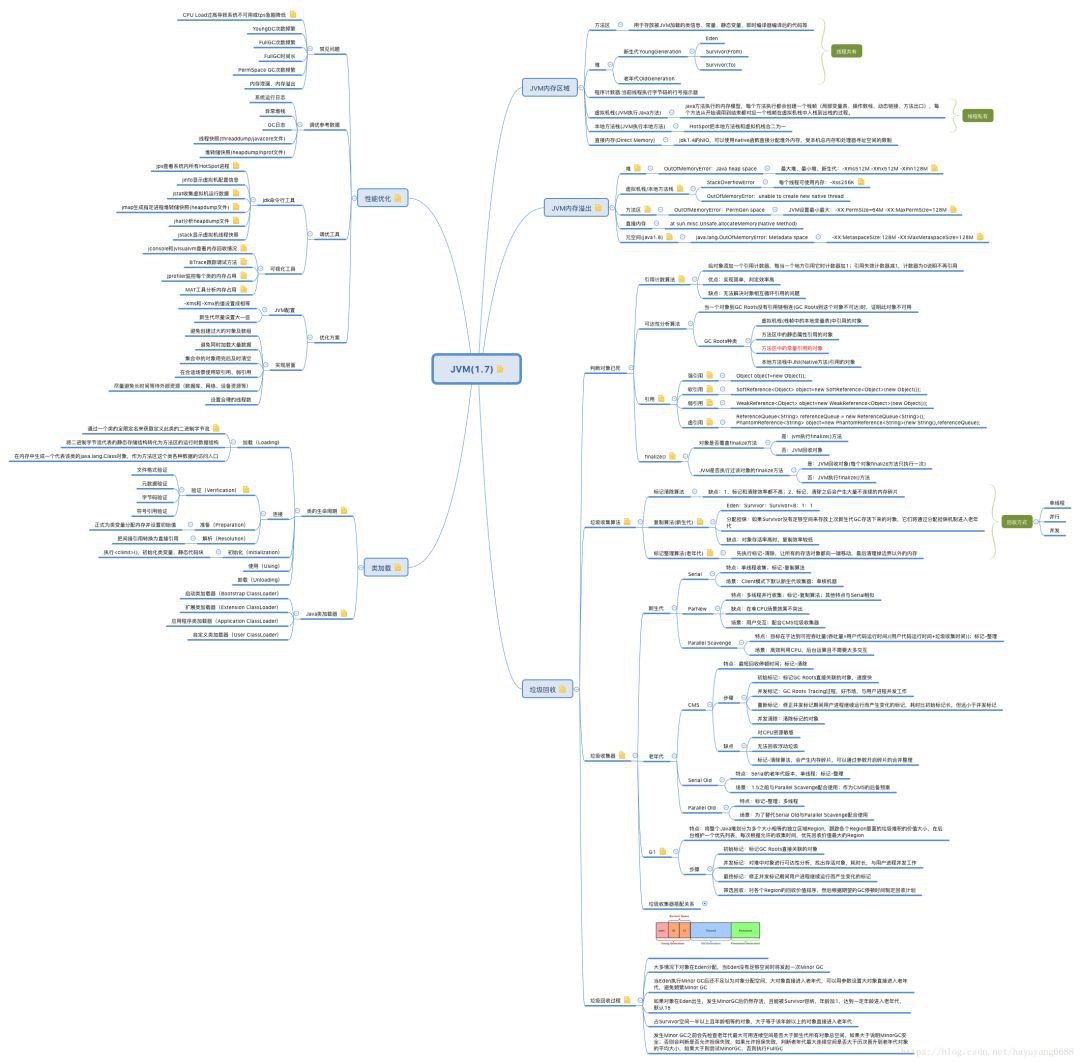
一、JVM記憶體區域
Java虛擬機器在執行時,會把記憶體空間分為若干個區域,根據《Java虛擬機器規範(Java SE 7 版)》的規定,Java虛擬機器所管理的記憶體區域分為如下部分:方法區、堆記憶體、虛擬機器棧、本地方法棧、程式計數器。

1、方法區
方法區主要用於儲存虛擬機器載入的類資訊、常量、靜態變數,以及編譯器編譯後的程式碼等資料。在jdk1.7及其之前,方法區是堆的一個“邏輯部分”(一片連續的堆空間),但為了與堆做區分,方法區還有個名字叫“非堆”,也有人用“永久代”(HotSpot對方法區的實現方法)來表示方法區。
從jdk1.7已經開始準備“去永久代”的規劃,jdk1.7的HotSpot中,已經把原本放在方法區中的靜態變數、字串常量池等移到堆記憶體中,(常量池除字串常量池還有class常量池等),這裡只是把字串常量池移到堆記憶體中;在jdk1.8中,方法區已經不存在,原方法區中儲存的類資訊、編譯後的程式碼資料等已經移動到了元空間(MetaSpace)中,元空間並沒有處於堆記憶體上,而是直接佔用的本地記憶體(NativeMemory)。根據網上的資料結合自己的理解對jdk1.3~1.6、jdk1.7、jdk1.8中方法區的變遷畫了張圖如下(如有不合理的地方希望讀者指出):

去永久代的原因有:
(1)字串存在永久代中,容易出現效能問題和記憶體上限溢位。
(2)類及方法的資訊等比較難確定其大小,因此對於永久代的大小指定比較困難,太小容易出現永久代上限溢位,太大則容易導致老年代上限溢位。
(3)永久代會為 GC 帶來不必要的複雜度,並且回收效率偏低。
2、堆記憶體
堆記憶體主要用於存放物件和陣列,它是JVM管理的記憶體中最大的一塊區域,堆記憶體和方法區都被所有執行緒共享,在虛擬機器啟動時建立。在垃圾收集的層面上來看,由於現在收集器基本上都採用分代收集演演算法,因此堆還可以分為新生代(YoungGeneration)和老年代(OldGeneration),新生代還可以分為Eden、From Survivor、To Survivor。
3、程式計數器
程式計數器是一塊非常小的記憶體空間,可以看做是當前執行緒執行位元組碼的行號指示器,每個執行緒都有一個獨立的程式計數器,因此程式計數器是執行緒私有的一塊空間,此外,程式計數器是Java虛擬機器規定的唯一不會發生記憶體上限溢位的區域。
4、虛擬機器棧
虛擬機器棧也是每個執行緒私有的一塊記憶體空間,它描述的是方法的記憶體模型,直接看下圖所示:
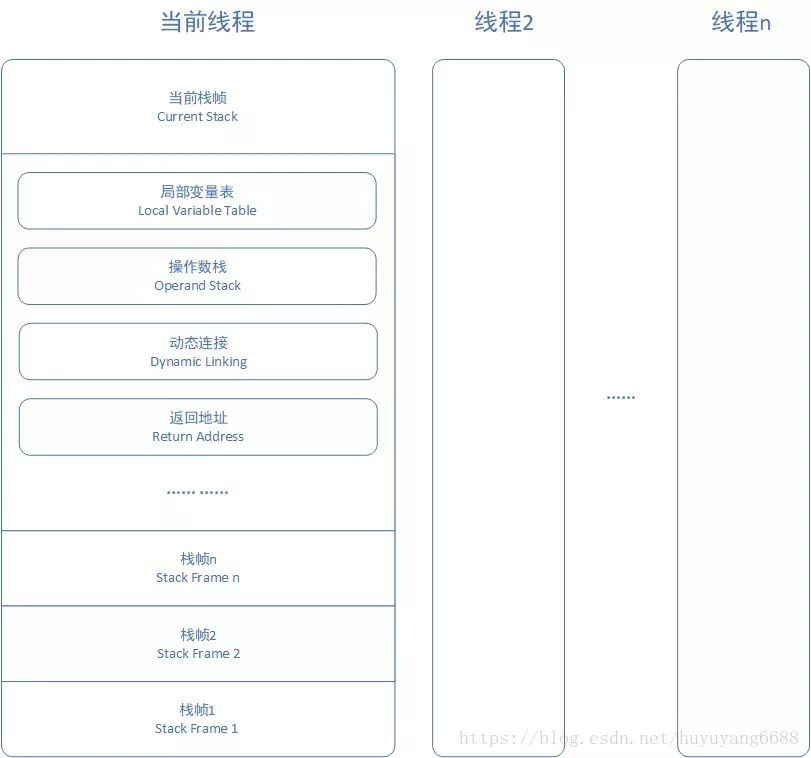
虛擬機器會為每個執行緒分配一個虛擬機器棧,每個虛擬機器棧中都有若干個棧幀,每個棧幀中儲存了區域性變數表、運算元棧、動態連結、傳回地址等。一個棧幀就對應Java程式碼中的一個方法,當執行緒執行到一個方法時,就代表這個方法對應的棧幀已經進入虛擬機器棧並且處於棧頂的位置,每一個Java方法從被呼叫到執行結束,就對應了一個棧幀從入棧到出棧的過程。
5、本地方法棧
本地方法棧與虛擬機器棧的區別是,虛擬機器棧執行的是Java方法,本地方法棧執行的是本地方法(Native Method),其他基本上一致,在HotSpot中直接把本地方法棧和虛擬機器棧合二為一,這裡暫時不做過多敘述。
6、元空間
上面說到,jdk1.8中,已經不存在永久代(方法區),替代它的一塊空間叫做“元空間”,和永久代類似,都是JVM規範對方法區的實現,但是元空間並不在虛擬機器中,而是使用本地記憶體,元空間的大小僅受本地記憶體限制,但可以透過-XX:MetaspaceSize和-XX:MaxMetaspaceSize來指定元空間的大小。
二、JVM記憶體上限溢位
1、堆記憶體上限溢位
堆記憶體中主要存放物件、陣列等,只要不斷地建立這些物件,並且保證GC Roots到物件之間有可達路徑來避免垃圾收集回收機制清除這些物件,當這些物件所佔空間超過最大堆容量時,就會產生OutOfMemoryError的異常。堆記憶體異常示例如下:
/**
* 設定最大堆最小堆:-Xms20m -Xmx20m
* 執行時,不斷在堆中建立OOMObject類的實體物件,且while執行結束之前,GC Roots(程式碼中的oomObjectList)到物件(每一個OOMObject物件)之間有可達路徑,垃圾收集器就無法回收它們,最終導致記憶體上限溢位。
*/
public class HeapOOM {
static class OOMObject {
}
public static void main(String[] args) {
List oomObjectList = new ArrayList<>();
while (true) {
oomObjectList.add(new OOMObject());
}
}
} 執行後會報異常,在堆疊資訊中可以看到 java.lang.OutOfMemoryError: Java heap space 的資訊,說明在堆記憶體空間產生記憶體上限溢位的異常。
新產生的物件最初分配在新生代,新生代滿後會進行一次Minor GC,如果Minor GC後空間不足會把該物件和新生代滿足條件的物件放入老年代,老年代空間不足時會進行Full GC,之後如果空間還不足以存放新物件則丟擲OutOfMemoryError異常。常見原因:記憶體中載入的資料過多如一次從資料庫中取出過多資料;集合對物件取用過多且使用完後沒有清空;程式碼中存在死迴圈或迴圈產生過多重覆物件;堆記憶體分配不合理;網路連線問題、資料庫問題等。
2、虛擬機器棧/本地方法棧上限溢位
(1)StackOverflowError:當執行緒請求的棧的深度大於虛擬機器所允許的最大深度,則丟擲StackOverflowError,簡單理解就是虛擬機器棧中的棧幀數量過多(一個執行緒巢狀呼叫的方法數量過多)時,就會丟擲StackOverflowError異常。最常見的場景就是方法無限遞迴呼叫,如下:
/**
* 設定每個執行緒的棧大小:-Xss256k
* 執行時,不斷呼叫doSomething()方法,main執行緒不斷建立棧幀併入棧,導致棧的深度越來越大,最終導致棧上限溢位。
*/
public class StackSOF {
private int stackLength=1;
public void doSomething(){
stackLength++;
doSomething();
}
public static void main(String[] args) {
StackSOF stackSOF=new StackSOF();
try {
stackSOF.doSomething();
}catch (Throwable e){//註意捕獲的是Throwable
System.out.println("棧深度:"+stackSOF.stackLength);
throw e;
}
}
}上述程式碼執行後丟擲:Exception in thread “Thread-0” java.lang.StackOverflowError的異常。
(2)OutOfMemoryError:如果虛擬機器在擴充套件棧時無法申請到足夠的記憶體空間,則丟擲OutOfMemoryError。我們可以這樣理解,虛擬機器中可以供棧佔用的空間≈可用物理記憶體 – 最大堆記憶體 – 最大方法區記憶體,比如一臺機器記憶體為4G,系統和其他應用佔用2G,虛擬機器可用的物理記憶體為2G,最大堆記憶體為1G,最大方法區記憶體為512M,那可供棧佔有的記憶體大約就是512M,假如我們設定每個執行緒棧的大小為1M,那虛擬機器中最多可以建立512個執行緒,超過512個執行緒再建立就沒有空間可以給棧了,就報OutOfMemoryError異常了。

