

本文主要介紹大型分散式系統中快取的相關理論,常見的快取元件以及應用場景。
快取概述
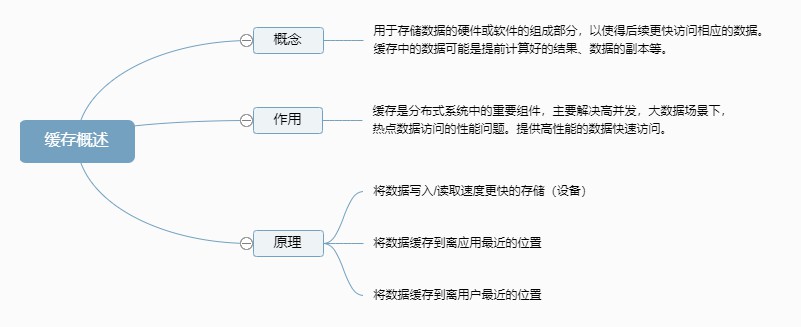
快取概述
快取的分類
快取主要分為四類,如下圖:

快取的分類
CDN 快取
CDN(Content Delivery Network 內容分髮網路)的基本原理是廣泛採用各種快取伺服器,將這些快取伺服器分佈到使用者訪問相對集中的地區或網路中。
在使用者訪問網站時,利用全域性負載技術將使用者的訪問指向距離最近的工作正常的快取伺服器上,由快取伺服器直接響應使用者請求。
應用場景:主要快取靜態資源,例如圖片,影片。
CDN 快取應用如下圖:

未使用 CDN 快取

使用 CDN 快取
CDN 快取優點如下圖:

優點
反向代理快取
反向代理位於應用伺服器機房,處理所有對 Web 伺服器的請求。
如果使用者請求的頁面在代理伺服器上有緩衝的話,代理伺服器直接將緩衝內容傳送給使用者。
如果沒有緩衝則先向 Web 伺服器發出請求,取回資料,本地快取後再傳送給使用者。透過降低向 Web 伺服器的請求數,從而降低了 Web 伺服器的負載。
應用場景:一般只快取體積較小靜態檔案資源,如 css、js、圖片。
反向代理快取應用如下圖:
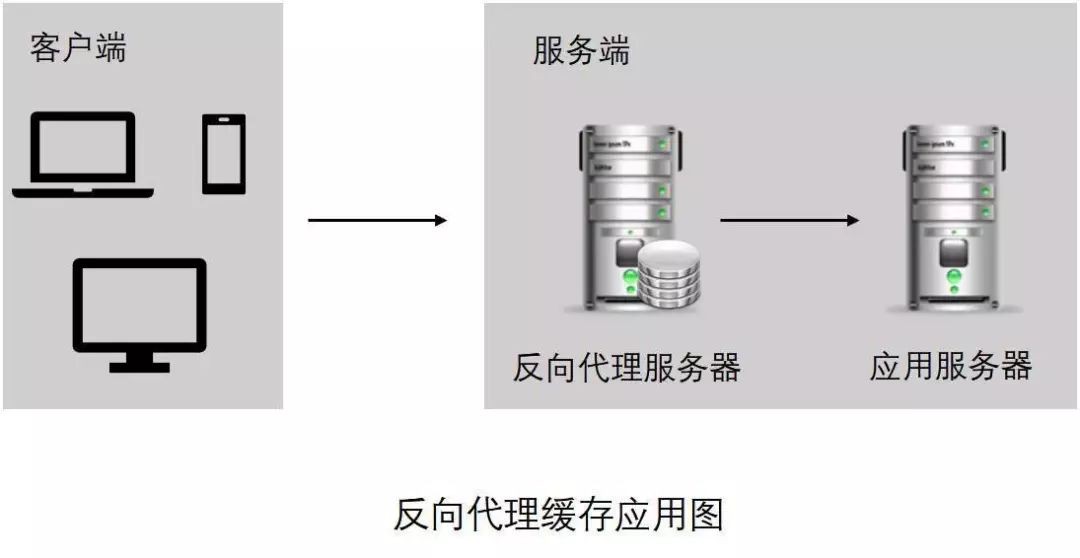
反向代理快取應用圖
開源實現如下圖:
開源實現
本地應用快取
指的是在應用中的快取元件,其最大的優點是應用和 Cache 是在同一個行程內部,請求快取非常快速,沒有過多的網路開銷等。
在單應用不需要叢集支援或者叢集情況下各節點無需互相通知的場景下使用本地快取較合適。
同時,它的缺點也是應為快取跟應用程式耦合,多個應用程式無法直接的共享快取,各應用或叢集的各節點都需要維護自己的單獨快取,對記憶體是一種浪費。
應用場景:快取字典等常用資料。
快取介質如下圖所示:

快取介質
程式設計直接實現如下圖:

