

本文試圖從基本概念開始對磁碟儲存相關的各種概念進行綜合歸納,讓大家能夠對IO效能相關的基本概念,IO效能的監控和調整有個比較全面的瞭解。
讀寫IO(Read/Write IO)操作
磁碟是用來給我們存取資料用的,因此當說到IO操作的時候,就會存在兩種相對應的操作,存資料時候對應的是寫IO操作,取資料的時候對應的是是讀IO操作。
當控制磁碟的控制器接到作業系統的讀IO操作指令的時候,控制器就會給磁碟發出一個讀資料的指令,並同時將要讀取的資料塊的地址傳遞給磁碟,然後磁碟會將讀取到的資料傳給控制器,並由控制器傳回給作業系統,完成一個寫IO的操作;同樣的,一個寫IO的操作也類似,控制器接到寫的IO操作的指令和要寫入的資料,並將其傳遞給磁碟,磁碟在資料寫入完成之後將操作結果傳遞迴控制器,再由控制器傳回給作業系統,完成一個寫IO的操作。單個IO操作指的就是完成一個寫IO或者是讀IO的操作。
隨機(Random)訪問與連續(Sequential)訪問
隨機訪問指的是本次IO所給出的扇區地址和上次IO給出扇區地址相差比較大,這樣的話磁頭在兩次IO操作之間需要作比較大的移動動作才能重新開始讀/寫資料。相反的,如果當次IO給出的扇區地址與上次IO結束的扇區地址一致或者是接近的話,那磁頭就能很快的開始這次IO操作,這樣的多個IO操作稱為連續訪問。因此儘管相鄰的兩次IO操作在同一時刻發出,但如果它們的請求的扇區地址相差很大的話也只能稱為隨機訪問,而非連續訪問。
順序IO(Queue Mode)/併發IO(Burst Mode)
磁碟控制器可能會一次對磁碟組發出一連串的IO命令,如果磁碟組一次只能執行一個IO命令時稱為順序IO;當磁碟組能同時執行多個IO命令時,稱為併發IO。併發IO只能發生在由多個磁碟組成的磁碟組上,單塊磁碟只能一次處理一個IO命令。
單個IO的大小(IO Size)
熟悉資料庫的人都會有這麼一個概念,那就是資料庫儲存有個基本的塊大小(Block Size),不管是SQL Server還是Oracle,預設的塊大小都是8KB,就是資料庫每次讀寫都是以8k為單位的。那麼對於資料庫應用發出的固定8k大小的單次讀寫到了寫磁碟這個層面會是怎麼樣的呢,就是對於讀寫磁碟來說單個IO操作運算元據的大小是多少呢,是不是也是一個固定的值?
答案是不確定。首先作業系統為了提高 IO的效能而引入了檔案系統快取(File System Cache),系統會根據請求資料的情況將多個來自IO的請求先放在快取裡面,然後再一次性的提交給磁碟,也就是說對於資料庫發出的多個8K資料塊的讀操作有可能放在一個磁碟讀IO裡就處理了。
還有對於有些儲存系統也是提供了快取(Cache)的,接收到作業系統的IO請求之後也是會將多個作業系統的 IO請求合併成一個來處理。不管是作業系統層面的快取還是磁碟控制器層面的快取,目的都只有一個,提高資料讀寫的效率。因此每次單獨的IO操作大小都是不一樣的,它主要取決於系統對於資料讀寫效率的判斷。
當一次IO操作大小比較小的時候我們成為小的IO操作,比如說1K,4K,8K這樣的;當一次IO操作的資料量比較的的時候稱為大IO操作,比如說32K,64K甚至更大。
在我們說到塊大小(Block Size)的時候通常我們會接觸到多個類似的概念,像我們上面提到的那個在資料庫裡面的資料最小的管理單位,Oralce稱之為塊(Block),大小一般為8K,SQL Server稱之為頁(Page),一般大小也為8k。
在檔案系統裡面我們也能碰到一個檔案系統的塊,在現在很多的Linux系統中都是4K(透過 /usr/bin/time -v可以看到),它的作用其實跟資料庫裡面的塊/頁是一樣的,都是為了方便資料的管理。但是說到單次IO的大小,跟這些塊的大小都是沒有直接關係的,在英文裡單次IO大小通常被稱為是IO Chunk Size,不會說成是IO Block Size的。
IOPS(IO per Second)
IOPS即IO系統每秒所執行IO操作的次數,是一個重要的用來衡量系統IO能力的一個引數。對於單個磁碟組成的IO系統來說,計算它的IOPS不是一件很難的事情,只要我們知道了系統完成一次IO所需要的時間的話我們就能推算出系統IOPS來。