棧上能夠產生OutOfMemoryError的示例如下:
/**
* 設定每個執行緒的棧大小:-Xss2m
* 執行時,不斷建立新的執行緒(且每個執行緒持續執行),每個執行緒對一個一個棧,最終沒有多餘的空間來為新的執行緒分配,導致OutOfMemoryError
*/
public class StackOOM {
private static int threadNum = 0;
public void doSomething() {
try {
Thread.sleep(100000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
final StackOOM stackOOM = new StackOOM();
try {
while (true) {
threadNum++;
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
stackOOM.doSomething();
}
});
thread.start();
}
} catch (Throwable e) {
System.out.println("目前活動執行緒數量:" + threadNum);
throw e;
}
}
}
上述程式碼執行後會報異常,在堆疊資訊中可以看到 java.lang.OutOfMemoryError: unable to create new native thread的資訊,無法建立新的執行緒,說明是在擴充套件棧的時候產生的記憶體上限溢位異常。
總結:在執行緒較少的時候,某個執行緒請求深度過大,會報StackOverflow異常,解決這種問題可以適當加大棧的深度(增加棧空間大小),也就是把-Xss的值設定大一些,但一般情況下是程式碼問題的可能性較大;在虛擬機器產生執行緒時,無法為該執行緒申請棧空間了,會報OutOfMemoryError異常,解決這種問題可以適當減小棧的深度,也就是把-Xss的值設定小一些,每個執行緒佔用的空間小了,總空間一定就能容納更多的執行緒,但是作業系統對一個行程的執行緒數有限制,經驗值在3000~5000左右。在jdk1.5之前-Xss預設是256k,jdk1.5之後預設是1M,這個選項對系統硬性還是蠻大的,設定時要根據實際情況,謹慎操作。
3、方法區上限溢位
前面說到,方法區主要用於儲存虛擬機器載入的類資訊、常量、靜態變數,以及編譯器編譯後的程式碼等資料,所以方法區上限溢位的原因就是沒有足夠的記憶體來存放這些資料。
由於在jdk1.6之前字串常量池是存在於方法區中的,所以基於jdk1.6之前的虛擬機器,可以透過不斷產生不一致的字串(同時要保證和GC Roots之間保證有可達路徑)來模擬方法區的OutOfMemoryError異常;但方法區還儲存載入的類資訊,所以基於jdk1.7的虛擬機器,可以透過動態不斷建立大量的類來模擬方法區上限溢位。
/**
* 設定方法區最大、最小空間:-XX:PermSize=10m -XX:MaxPermSize=10m
* 執行時,透過cglib不斷建立JavaMethodAreaOOM的子類,方法區中類資訊越來越多,最終沒有可以為新的類分配的記憶體導致記憶體上限溢位
*/
public class JavaMethodAreaOOM {
public static void main(final String[] args){
try {
while (true){
Enhancer enhancer=new Enhancer();
enhancer.setSuperclass(JavaMethodAreaOOM.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
return methodProxy.invokeSuper(o,objects);
}
});
enhancer.create();
}
}catch (Throwable t){
t.printStackTrace();
}
}
}上述程式碼執行後會報“java.lang.OutOfMemoryError: PermGen space”的異常,說明是在方法區出現了記憶體上限溢位的錯誤。
4、本機直接記憶體上限溢位
本機直接記憶體(DirectMemory)並不是虛擬機器執行時資料區的一部分,也不是Java虛擬機器規範中定義的記憶體區域,但Java中用到NIO相關操作時(比如ByteBuffer的allocteDirect方法申請的是本機直接記憶體),也可能會出現記憶體上限溢位的異常。
三、JVM垃圾回收
垃圾回收,就是透過垃圾收集器把記憶體中沒用的物件清理掉。垃圾回收涉及到的內容有:1、判斷物件是否已死;2、選擇垃圾收集演演算法;3、選擇垃圾收集的時間;4、選擇適當的垃圾收集器清理垃圾(已死的物件)。
1、判斷物件是否已死
判斷物件是否已死就是找出哪些物件是已經死掉的,以後不會再用到的,就像地上有廢紙、飲料瓶和百元大鈔,掃地前要先判斷出地上廢紙和飲料瓶是垃圾,百元大鈔不是垃圾。判斷物件是否已死有取用計數演演算法和可達性分析演演算法。
(1)取用計數演演算法
給每一個物件新增一個取用計數器,每當有一個地方取用它時,計數器值加1;每當有一個地方不再取用它時,計數器值減1,這樣只要計數器的值不為0,就說明還有地方取用它,它就不是無用的物件。如下圖,物件2有1個取用,它的取用計數器值為1,物件1有兩個地方取用,它的取用計數器值為2 。
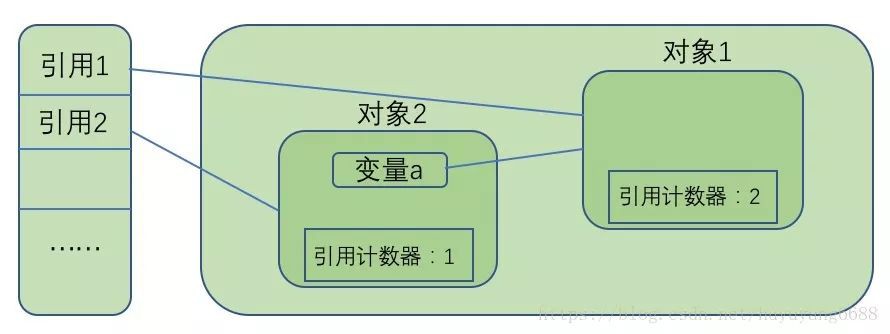
這種方法看起來非常簡單,但目前許多主流的虛擬機器都沒有選用這種演演算法來管理記憶體,原因就是當某些物件之間互相取用時,無法判斷出這些物件是否已死,如下圖,物件1和物件2都沒有被堆外的變數取用,而是被對方互相取用,這時他們雖然沒有用處了,但是取用計數器的值仍然是1,無法判斷他們是死物件,垃圾回收器也就無法回收。