程式設計直接實現
Ehcache
基本介紹:Ehcache 是一種基於標準的開源快取,可提高效能,解除安裝資料庫並簡化可伸縮性。
它是使用最廣泛的基於 Java 的快取,因為它功能強大,經過驗證,功能齊全,並與其他流行的庫和框架整合。
Ehcache 可以從行程內快取擴充套件到使用 TB 級快取的混合行程內/行程外部署。
Ehcache 應用場景如下圖:

Ehcache 應用場景
Ehcache 的架構如下圖:

Ehcache 架構圖
Ehcache 的主要特徵如下圖:

Ehcache 主要特徵
Ehcache 快取資料過期策略如下圖:

快取資料過期策略
Ehcache 過期資料淘汰機制:即懶淘汰機制,每次往快取放入資料的時候,都會存一個時間,在讀取的時候要和設定的時間做 TTL 比較來判斷是否過期。
Guava Cache
基本介紹:Guava Cache 是 Google 開源的 Java 重用工具集庫 Guava 裡的一款快取工具。
Guava Cache 特點與功能如下圖:

Guava Cache 特點與功能
Guava Cache 的應用場景如下圖:

Guava Cache 應用場景
Guava Cache 的資料結構如下圖:

Guava Cache 資料結構圖

Guava Cache 結構特點
Guava Cache 的快取更新策略如下圖:
Guava Cache 快取更新策略
Guava Cache 的快取回收策略如下圖:

Guava Cache 快取回收策略
分散式快取
指的是與應用分離的快取元件或服務,其最大的優點是自身就是一個獨立的應用,與本地應用隔離,多個應用可直接的共享快取。
分散式快取的主要應用場景如下圖:

分散式快取應用場景
分散式快取的主要接入方式如下圖:
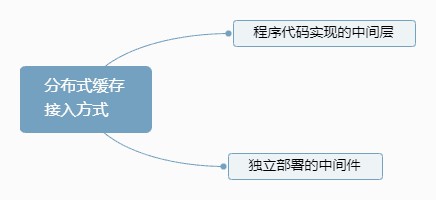
分散式快取接入方式
下麵介紹分散式快取常見的 2 大開源實現 Memcached 和 Redis。
Memcached
Memcached 是一個高效能,分散式記憶體物件快取系統,透過在記憶體裡維護一個統一的巨大的 Hash 表,它能夠用來儲存各種格式的資料,包括影象、影片、檔案以及資料庫檢索的結果等。
簡單的說就是將資料呼叫到記憶體中,然後從記憶體中讀取,從而大大提高讀取速度。
Memcached 的特點如下圖:

Memcached 特點
Memcached 的基本架構如下圖:

Memcached 基本架構
快取資料過期策略:LRU(最近最少使用)到期失效策略,在 Memcached 記憶體儲資料項時,可以指定它在快取的失效時間,預設為永久。
當 Memcached 伺服器用完分配的記憶體時,失效的資料被首先替換,然後是最近未使用的資料。
資料淘汰內部實現:懶淘汰機製為每次往快取放入資料的時候,都會存一個時間,在讀取的時候要和設定的時間做 TTL 比較來判斷是否過期。
分散式叢集實現:服務端並沒有 “ 分散式 ” 功能。每個伺服器都是完全獨立和隔離的服務。 Memcached 的分散式,是由客戶端程式實現的。

資料讀寫流程圖

Memcached 分散式叢集實現
Redis
Redis 是一個遠端記憶體資料庫(非關係型資料庫),效能強勁,具有複製特性以及解決問題而生的獨一無二的資料模型。
它可以儲存鍵值對與 5 種不同型別的值之間的對映,可以將儲存在記憶體的鍵值對資料持久化到硬碟,可以使用複製特性來擴充套件讀效能。
Redis 還可以使用客戶端分片來擴充套件寫效能,內建了 複製(replication),LUA 指令碼(Lua scripting),LRU 驅動事件(LRU eviction),事務(transactions) 和不同級別的磁碟持久化(persistence)。
並透過 Redis 哨兵(Sentinel)和自動分割槽(Cluster)提供高可用性(High Availability)。
Redis 的資料模型如下圖:
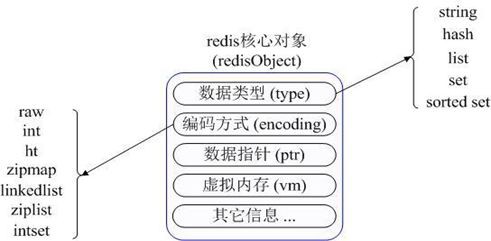
Redis 資料模型
Redis 的資料淘汰策略如下圖:

Redis 資料淘汰策略
Redis 的資料淘汰內部實現如下圖:

Redis 資料淘汰內部實現
Redis 的持久化方式如下圖:

Redis 持久化方式
Redis 底層實現部分解析如下圖:

啟動的部分過程圖解
Server 端持久化的部分操作圖解
底層雜湊表實現(漸進式Rehash)如下圖:

初始化字典

新增字典元素圖解

Rehash 執行流程
Redis 的快取設計原則如下圖所示:

Redis 快取設計原則
Redis 與 Memcached 的比較如下圖:
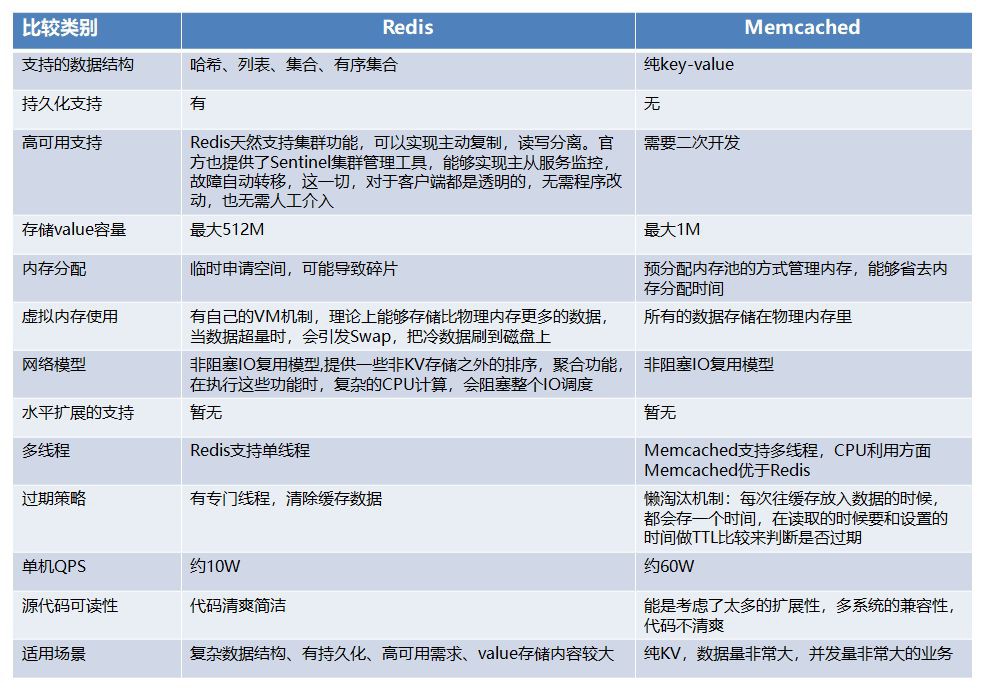
Redis 與 Memcached 比較
下麵主要介紹快取架構設計常見問題以及解決方案,業界案例。
分層快取架構設計

快取帶來的複雜度問題
常見的問題主要包括如下幾點:
-
資料一致性
-
快取穿透
-
快取雪崩
-
快取高可用
-
快取熱點
下麵逐一介紹分析這些問題以及相應的解決方案。
資料一致性
因為快取屬於持久化資料的一個副本,因此不可避免的會出現資料不一致問題,導致臟讀或讀不到資料的情況。
資料不一致,一般是因為網路不穩定或節點故障導致問題出現的常見 3 個場景以及解決方案:

快取穿透
快取一般是 Key-Value 方式存在,當某一個 Key 不存在時會查詢資料庫,假如這個 Key,一直不存在,則會頻繁的請求資料庫,對資料庫造成訪問壓力。
主要解決方案:
-
對結果為空的資料也進行快取,當此 Key 有資料後,清理快取。
-
一定不存在的 Key,採用布隆過濾器,建立一個大的 Bitmap 中,查詢時透過該 Bitmap 過濾。
快取雪崩

快取高可用
快取是否高可用,需要根據實際的場景而定,並不是所有業務都要求快取高可用,需要結合具體業務,具體情況進行方案設計,例如臨界點是否對後端的資料庫造成影響。
主要解決方案:
-
分佈式:實現資料的海量快取。
-
複製:實現快取資料節點的高可用。
快取熱點
一些特別熱點的資料,高併發訪問同一份快取資料,導致快取伺服器壓力過大。
解決:複製多份快取副本,把請求分散到多個快取伺服器上,減輕快取熱點導致的單臺快取伺服器壓力
業界案例
案例主要參考新浪微博陳波的技術分享,可以檢視原文《百億級日訪問量的應用如何做快取架構設計?》
技術挑戰
Feed 快取架構圖

架構特點
新浪微博把 SSD 應用在分散式快取場景中,將傳統的 Redis/MC + MySQL 方式,擴充套件為 Redis/MC + SSD Cache + MySQL 方式。
SSD Cache 作為 L2 快取使用,第一降低了 MC/Redis 成本過高,容量小的問題,也解決了穿透 DB 帶來的資料庫訪問壓力。
主要在資料架構、效能、儲存成本、服務化等不同方面進行了最佳化增強。


轉自:51CTO技術棧。
作者:陳彩華
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多電子書詳情。

求知若渴, 虛心若愚