現在我們就來推算一下磁碟的IOPS,假設磁碟的轉速(Rotational Speed)為15K RPM,平均尋道時間為5ms,最大傳輸速率為40MB/s(這裡將讀寫速度視為一樣,實際會差別比較大)。
對於磁碟來說一個完整的IO操作是這樣進行的:當控制器對磁碟發出一個IO操作命令的時候,磁碟的驅動臂(Actuator Arm)帶讀寫磁頭(Head)離開著陸區(Landing Zone,位於內圈沒有資料的區域),移動到要操作的初始資料塊所在的磁軌(Track)的正上方,這個過程被稱為定址(Seeking),對應消耗的時間被稱為定址時間(Seek Time)。
但是找到對應磁軌還不能馬上讀取資料,這時候磁頭要等到磁碟碟片(Platter)旋轉到初始資料塊所在的扇區(Sector)落在讀寫磁頭正上方的之後才能開始讀取資料,在這個等待碟片旋轉到可操作扇區的過程中消耗的時間稱為旋轉延時(Rotational Delay);接下來就隨著碟片的旋轉,磁頭不斷的讀/寫相應的資料塊,直到完成這次IO所需要操作的全部資料,這個過程稱為資料傳送(Data Transfer),對應的時間稱為傳送時間(Transfer Time)。完成這三個步驟之後一次IO操作也就完成了。
在我們看硬碟廠商的宣傳單的時候我們經常能看到3個引數,分別是平均定址時間、碟片旋轉速度以及最大傳送速度,這三個引數就可以提供給我們計算上述三個步驟的時間。
第一個定址時間Tseek,考慮到被讀寫的資料可能在磁碟的任意一個磁軌,既有可能在磁碟的最內圈(定址時間最短),也可能在磁碟的最外圈(定址時間最長),所以在計算中我們只考慮平均定址時間,也就是磁碟引數中標明的那個平均定址時間,尋道時間Tseek是指將讀寫磁頭移動至正確的磁軌上所需要的時間。尋道時間越短,I/O操作越快,目前磁碟的平均尋道時間一般在3-15ms。
第二個旋轉延時,和定址一樣,當磁頭定位到磁軌之後有可能正好在要讀寫扇區之上,這時候是不需要額外額延時就可以立刻讀寫到資料,但是最壞的情況確實要磁碟旋轉整整一圈之後磁頭才能讀取到資料,所以這裡我們也考慮的是平均旋轉延時,旋轉延遲取決於磁碟轉速,通常使用磁碟旋轉一週所需時間的1/2表示。比如,7200 rpm的磁碟平均旋轉延遲大約為60*1000/7200/2 = 4.17ms,而轉速為15000 rpm的磁碟其平均旋轉延遲約為2ms。
第三個傳送時間Ttransfer,是指完成傳輸所請求的資料所需要的時間,它取決於資料傳輸率,其值等於資料大小除以資料傳輸率。這個時間就是IO Size / Max Transfer Rate。目前IDE/ATA能達到133MB/s,SATA II可達到300MB/s的介面資料傳輸率,資料傳輸時間通常遠小於前兩部分時間。
對於SSD盤,效能的差異主要在於儲存單元架構的不同。SLC(單階儲存單元)優於MLC(多階儲存單元)。
磁碟RAID組IOPS
通常我們在使用儲存的時候,都是把多個磁碟建成一個Raid,那麼這個由多個磁碟構成的RAID的IOPS就跟我們採用的RAID級別有很大關係,比如對於RAID5,一旦條帶上的任意磁碟的資料發生改變,都會重新計算校驗位。
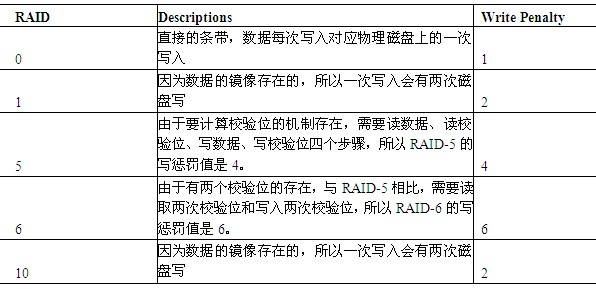
無論是那種RAID級別,磁碟的寫效能則會由於不同型別的資料冗餘影響實際寫的數量,這種由於冗餘資料帶來的額外開銷稱為寫懲罰penalty,RAID 0無RAID 懲罰、RAID 1/ 10寫懲罰是2、RAID 5是4、RAID 6是6。
假設組成RAID的單個磁碟的隨機讀寫的IOPS為140,讀寫快取命中率都為10%,組成陣列的磁碟個數為4。所以可以得出下麵寫入IOPS:

RAID總IOPS=寫入IOPS+讀IOPS。
磁碟陣列IOPS
磁碟陣列為了進一步提升效能,在其控制器上一般都會再加上cache快取,有的還有第二級的快取(Flash Memory/ Disks),這樣一來整個陣列和其中某個RIAD的IOPS就變得難以計算。