(2)可達性分析演演算法
瞭解可達性分析演演算法之前先瞭解一個概念——GC Roots,垃圾收集的起點,可以作為GC Roots的有虛擬機器棧中本地變數表中取用的物件、方法區中靜態屬性取用的物件、方法區中常量取用的物件、本地方法棧中JNI(Native方法)取用的物件。
當一個物件到GC Roots沒有任何取用鏈相連(GC Roots到這個物件不可達)時,就說明此物件是不可用的,是死物件。如下圖:object1、object2、object3、object4和GC Roots之間有可達路徑,這些物件不會被回收,但object5、object6、object7到GC Roots之間沒有可達路徑,這些物件就被判了死刑。

上面被判了死刑的物件(object5、object6、object7)並不是必死無疑,還有輓救的餘地。進行可達性分析後物件和GC Roots之間沒有取用鏈相連時,物件將會被進行一次標記,接著會判斷如果物件沒有改寫Object的finalize()方法或者finalize()方法已經被虛擬機器呼叫過,那麼它們就會被行刑(清除);如果物件改寫了finalize()方法且還沒有被呼叫,則會執行finalize()方法中的內容,所以在finalize()方法中如果重新與GC Roots取用鏈上的物件關聯就可以拯救自己,但是一般不建議這麼做,周志明老師也建議大家完全可以忘掉這個方法~
(3)方法區回收
上面說的都是對堆記憶體中物件的判斷,方法區中主要回收的是廢棄的常量和無用的類。
判斷常量是否廢棄可以判斷是否有地方取用這個常量,如果沒有取用則為廢棄的常量。
判斷類是否廢棄需要同時滿足如下條件:
-
該類所有的實體已經被回收(堆中不存在任何該類的實體)
-
載入該類的ClassLoader已經被回收
-
該類對應的java.lang.Class物件在任何地方沒有被取用(無法透過反射訪問該類的方法)
2、常用垃圾回收演演算法
常用的垃圾回收演演算法有三種:標記-清除演演算法、複製演演算法、標記-整理演演算法。
(1)標記-清除演演算法:分為標記和清除兩個階段,首先標記出所有需要回收的物件,標記完成後統一回收所有被標記的物件,如下圖。
缺點:標記和清除兩個過程效率都不高;標記清除之後會產生大量不連續的記憶體碎片。

(2)複製演演算法:把記憶體分為大小相等的兩塊,每次儲存只用其中一塊,當這一塊用完了,就把存活的物件全部複製到另一塊上,同時把使用過的這塊記憶體空間全部清理掉,往複迴圈,如下圖。
缺點:實際可使用的記憶體空間縮小為原來的一半,比較適合。
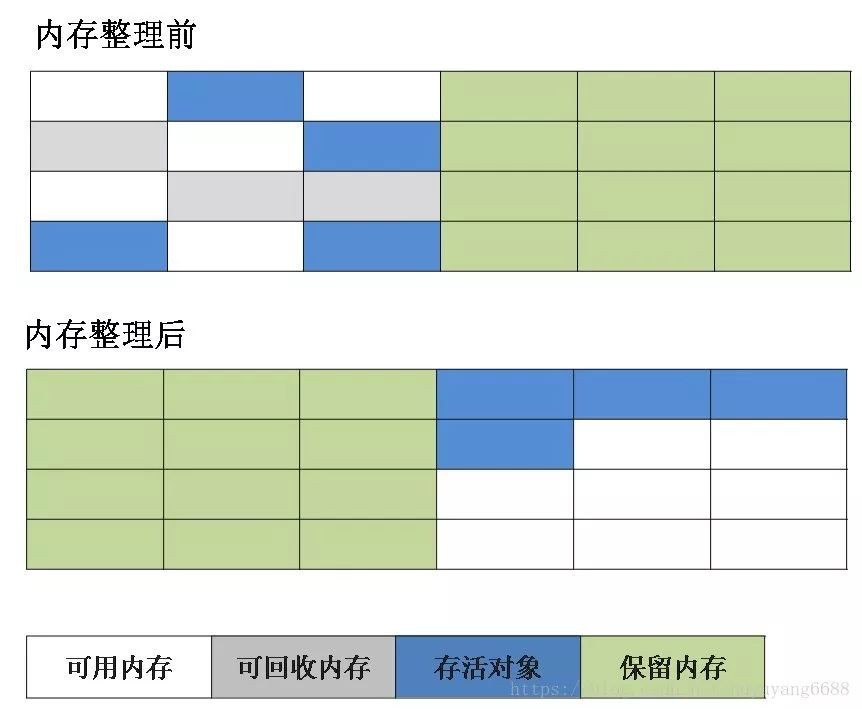
(3)標記-整理演演算法:先對可用的物件進行標記,然後所有被標記的物件向一段移動,最後清除可用物件邊界以外的記憶體,如下圖。

(4)分代收集演演算法:把堆記憶體分為新生代和老年代,新生代又分為Eden區、From Survivor和To Survivor。一般新生代中的物件基本上都是朝生夕滅的,每次只有少量物件存活,因此採用複製演演算法,只需要複製那些少量存活的物件就可以完成垃圾收集;老年代中的物件存活率較高,就採用標記-清除和標記-整理演演算法來進行回收。
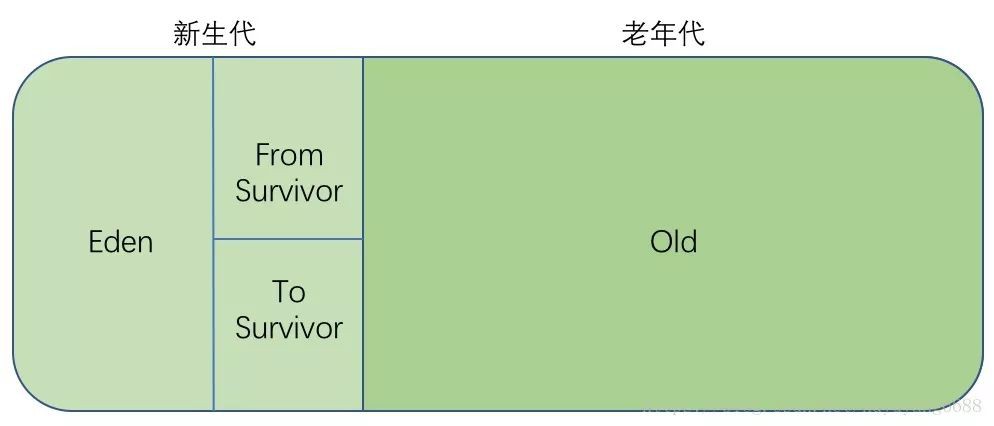
在這些區域的垃圾回收大概有如下幾種情況:
-
大多數情況下,新的物件都分配在Eden區,當Eden區沒有空間進行分配時,將進行一次Minor GC,清理Eden區中的無用物件。清理後,Eden和From Survivor中的存活物件如果小於To Survivor的可用空間則進入To Survivor,否則直接進入老年代);Eden和From Survivor中還存活且能夠進入To Survivor的物件年齡增加1歲(虛擬機器為每個物件定義了一個年齡計數器,每執行一次Minor GC年齡加1),當存活物件的年齡到達一定程度(預設15歲)後進入老年代,可以透過-XX:MaxTenuringThreshold來設定年齡的值。
-
當進行了Minor GC後,Eden還不足以為新物件分配空間(那這個新物件肯定很大),新物件直接進入老年代。
-
佔To Survivor空間一半以上且年齡相等的物件,大於等於該年齡的物件直接進入老年代,比如Survivor空間是10M,有幾個年齡為4的物件佔用總空間已經超過5M,則年齡大於等於4的物件都直接進入老年代,不需要等到MaxTenuringThreshold指定的歲數。
-
在進行Minor GC之前,會判斷老年代最大連續可用空間是否大於新生代所有物件總空間,如果大於,說明Minor GC是安全的,否則會判斷是否允許擔保失敗,如果允許,判斷老年代最大連續可用空間是否大於歷次晉升到老年代的物件的平均大小,如果大於,則執行Minor GC,否則執行Full GC。
-
當在java程式碼裡直接呼叫System.gc()時,會建議JVM進行Full GC,但一般情況下都會觸發Full GC,一般不建議使用,儘量讓虛擬機器自己管理GC的策略。
-
永久代(方法區)中用於存放類資訊,jdk1.6及之前的版本永久代中還儲存常量、靜態變數等,當永久代的空間不足時,也會觸發Full GC,如果經過Full GC還無法滿足永久代存放新資料的需求,就會丟擲永久代的記憶體上限溢位異常。
-
大物件(需要大量連續記憶體的物件)例如很長的陣列,會直接進入老年代,如果老年代沒有足夠的連續大空間來存放,則會進行Full GC。
3、選擇垃圾收集的時間
當程式執行時,各種資料、物件、執行緒、記憶體等都時刻在發生變化,當下達垃圾收集命令後就立刻進行收集嗎?肯定不是。這裡來瞭解兩個概念:安全點(safepoint)和安全區(safe region)。
安全點:從執行緒角度看,安全點可以理解為是在程式碼執行過程中的一些特殊位置,當執行緒執行到安全點的時候,說明虛擬機器當前的狀態是安全的,如果有需要,可以在這裡暫停使用者執行緒。當垃圾收集時,如果需要暫停當前的使用者執行緒,但使用者執行緒當時沒在安全點上,則應該等待這些執行緒執行到安全點再暫停。舉個例子,媽媽在掃地,兒子在吃西瓜(瓜皮會扔到地上),媽媽掃到兒子跟前時,兒子說:“媽媽等一下,讓我吃完這塊再掃。”兒子吃完這塊西瓜把瓜皮扔到地上後就是一個安全點,媽媽可以繼續掃地(垃圾收集器可以繼續收集垃圾)。理論上,直譯器的每條位元組碼的邊界上都可以放一個安全點,實際上,安全點基本上以“是否具有讓程式長時間執行的特徵”為標準進行選定。
安全區:安全點是相對於執行中的執行緒來說的,對於如sleep或blocked等狀態的執行緒,收集器不會等待這些執行緒被分配CPU時間,這時候只要執行緒處於安全區中,就可以算是安全的。安全區就是在一段程式碼片段中,取用關係不會發生變化,可以看作是被擴充套件、拉長了的安全點。還以上面的例子說明,媽媽在掃地,兒子在吃西瓜(瓜皮會扔到地上),媽媽掃到兒子跟前時,兒子說:“媽媽你繼續掃地吧,我還得吃10分鐘呢!”兒子吃瓜的這段時間就是安全區,媽媽可以繼續掃地(垃圾收集器可以繼續收集垃圾)。
4、常見垃圾收集器
現在常見的垃圾收集器有如下幾種
新生代收集器:Serial、ParNew、Parallel Scavenge
老年代收集器:Serial Old、CMS、Parallel Old
堆記憶體垃圾收集器:G1
每種垃圾收集器之間有連線,表示他們可以搭配使用。

(1)Serial 收集器
Serial是一款用於新生代的單執行緒收集器,採用複製演演算法進行垃圾收集。Serial進行垃圾收集時,不僅只用一條執行緒執行垃圾收集工作,它在收集的同時,所有的使用者執行緒必須暫停(Stop The World)。就比如媽媽在家打掃衛生的時候,肯定不會邊打掃邊讓兒子往地上亂扔紙屑,否則一邊製造垃圾,一遍清理垃圾,這活啥時候也乾不完。
如下是Serial收集器和Serial Old收集器結合進行垃圾收集的示意圖,當使用者執行緒都執行到安全點時,所有執行緒暫停執行,Serial收集器以單執行緒,採用複製演演算法進行垃圾收集工作,收集完之後,使用者執行緒繼續開始執行。

適用場景:Client樣式(桌面應用);單核伺服器。可以用-XX:+UserSerialGC來選擇Serial作為新生代收集器。
2)ParNew 收集器
ParNew就是一個Serial的多執行緒版本,其它與Serial並無區別。ParNew在單核CPU環境並不會比Serial收集器達到更好的效果,它預設開啟的收集執行緒數和CPU數量一致,可以透過-XX:ParallelGCThreads來設定垃圾收集的執行緒數。
如下是ParNew收集器和Serial Old收集器結合進行垃圾收集的示意圖,當使用者執行緒都執行到安全點時,所有執行緒暫停執行,ParNew收集器以多執行緒,採用複製演演算法進行垃圾收集工作,收集完之後,使用者執行緒繼續開始執行。

適用場景:多核伺服器;與CMS收集器搭配使用。當使用-XX:+UserConcMarkSweepGC來選擇CMS作為老年代收集器時,新生代收集器預設就是ParNew,也可以用-XX:+UseParNewGC來指定使用ParNew作為新生代收集器。
(3)Parallel Scavenge 收集器
Parallel Scavenge也是一款用於新生代的多執行緒收集器,與ParNew的不同之處是,ParNew的標的是盡可能縮短垃圾收集時使用者執行緒的停頓時間,Parallel Scavenge的標的是達到一個可控制的吞吐量。吞吐量就是CPU執行使用者執行緒的的時間與CPU執行總時間的比值【吞吐量=執行使用者代程式碼時間/(執行使用者程式碼時間+垃圾收集時間)】,比如虛擬機器一共運行了100分鐘,其中垃圾收集花費了1分鐘,那吞吐量就是99% 。比如下麵兩個場景,垃圾收集器每100秒收集一次,每次停頓10秒,和垃圾收集器每50秒收集一次,每次停頓時間7秒,雖然後者每次停頓時間變短了,但是總體吞吐量變低了,CPU總體利用率變低了。
| 收集頻率 | 每次停頓時間 | 吞吐量 |
|---|---|---|
| 每100秒收集一次 | 10秒 | 91% |
| 每50秒收集一次 | 7秒 | 88% |
可以透過-XX:MaxGCPauseMillis來設定收集器盡可能在多長時間內完成記憶體回收,可以透過-XX:GCTimeRatio來精確控制吞吐量。
如下是Parallel收集器和Parallel Old收集器結合進行垃圾收集的示意圖,在新生代,當使用者執行緒都執行到安全點時,所有執行緒暫停執行,ParNew收集器以多執行緒,採用複製演演算法進行垃圾收集工作,收集完之後,使用者執行緒繼續開始執行;在老年代,當使用者執行緒都執行到安全點時,所有執行緒暫停執行,Parallel Old收集器以多執行緒,採用標記整理演演算法進行垃圾收集工作。
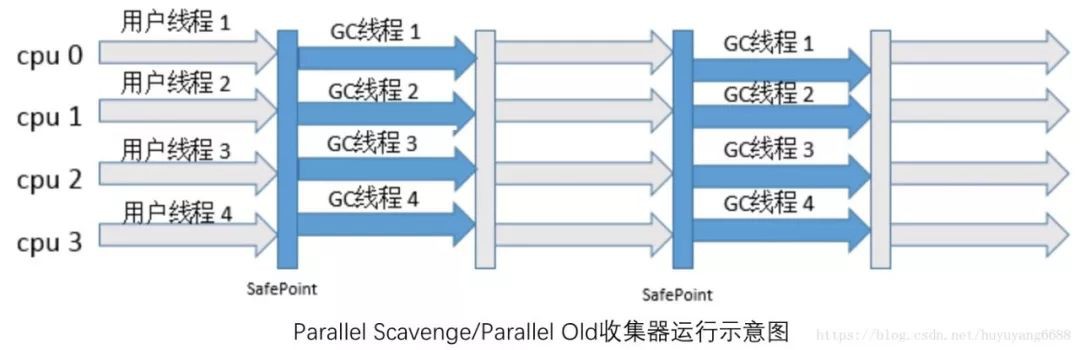
適用場景:註重吞吐量,高效利用CPU,需要高效運算且不需要太多互動。可以使用-XX:+UseParallelGC來選擇Parallel Scavenge作為新生代收集器,jdk7、jdk8預設使用Parallel Scavenge作為新生代收集器。
(4)Serial Old收集器
Serial Old收集器是Serial的老年代版本,同樣是一個單執行緒收集器,採用標記-整理演演算法。
如下圖是Serial收集器和Serial Old收集器結合進行垃圾收集的示意圖:
適用場景:Client樣式(桌面應用);單核伺服器;與Parallel Scavenge收集器搭配;作為CMS收集器的後備預案。
(5)CMS(Concurrent Mark Sweep) 收集器
CMS收集器是一種以最短回收停頓時間為標的的收集器,以“最短使用者執行緒停頓時間”著稱。整個垃圾收集過程分為4個步驟:
① 初始標記:標記一下GC Roots能直接關聯到的物件,速度較快
② 併發標記:進行GC Roots Tracing,標記出全部的垃圾物件,耗時較長
③ 重新標記:修正併發標記階段取使用者程式繼續執行而導致變化的物件的標記記錄,耗時較短
④ 併發清除:用標記-清除演演算法清除垃圾物件,耗時較長
整個過程耗時最長的併發標記和併發清除都是和使用者執行緒一起工作,所以從總體上來說,CMS收集器垃圾收集可以看做是和使用者執行緒併發執行的。