很多廠商公佈的那些非常高的IOPS資料實際上是將被測儲存系統配置了儘量多的小容量、高轉速磁碟且每個磁碟裝載資料量不多、設定為RAID10時測出的100%順序讀(Sequential Read)IOPS的最大值。而且很多廠商在公佈上述100%順序讀(Sequential Read)IOPS時還隱去了“100%順序讀”字樣,籠統地稱為IOPS。
幸運的是我們還有SPC和SPC-1 IOPS™可以信任和參考。SPC的全稱是Storage Performance Council,它的成員由幾乎全部的國外儲存廠商和部分大學、研究機構組成,SPC是一個非贏利的組織,其使命是定義、標準化儲存系統的基準測試,並提升儲存系統基準測試的知名度、擴充套件其影響,使之成為計算機行業最具權威性的儲存效能測試結果,使計算機使用者可以不受現存混亂的各種儲存效能測試結果的影響。
目前SPC的SPC-1基準測試主要是針對隨機I/O應用環境的,SPC-2基準測試主要是針對順序I/O應用環境的。SPC-1基準測試很好地模擬了OLTP、資料庫和e-mail等真實應用環境,使SPC-1基準測試結果具有很高權威性和可比性。各儲存廠商的SPC-1基準測試報告中列明瞭進行測試的儲存系統配置。
但是要註意的是,這些測試結果我們不應該直接使用,因為測試的配置和我們時間專案中的配置肯定不同,而且SPC-1/ 2也是個系統最大效能值。所以其最重要的意義在於它使我們知道這種磁碟陣列在某種配置下,陣列的實測IOPS跟我們透過上述IOPS中介紹的方法計算出來的總IOPS理論值之間的比例,這個比例(我稱為提升因子)代表了陣列中的快取對IO起到的提升作用。
換句話說,以後我們在對陣列中RAID的IOPS理論計算中可以乘上這個比例。有些廠商也直接告訴你這個因子,比如說NETAPP就宣稱採用PAM快取卡可降低75%的讀IO,WAFL寫最佳化可降低50%的寫IO等等,這裡的1/(1-75)%和1/(1-50%)就可以看作提升因子,只不過可信度有多少就不知道了。
桌面虛擬化陣列IOPS
在實際執行中每個桌面VM有不同的工作狀態,一般而言每中工作狀態對儲存子系統都有不同的要求,工作(輕量: 4-8 IOPS、普通: 8-15 IOPS、重量: 15-30 IOPS)、空閑: 4 IOPS、登出: 12 IOPS、Offline: 0 IOPS。
那麼在桌面虛擬化環境下,我們如何評估一個儲存系統能否滿足我們的使用要求呢。我認為可以從兩個方面考慮:
1、整個系統IOPS總需求與總供給:比如我們總共需要提供給研發使用者5000臺重量級VM,每臺VM峰值IOPS需求是30,那麼總需求就是150000;每個磁碟陣列提供的IOPS大約為SPC-1測試值×SPC-1測試配置的磁碟數量/實際專案中配置的磁碟數量,總IOPS供給=磁碟陣列提供的IOPS×磁碟陣列數量。這樣我們就能計算出整個儲存配置能否滿足專案的需求。
2、每個儲存資源(一個LUN,一般對應儲存 陣列上的由多個磁碟組成的一個RAID)的IOPS需求與供給:根據最佳實踐,每個儲存資源上放置25-30臺重量級VM,按照25臺計算,因此需求是25×30=750 IOPS;而對應的RAID的供給可以根據總IOPS×提升因子計算得到效能需求。這樣我們就可以判斷具體某一個儲存資源的磁碟配置能否滿足專案的需要。
IO響應時間(IO Response Time)
IO響應時間也被稱為IO延時(IO Latency),IO響應時間就是從作業系統核心發出的一個讀或者寫的IO命令到作業系統核心接收到IO回應的時間,註意不要和單個IO時間混淆了,單個IO時間僅僅指的是IO操作在磁碟內部處理的時間,而IO響應時間還要包括IO操作在IO等待佇列中所花費的等待時間。
隨著系統實際IOPS越接近理論的最大值,IO的響應時間會成非線性的增長,越是接近最大值,響應時間就變得越大,而且會比預期超出很多。一般來說在實際的應用中有一個70%的指導值,也就是說在IO讀寫的佇列中,當佇列大小小於最大IOPS的70%的時候,IO的響應時間增加會很小,相對來說讓人比較能接受的,一旦超過70%,響應時間就會戲劇性的暴增,所以當一個系統的IO壓力超出最大可承受壓力的70%的時候就是必須要考慮調整或升級了。
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多電子書詳情。

求知若渴, 虛心若愚