CMS收集器也存在一些缺點:
-
對CPU資源敏感:預設分配的垃圾收集執行緒數為(CPU數+3)/4,隨著CPU數量下降,佔用CPU資源越多,吞吐量越小
-
無法處理浮動垃圾:在併發清理階段,由於使用者執行緒還在執行,還會不斷產生新的垃圾,CMS收集器無法在當次收集中清除這部分垃圾。同時由於在垃圾收集階段使用者執行緒也在併發執行,CMS收集器不能像其他收集器那樣等老年代被填滿時再進行收集,需要預留一部分空間提供使用者執行緒執行使用。當CMS執行時,預留的記憶體空間無法滿足使用者執行緒的需要,就會出現“Concurrent Mode Failure”的錯誤,這時將會啟動後備預案,臨時用Serial Old來重新進行老年代的垃圾收集。
-
因為CMS是基於標記-清除演演算法,所以垃圾回收後會產生空間碎片,可以透過-XX:UserCMSCompactAtFullCollection開啟碎片整理(預設開啟),在CMS進行Full GC之前,會進行記憶體碎片的整理。還可以用-XX:CMSFullGCsBeforeCompaction設定執行多少次不壓縮(不進行碎片整理)的Full GC之後,跟著來一次帶壓縮(碎片整理)的Full GC。
適用場景:重視伺服器響應速度,要求系統停頓時間最短。可以使用-XX:+UserConMarkSweepGC來選擇CMS作為老年代收集器。
(6)Parallel Old 收集器
Parallel Old收集器是Parallel Scavenge的老年代版本,是一個多執行緒收集器,採用標記-整理演演算法。可以與Parallel Scavenge收集器搭配,可以充分利用多核CPU的計算能力。
適用場景:與Parallel Scavenge收集器搭配使用;註重吞吐量。jdk7、jdk8預設使用該收集器作為老年代收集器,使用 -XX:+UseParallelOldGC來指定使用Paralle Old收集器。
(7)G1 收集器
G1 收集器是jdk1.7才正式取用的商用收集器,現在已經成為jdk9預設的收集器。前面幾款收集器收集的範圍都是新生代或者老年代,G1進行垃圾收集的範圍是整個堆記憶體,它採用“化整為零”的思路,把整個堆記憶體劃分為多個大小相等的獨立區域(Region),在G1收集器中還保留著新生代和老年代的概念,它們分別都是一部分Region,如下圖:

每一個方塊就是一個區域,每個區域可能是Eden、Survivor、老年代,每種區域的數量也不一定。JVM啟動時會自動設定每個區域的大小(1M~32M,必須是2的次冪),最多可以設定2048個區域(即支援的最大堆記憶體為32M*2048=64G),假如設定-Xmx8g -Xms8g,則每個區域大小為8g/2048=4M。
為了在GC Roots Tracing的時候避免掃描全堆,在每個Region中,都有一個Remembered Set來實時記錄該區域內的取用型別資料與其他區域資料的取用關係(在前面的幾款分代收集中,新生代、老年代中也有一個Remembered Set來實時記錄與其他區域的取用關係),在標記時直接參考這些取用關係就可以知道這些物件是否應該被清除,而不用掃描全堆的資料。
G1收集器可以“建立可預測的停頓時間模型”,它維護了一個串列用於記錄每個Region回收的價值大小(回收後獲得的空間大小以及回收所需時間的經驗值),這樣可以保證G1收集器在有限的時間內可以獲得最大的回收效率。
如下圖所示,G1收集器收集器收集過程有初始標記、併發標記、最終標記、篩選回收,和CMS收集器前幾步的收集過程很相似:

① 初始標記:標記出GC Roots直接關聯的物件,這個階段速度較快,需要停止使用者執行緒,單執行緒執行
② 併發標記:從GC Root開始對堆中的物件進行可達新分析,找出存活物件,這個階段耗時較長,但可以和使用者執行緒併發執行
③ 最終標記:修正在併發標記階段取使用者程式執行而產生變動的標記記錄
④ 篩選回收:篩選回收階段會對各個Region的回收價值和成本進行排序,根據使用者所期望的GC停頓時間來指定回收計劃(用最少的時間來回收包含垃圾最多的區域,這就是Garbage First的由來——第一時間清理垃圾最多的區塊),這裡為了提高回收效率,並沒有採用和使用者執行緒併發執行的方式,而是停頓使用者執行緒。
適用場景:要求盡可能可控GC停頓時間;記憶體佔用較大的應用。可以用-XX:+UseG1GC使用G1收集器,jdk9預設使用G1收集器。
四、JVM效能調優
1、JVM調優標的:使用較小的記憶體佔用來獲得較高的吞吐量或者較低的延遲。
程式在上線前的測試或執行中有時會出現一些大大小小的JVM問題,比如cpu load過高、請求延遲、tps降低等,甚至出現記憶體洩漏(每次垃圾收集使用的時間越來越長,垃圾收集頻率越來越高,每次垃圾收集清理掉的垃圾資料越來越少)、記憶體上限溢位導致系統崩潰,因此需要對JVM進行調優,使得程式在正常執行的前提下,獲得更高的使用者體驗和執行效率。
這裡有幾個比較重要的指標:
-
記憶體佔用:程式正常執行需要的記憶體大小。
-
延遲:由於垃圾收集而引起的程式停頓時間。
-
吞吐量:使用者程式執行時間佔用戶程式和垃圾收集佔用總時間的比值。
當然,和CAP原則一樣,同時滿足一個程式記憶體佔用小、延遲低、高吞吐量是不可能的,程式的標的不同,調優時所考慮的方向也不同,在調優之前,必須要結合實際場景,有明確的的最佳化標的,找到效能瓶頸,對瓶頸有針對性的最佳化,最後進行測試,透過各種監控工具確認調優後的結果是否符合標的。
2、JVM調優工具
(1)調優可以依賴、參考的資料有系統執行日誌、堆疊錯誤資訊、gc日誌、執行緒快照、堆轉儲快照等。
① 系統執行日誌:系統執行日誌就是在程式程式碼中打印出的日誌,描述了程式碼級別的系統執行軌跡(執行的方法、入參、傳回值等),一般系統出現問題,系統執行日誌是首先要檢視的日誌。
② 堆疊錯誤資訊:當系統出現異常後,可以根據堆疊資訊初步定位問題所在,比如根據“java.lang.OutOfMemoryError: Java heap space”可以判斷是堆記憶體上限溢位;根據“java.lang.StackOverflowError”可以判斷是棧上限溢位;根據“java.lang.OutOfMemoryError: PermGen space”可以判斷是方法區上限溢位等。
③ GC日誌:程式啟動時用 -XX:+PrintGCDetails 和 -Xloggc:/data/jvm/gc.log 可以在程式執行時把gc的詳細過程記錄下來,或者直接配置“-verbose:gc”引數把gc日誌列印到控制檯,透過記錄的gc日誌可以分析每塊記憶體區域gc的頻率、時間等,從而發現問題,進行有針對性的最佳化。
比如如下一段GC日誌:
2018-08-02T14:39:11.560-0800: 10.171: [GC [PSYoungGen: 30128K->4091K(30208K)] 51092K->50790K(98816K), 0.0140970 secs] [Times: user=0.02 sys=0.03, real=0.01 secs]
2018-08-02T14:39:11.574-0800: 10.185: [Full GC [PSYoungGen: 4091K->0K(30208K)] [ParOldGen: 46698K->50669K(68608K)] 50790K->50669K(98816K) [PSPermGen: 2635K->2634K(21504K)], 0.0160030 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
2018-08-02T14:39:14.045-0800: 12.656: [GC [PSYoungGen: 14097K->4064K(30208K)] 64766K->64536K(98816K), 0.0117690 secs] [Times: user=0.02 sys=0.01, real=0.01 secs]
2018-08-02T14:39:14.057-0800: 12.668: [Full GC [PSYoungGen: 4064K->0K(30208K)] [ParOldGen: 60471K->401K(68608K)] 64536K->401K(98816K) [PSPermGen: 2634K->2634K(21504K)], 0.0102020 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]上面一共是4條GC日誌,來看第一行日誌,“2018-08-02T14:39:11.560-0800”是精確到了毫秒級別的UTC 通用標準時間格式,配置了“-XX:+PrintGCDateStamps”這個引數可以跟隨gc日誌打印出這種時間戳,“10.171”是從JVM啟動到發生gc經過的秒數。第一行日誌正文開頭的“[GC”說明這次GC沒有發生Stop-The-World(使用者執行緒停頓),第二行日誌正文開頭的“[Full GC”說明這次GC發生了Stop-The-World,所以說,[GC和[Full GC跟新生代和老年代沒關係,和垃圾收集器的型別有關係,如果直接呼叫System.gc(),將顯示[Full GC(System)。接下來的“[PSYoungGen”、“[ParOldGen”表示GC發生的區域,具體顯示什麼名字也跟垃圾收集器有關,比如這裡的“[PSYoungGen”表示Parallel Scavenge收集器,“[ParOldGen”表示Serial Old收集器,此外,Serial收集器顯示“[DefNew”,ParNew收集器顯示“[ParNew”等。再往後的“30128K->4091K(30208K)”表示進行了這次gc後,該區域的記憶體使用空間由30128K減小到4091K,總記憶體大小為30208K。每個區域gc描述後面的“51092K->50790K(98816K), 0.0140970 secs”進行了這次垃圾收集後,整個堆記憶體的記憶體使用空間由51092K減小到50790K,整個堆記憶體總空間為98816K,gc耗時0.0140970秒。
④ 執行緒快照:顧名思義,根據執行緒快照可以看到執行緒在某一時刻的狀態,當系統中可能存在請求超時、死迴圈、死鎖等情況是,可以根據執行緒快照來進一步確定問題。透過執行虛擬機器自帶的“jstack pid”命令,可以dump出當前行程中執行緒的快照資訊,更詳細的使用和分析網上有很多例,這篇文章寫到這裡已經很長了就不過多敘述了,貼一篇部落格供參考:http://www.cnblogs.com/kongzhongqijing/articles/3630264.html
⑤ 堆轉儲快照:程式啟動時可以使用 “-XX:+HeapDumpOnOutOfMemory” 和 “-XX:HeapDumpPath=/data/jvm/dumpfile.hprof”,當程式發生記憶體上限溢位時,把當時的記憶體快照以檔案形式進行轉儲(也可以直接用jmap命令轉儲程式執行時任意時刻的記憶體快照),事後對當時的記憶體使用情況進行分析。
(2)JVM調優工具
① 用 jps(JVM process Status)可以檢視虛擬機器啟動的所有行程、執行主類的全名、JVM啟動引數,比如當執行了JPSTest類中的main方法後(main方法持續執行),執行 jps -l可看到下麵的JPSTest類的pid為31354,加上-v引數還可以看到JVM啟動引數。
3265
32914 sun.tools.jps.Jps
31353 org.jetbrains.jps.cmdline.Launcher
31354 com.danny.test.code.jvm.JPSTest
380② 用jstat(JVM Statistics Monitoring Tool)監視虛擬機器資訊
jstat -gc pid 500 10 :每500毫秒列印一次Java堆狀況(各個區的容量、使用容量、gc時間等資訊),列印10次
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
11264.0 11264.0 11202.7 0.0 11776.0 1154.3 68608.0 36238.7 - - - - 14 0.077 7 0.049 0.126
11264.0 11264.0 11202.7 0.0 11776.0 4037.0 68608.0 36238.7 - - - - 14 0.077 7 0.049 0.126
11264.0 11264.0 11202.7 0.0 11776.0 6604.5 68608.0 36238.7 - - - - 14 0.077 7 0.049 0.126
11264.0 11264.0 11202.7 0.0 11776.0 9487.2 68608.0 36238.7 - - - - 14 0.077 7 0.049 0.126
11264.0 11264.0 0.0 0.0 11776.0 258.1 68608.0 58983.4 - - - - 15 0.082 8 0.059 0.141
11264.0 11264.0 0.0 0.0 11776.0 3076.8 68608.0 58983.4 - - - - 15 0.082 8 0.059 0.141
11264.0 11264.0 0.0 0.0 11776.0 0.0 68608.0 390.0 - - - - 16 0.084 9 0.066 0.149
11264.0 11264.0 0.0 0.0 11776.0 0.0 68608.0 390.0 - - - - 16 0.084 9 0.066 0.149
11264.0 11264.0 0.0 0.0 11776.0 258.1 68608.0 390.0 - - - - 16 0.084 9 0.066 0.149
11264.0 11264.0 0.0 0.0 11776.0 3012.8 68608.0 390.0 - - - - 16 0.084 9 0.066 0.149jstat還可以以其他角度監視各區記憶體大小、監視類裝載資訊等,具體可以google jstat的詳細用法。
③ 用jmap(Memory Map for Java)檢視堆記憶體資訊
執行jmap -histo pid可以打印出當前堆中所有每個類的實體數量和記憶體佔用,如下,class name是每個類的類名([B是byte型別,[C是char型別,[I是int型別),bytes是這個類的所有示例佔用記憶體大小,instances是這個類的實體數量:
num #instances #bytes class name
----------------------------------------------
1: 2291 29274080 [B
2: 15252 1961040
3: 15252 1871400
4: 18038 721520 java.util.TreeMap$Entry
5: 6182 530088 [C
6: 11391 273384 java.lang.Long
7: 5576 267648 java.util.TreeMap
8: 50 155872 [I
9: 6124 146976 java.lang.String
10: 3330 133200 java.util.LinkedHashMap$Entry
11: 5544 133056 javax.management.openmbean.CompositeDataSupport執行 jmap -dump 可以轉儲堆記憶體快照到指定檔案,比如執行 jmap -dump:format=b,file=/data/jvm/dumpfile_jmap.hprof 3361 可以把當前堆記憶體的快照轉儲到dumpfile_jmap.hprof檔案中,然後可以對記憶體快照進行分析。
④ 利用jconsole、jvisualvm分析記憶體資訊(各個區如Eden、Survivor、Old等記憶體變化情況),如果檢視的是遠端伺服器的JVM,程式啟動需要加上如下引數:
"-Dcom.sun.management.jmxremote=true"
"-Djava.rmi.server.hostname=12.34.56.78"
"-Dcom.sun.management.jmxremote.port=18181"
"-Dcom.sun.management.jmxremote.authenticate=false"
"-Dcom.sun.management.jmxremote.ssl=false"下圖是jconsole介面,概覽選項可以觀測堆記憶體使用量、執行緒數、類載入數和CPU佔用率;記憶體選項可以檢視堆中各個區域的記憶體使用量和左下角的詳細描述(記憶體大小、GC情況等);執行緒選項可以檢視當前JVM載入的執行緒,檢視每個執行緒的堆疊資訊,還可以檢測死鎖;VM概要描述了虛擬機器的各種詳細引數。(jconsole功能演示)

下圖是jvisualvm的介面,功能比jconsole略豐富一些,不過大部分功能都需要安裝外掛。概述跟jconsole的VM概要差不多,描述的是jvm的詳細引數和程式啟動引數;監視展示的和jconsole的概覽介面差不多(CPU、堆/方法區、類載入、執行緒);執行緒和jconsole的執行緒介面差不多;抽樣器可以展示當前佔用記憶體的類的排行榜及其實體的個數;Visual GC可以更豐富地展示當前各個區域的記憶體佔用大小及歷史資訊(下圖)。(jvisualvm功能演示)

⑤ 分析堆轉儲快照
前面說到配置了 “-XX:+HeapDumpOnOutOfMemory” 引數可以在程式發生記憶體上限溢位時dump出當前的記憶體快照,也可以用jmap命令隨時dump出當時記憶體狀態的快照資訊,dump的記憶體快照一般是以.hprof為字尾的二進位制格式檔案。
可以直接用 jhat(JVM Heap Analysis Tool) 命令來分析記憶體快照,它的本質實際上內嵌了一個微型的伺服器,可以透過瀏覽器來分析對應的記憶體快照,比如執行 jhat -port 9810 -J-Xmx4G /data/jvm/dumpfile_jmap.hprof 表示以9810埠啟動 jhat 內嵌的伺服器:
Reading from /Users/dannyhoo/data/jvm/dumpfile_jmap.hprof...
Dump file created Fri Aug 03 15:48:27 CST 2018
Snapshot read, resolving...
Resolving 276472 objects...
Chasing references, expect 55 dots.......................................................
Eliminating duplicate references.......................................................
Snapshot resolved.
Started HTTP server on port 9810
Server is ready.在控制檯可以看到伺服器啟動了,訪問 http://127.0.0.1:9810/ 可以看到對快照中的每個類進行分析的結果(介面略low),下圖是我隨便選擇了一個類的資訊,有這個類的父類,載入這個類的類載入器和佔用的空間大小,下麵還有這個類的每個實體(References)及其記憶體地址和大小,點進去會顯示這個實體的一些成員變數等資訊:

jvisualvm也可以分析記憶體快照,在jvisualvm選單的“檔案”-“裝入”,選擇堆記憶體快照,快照中的資訊就以圖形介面展示出來了,如下,主要可以檢視每個類佔用的空間、實體的數量和實體的詳情等:

還有很多分析記憶體快照的第三方工具,比如eclipse mat,它比jvisualvm功能更專業,出了檢視每個類及對應實體佔用的空間、數量,還可以查詢物件之間的呼叫鏈,可以檢視某個實體到GC Root之間的鏈,等等。可以在eclipse中安裝mat外掛,也可以下載獨立的版本(http://www.eclipse.org/mat/downloads.php ),我在mac上安裝後執行起來老卡死~下麵是在windows上的截圖(MAT功能演示):

(3)JVM調優經驗
JVM配置方面,一般情況可以先用預設配置(基本的一些初始引數可以保證一般的應用跑的比較穩定了),在測試中根據系統執行狀況(會話併發情況、會話時間等),結合gc日誌、記憶體監控、使用的垃圾收集器等進行合理的調整,當老年代記憶體過小時可能引起頻繁Full GC,當記憶體過大時Full GC時間會特別長。
那麼JVM的配置比如新生代、老年代應該配置多大最合適呢?答案是不一定,調優就是找答案的過程,物理記憶體一定的情況下,新生代設定越大,老年代就越小,Full GC頻率就越高,但Full GC時間越短;相反新生代設定越小,老年代就越大,Full GC頻率就越低,但每次Full GC消耗的時間越大。建議如下:
-
-Xms和-Xmx的值設定成相等,堆大小預設為-Xms指定的大小,預設空閑堆記憶體小於40%時,JVM會擴大堆到-Xmx指定的大小;空閑堆記憶體大於70%時,JVM會減小堆到-Xms指定的大小。如果在Full GC後滿足不了記憶體需求會動態調整,這個階段比較耗費資源。
-
新生代儘量設定大一些,讓物件在新生代多存活一段時間,每次Minor GC 都要盡可能多的收集垃圾物件,防止或延遲物件進入老年代的機會,以減少應用程式發生Full GC的頻率。
-
老年代如果使用CMS收集器,新生代可以不用太大,因為CMS的並行收集速度也很快,收集過程比較耗時的併發標記和併發清除階段都可以與使用者執行緒併發執行。
-
方法區大小的設定,1.6之前的需要考慮系統執行時動態增加的常量、靜態變數等,1.7只要差不多能裝下啟動時和後期動態載入的類資訊就行。
程式碼實現方面,效能出現問題比如程式等待、記憶體洩漏除了JVM配置可能存在問題,程式碼實現上也有很大關係:
-
避免建立過大的物件及陣列:過大的物件或陣列在新生代沒有足夠空間容納時會直接進入老年代,如果是短命的大物件,會提前出發Full GC。
-
避免同時載入大量資料,如一次從資料庫中取出大量資料,或者一次從Excel中讀取大量記錄,可以分批讀取,用完儘快清空取用。
-
當集合中有物件的取用,這些物件使用完之後要儘快把集合中的取用清空,這些無用物件儘快回收避免進入老年代。
-
可以在合適的場景(如實現快取)採用軟取用、弱取用,比如用軟取用來為ObjectA分配實體:SoftReference objectA=new SoftReference(); 在發生記憶體上限溢位前,會將objectA列入回收範圍進行二次回收,如果這次回收還沒有足夠記憶體,才會丟擲記憶體上限溢位的異常。
避免產生死迴圈,產生死迴圈後,迴圈體內可能重覆產生大量實體,導致記憶體空間被迅速佔滿。 -
儘量避免長時間等待外部資源(資料庫、網路、裝置資源等)的情況,縮小物件的生命週期,避免進入老年代,如果不能及時傳回結果可以適當採用非同步處理的方式等。
(4)JVM問題排查記錄案例
JVM服務問題排查 https://blog.csdn.net/jacin1/article/details/44837595
次讓人難以忘懷的排查頻繁Full GC過程 http://caogen81.iteye.com/blog/1513345
線上FullGC頻繁的排查 https://blog.csdn.net/wilsonpeng3/article/details/70064336/
【JVM】線上應用故障排查 https://www.cnblogs.com/Dhouse/p/7839810.html
一次JVM中FullGC問題排查過程 http://iamzhongyong.iteye.com/blog/1830265
JVM記憶體上限溢位導致的CPU過高問題排查案例 https://blog.csdn.net/nielinqi520/article/details/78455614
一個java記憶體洩漏的排查案例 https://blog.csdn.net/aasgis6u/article/details/54928744
(5)常用JVM引數參考:
| 引數 | 說明 | 實體 |
|---|---|---|
| -Xms | 初始堆大小,預設物理記憶體的1/64 | -Xms512M |
| -Xmx | 最大堆大小,預設物理記憶體的1/4 | -Xms2G |
| -Xmn | 新生代記憶體大小,官方推薦為整個堆的3/8 | -Xmn512M |
| -Xss | 執行緒堆疊大小,jdk1.5及之後預設1M,之前預設256k | -Xss512k |
| -XX:NewRatio=n | 設定新生代和年老代的比值。如:為3,表示年輕代與年老代比值為1:3,年輕代佔整個年輕代年老代和的1/4 | -XX:NewRatio=3 |
| -XX:SurvivorRatio=n | 年輕代中Eden區與兩個Survivor區的比值。註意Survivor區有兩個。如:8,表示Eden:Survivor=8:1:1,一個Survivor區佔整個年輕代的1/8 | -XX:SurvivorRatio=8 |
| -XX:PermSize=n | 永久代初始值,預設為物理記憶體的1/64 | -XX:PermSize=128M |
| -XX:MaxPermSize=n | 永久代最大值,預設為物理記憶體的1/4 | -XX:MaxPermSize=256M |
| -verbose:class | 在控制檯列印類載入資訊 | |
| -verbose:gc | 在控制檯列印垃圾回收日誌 | |
| -XX:+PrintGC | 列印GC日誌,內容簡單 | |
| -XX:+PrintGCDetails | 列印GC日誌,內容詳細 | |
| -XX:+PrintGCDateStamps | 在GC日誌中新增時間戳 | |
| -Xloggc:filename | 指定gc日誌路徑 | -Xloggc:/data/jvm/gc.log |
| -XX:+UseSerialGC | 年輕代設定序列收集器Serial | |
| -XX:+UseParallelGC | 年輕代設定並行收集器Parallel Scavenge | |
| -XX:ParallelGCThreads=n | 設定Parallel Scavenge收集時使用的CPU數。並行收集執行緒數。 | -XX:ParallelGCThreads=4 |
| -XX:MaxGCPauseMillis=n | 設定Parallel Scavenge回收的最大時間(毫秒) | -XX:MaxGCPauseMillis=100 |
| -XX:GCTimeRatio=n | 設定Parallel Scavenge垃圾回收時間佔程式執行時間的百分比。公式為1/(1+n) | -XX:GCTimeRatio=19 |
| -XX:+UseParallelOldGC | 設定老年代為並行收集器ParallelOld收集器 | |
| -XX:+UseConcMarkSweepGC | 設定老年代併發收集器CMS | |
| -XX:+CMSIncrementalMode | 設定CMS收集器為增量樣式,適用於單CPU情況。 |
五、類載入
編寫的Java程式碼需要經過編譯器編譯為class檔案(從本地機器碼轉變為位元組碼的過程),class檔案是一組以8位位元組為基礎的二進位制流,這些二進位制流分別以一定形式表示著魔數(用於標識是否是一個能被虛擬機器接收的Class檔案)、版本號、欄位表、訪問標識等內容。程式碼編譯為class檔案後,需要透過類載入器把class檔案載入到虛擬機器中才能執行和使用。
1、類載入步驟
類從被載入到記憶體到使用完成被解除安裝出記憶體,需要經歷載入、連線、初始化、使用、解除安裝這幾個過程,其中連線又可以細分為驗證、準備、解析。

(1)載入
在載入階段,虛擬機器主要完成三件事情:
① 透過一個類的全限定名(比如com.danny.framework.t)來獲取定義該類的二進位制流;
② 將這個位元組流所代表的靜態儲存結構轉化為方法區的執行時儲存結構;
③ 在記憶體中生成一個代表這個類的java.lang.Class物件,作為程式訪問方法區中這個類的外部介面。
(2)驗證
驗證的目的是為了確保class檔案的位元組流包含的內容符合虛擬機器的要求,且不會危害虛擬機器的安全。
-
檔案格式驗證:主要驗證class檔案中二進位制位元組流的格式,比如魔數是否已0xCAFEBABY開頭、版本號是否正確等。
-
元資料驗證:主要對位元組碼描述的資訊進行語意分析,保證其符合Java語言規範,比如驗證這個類是否有父類(java.lang.Object除外),如果這個類不是抽象類,是否實現了父類或介面中沒有實現的方法,等等。
-
位元組碼驗證:位元組碼驗證更為高階,透過資料流和控制流分析,確保程式是合法的、符合邏輯的。
-
符號取用驗證:對類自身以外的資訊進行匹配性校驗,舉個慄子,比如透過類的全限定名能否找到對應類、在類中能否找到欄位名/方法名對應的欄位/方法,如果符號取用驗證失敗,將丟擲“java.lang.NoSuchFieldError”、“java.lang.NoSuchMethodError”等異常。
(3)準備
正式為【類變數】分配記憶體並設定類變數【初始值】,這些變數所使用的記憶體都分配在方法區。註意分配記憶體的物件是“類變數”而不是實體變數,而且為其分配的是“初始值”,一般數值型別的初始值都為0,char型別的初始值為’’(常量池中一個表示Nul的字串),boolean型別初始值為false,取用型別初始值為null。
但是加上final關鍵字比如public static final int value=123;在準備階段會初始化value的值為123;
(4)解析
解析是將常量池中【符號取用】替換為【直接取用】的過程。
符號取用是以一組符號來描述所取用的標的,符號取用與虛擬機器實現的記憶體佈局無關,取用的標的不一定已經載入到記憶體中。比如在com.danny.framework.LoggerFactory類取用了com.danny.framework.Logger,但在編譯期間是不知道Logger類的記憶體地址的,所以只能先用com.danny.framework.Logger(假設是這個,實際上是由類似於CONSTANT_Class_info的常量來表示的)來表示Logger類的地址,這就是符號取用。
直接取用可以是直接指向標的的指標、相對偏移量或是一個能間接定位到標的的控制代碼。直接取用和虛擬機器實現的記憶體佈局有關,如果有了直接取用,那取用的標的一定在記憶體中存在。
解析的時候class已經被載入到方法區的記憶體中,因此要把符號取用轉化為直接取用,也就是能直接找到該類實際記憶體地址的取用。
(5)初始化
在準備階段,已經為類變數賦了初始值,在初始化階段,則根據程式員透過程式定製的主觀計劃去初始化類變數的和其他資源,也可以從另一個角度來理解:初始化階段是執行類建構式()方法的過程,那()到底是什麼呢?
我的理解是,java在生成位元組碼時,如果類中有靜態程式碼塊或靜態變數的賦值操作,會將類建構式()方法和實體建構式 () 方法新增到語法樹中(可以理解為在編譯階段自動為類添加了兩個隱藏的方法:類建構式——()方法和實體建構式——()方法,可以用javap命令檢視),()主要用來構造類,比如初始化類變數(靜態變數),執行靜態程式碼塊(statis{})等,該方法只執行一次;()方法主要用來構造實體,在構造實體的過程中,會首先執行(),這時物件中的所有成員變數都會被設定為預設值(每種資料型別的預設值和類載入準備階段描述的一樣),然後才會執行實體的建構式(會先執行父類的構造方法,再執行非靜態程式碼塊,最後執行建構式)。
下麵看段程式碼來理解下:
public class Parent {
static {
System.out.println("Parent-靜態程式碼塊執行");
}
public Parent() {
System.out.println("Parent-構造方法執行");
}
{
System.out.println("Parent-非靜態程式碼塊執行");
}
}
public class Child extends Parent{
private static int staticValue = 123;
private int noStaticValue=456;
static {
System.out.println("Child-靜態程式碼塊執行");
}
public Child() {
System.out.println("Child-構造方法執行");
}
{
System.out.println("Child-非靜態程式碼塊執行");
}
public static void main(String[] args) {
Child child = new Child();
}
}看下麵的執行結果之前可以先猜測一下結果是什麼,執行結果如下:
Parent-靜態程式碼塊執行
Child-靜態程式碼塊執行
Parent-非靜態程式碼塊執行
Parent-構造方法執行
Child-非靜態程式碼塊執行
Child-構造方法執行上面的例子中可以看到一個類從載入到實體化的過程中,靜態程式碼塊、構造方法、非靜態程式碼塊的載入順序。無法看到靜態變數和非靜態變數初始化的時間,靜態變數的初始化和靜態程式碼塊的執行都是在類的初始化階段(())完成,非靜態變數和非靜態程式碼塊都是在實體的初始化階段(())完成。
2、類載入器
(1)類載入器的作用
-
載入class:類載入的載入階段的第一個步驟,就是透過類載入器來完成的,類載入器的主要任務就是“透過一個類的全限定名來獲取描述此類的二進位制位元組流”,在這裡,類載入器載入的二進位制流並不一定要從class檔案中獲取,還可以從其他格式如zip檔案中讀取、從網路或資料庫中讀取、執行時動態生成、由其他檔案生成(比如jsp生成class類檔案)等。
從程式員的角度來看,類載入器動態載入class檔案到虛擬機器中,並生成一個java.lang.Class實體,每個實體都代表一個java類,可以根據該實體得到該類的資訊,還可以透過newInstance()方法生成該類的一個物件。 -
確定類的唯一性:類載入器除了有載入類的作用,還有一個舉足輕重的作用,對於每一個類,都需要由載入它的載入器和這個類本身共同確立這個類在Java虛擬機器中的唯一性。也就是說,兩個相同的類,只有是在同一個載入器載入的情況下才“相等”,這裡的“相等”是指代表類的Class物件的equals()方法、isAssignableFrom()方法、isInstance()方法的傳回結果,也包括instanceof關鍵字對物件所屬關係的判定結果。
(2)類載入器的分類
以開發人員的角度來看,類載入器分為如下幾種:啟動類載入器(Bootstrap ClassLoader)、擴充套件類載入器(Extension ClassLoader)、應用程式類載入器(Application ClassLoader)和自定義類載入器(User ClassLoader),其中啟動類載入器屬於JVM的一部分,其他類載入器都用java實現,並且最終都繼承自java.lang.ClassLoader。
① 啟動類載入器(Bootstrap ClassLoader)是由C/C++編譯而來的,看不到原始碼,所以在java.lang.ClassLoader原始碼中看到的Bootstrap ClassLoader的定義是native的“private native Class findBootstrapClass(String name);”。啟動類載入器主要負責載入JAVA_HOMElib目錄或者被-Xbootclasspath引數指定目錄中的部分類,具體載入哪些類可以透過“System.getProperty(“sun.boot.class.path”)”來檢視。
② 擴充套件類載入器(Extension ClassLoader)由sun.misc.Launcher.ExtClassLoader實現,負責載入JAVA_HOMElibext目錄或者被java.ext.dirs系統變數指定的路徑中的所有類庫,可以用透過“System.getProperty(“java.ext.dirs”)”來檢視具體都載入哪些類。
③ 應用程式類載入器(Application ClassLoader)由sun.misc.Launcher.AppClassLoader實現,負責載入使用者類路徑(我們通常指定的classpath)上的類,如果程式中沒有自定義類載入器,應用程式類載入器就是程式預設的類載入器。
④ 自定義類載入器(User ClassLoader),JVM提供的類載入器只能載入指定目錄的類(jar和class),如果我們想從其他地方甚至網路上獲取class檔案,就需要自定義類載入器來實現,自定義類載入器主要都是透過繼承ClassLoader或者它的子類來實現,但無論是透過繼承ClassLoader還是它的子類,最終自定義類載入器的父載入器都是應用程式類載入器,因為不管呼叫哪個父類載入器,建立的物件都必須最終呼叫java.lang.ClassLoader.getSystemClassLoader()作為父載入器,getSystemClassLoader()方法的傳回值是sun.misc.Launcher.AppClassLoader即應用程式類載入器。
(3)ClassLoader與雙親委派模型
下麵看一下類載入器java.lang.ClassLoader中的核心邏輯loadClass()方法:
protected Class> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 檢查該類是否已經載入過
Class c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {//如果父載入器不為空,就用父載入器載入類
c = parent.loadClass(name, false);
} else {//如果父載入器為空,就用啟動類載入器載入類
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
}
if (c == null) {//如果上面用父載入器還沒載入到類,就自己嘗試載入
long t1 = System.nanoTime();
c = findClass(name);
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}這段程式碼的主要意思就是當一個類載入器載入類的時候,如果有父載入器就先嘗試讓父載入器載入,如果父載入器還有父載入器就一直往上拋,一直把類載入的任務交給啟動類載入器,然後啟動類載入器如果載入不到類就會丟擲ClassNotFoundException異常,之後把類載入的任務往下拋,如下圖:
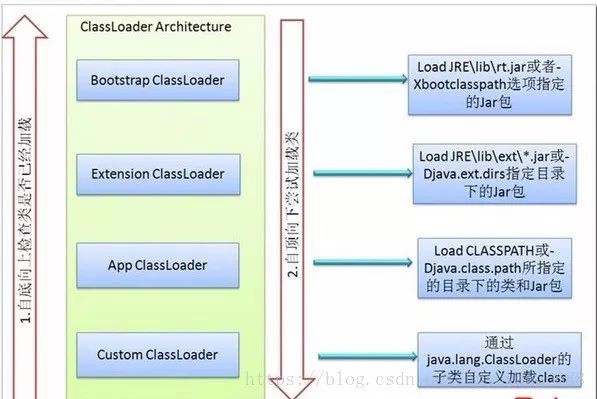
透過上圖的類載入過程,就引出了一個比較重要的概念——雙親委派模型,如下圖展示的層次關係,雙親委派模型要求除了頂層的啟動類載入器之外,其他的類載入器都應該有一個父類載入器,但是這種父子關係並不是繼承關係,而是像上面程式碼所示的組合關係。

雙親委派模型的工作過程是,如果一個類載入器收到了類載入的請求,它首先不會載入類,而是把這個請求委派給它上一層的父載入器,每層都如此,所以最終請求會傳到啟動類載入器,然後從啟動類載入器開始嘗試載入類,如果載入不到(要載入的類不在當前類載入器的載入範圍),就讓它的子類嘗試載入,每層都是如此。
那麼雙親委派模型有什麼好處呢?最大的好處就是它讓Java中的類跟類載入器一樣有了“優先順序”。前面說到了對於每一個類,都需要由載入它的載入器和這個類本身共同確立這個類在Java虛擬機器中的唯一性,比如java.lang.Object類(存放在JAVA_HOMElib
t.jar中),如果使用者自己寫了一個java.lang.Object類並且由自定義類載入器載入,那麼在程式中是不是就是兩個類?所以雙親委派模型對保證Java穩定執行至關重要。
●編號768,輸入編號直達本文
●輸入m獲取文章目錄

演演算法與資料結構
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
