

大賽背景
第四屆阿裡中介軟體效能挑戰賽是由阿裡巴巴集團發起,阿裡巴巴中間(Aliware)、阿裡雲天池聯合舉辦,是集團唯一的工程性品牌賽事。大賽的初衷是為熱愛技術的年輕人提供一個挑戰世界級技術問題的舞臺,希望選手在追求效能極致的同時,能深刻體會技術人的匠心精神,用技術為全社會創造更大的價值。
本文是亞軍選手“做作業”的解題思路,來自南京理工大學的95後開發者。
初賽部分
一、賽題重述及理解
初賽主要的考察點是實現一個高效能的http伺服器,一套優秀的負載均衡演演算法。而協議轉換僅需要對協議進行詳細瞭解即可實現,屬於基本技能考察。而服務的註冊和發現參考demo中的實現即可,屬於比較常用的處理邏輯。
針對高效能的http伺服器,想要在競賽環境下取得較好的成績,使用常用通用http框架是較難取得高分的,因為consumer agent和consumer共享一個docker執行環境,在512連線測試環境下,系統資源就已經很緊張了,需要在捨棄一部分http特性的情況下才能將consumer效能發揮到極致。所以自己造輪子是一個比較合適的方案。Consumeragent的總體結構(所有邏輯基本集中在這)如圖1所示。

圖1 Consumer Agent結構
二、網路程式設計模型的選擇
高併發網路模型首選epoll,在連線數增多的情況下,其效能不會像select和poll一樣明顯下降,是由於核心對其進行了特殊最佳化,不是線性遍歷所有連線。實際測試中發現,因為請求是在收到響應後才會繼續發出,所以不僅要求高併發,同時要求低延遲,因為延遲疊加的原因也會導致QPS下降。
而我們使用的常見的非同步網路庫libuv、libevent等都是one loop per thread的,即一個執行緒一個事件迴圈,這種設計具有較高的吞吐量,但請求只能系結到一個事件迴圈上,一旦請求不均勻,則會導致一核有難眾核圍觀的情況,對於動態均衡執行緒負載很不適合。
基於此原因我決定自己造輪子,讓多個執行緒處理一個epoll迴圈,讓作業系統的執行緒排程均衡請求,同時所有連線均系結到一個事件迴圈上,也便於處理。最終我選擇使用多執行緒的et樣式的epoll模型,整體框架程式碼如圖2所示。

圖2 多執行緒epoll框架
整體框架非常簡潔,所有網路處理類僅需繼承CepollCallback完成網路資料的讀取和寫入即可。
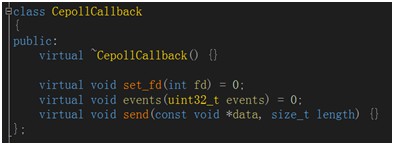
圖3 epoll回呼抽象類
三、程式整體流程
Consumer端agent負責解析http請求轉換為dubbo請求,以udp形式發給provider agent處理,provider agent收到udp後直接傳給provider dubbo服務處理,將結果以udp形式回傳,consumer agent處理後傳回http形式結果。


圖4、5 CA/PA處理流程
程式初始化的時候provider agent呼叫etcd介面將自己的服務註冊,consumer agent呼叫etcd介面獲取到註冊的provider agent地址,由於採用udp協議通訊,故不用提前建立連線。Provider agent端也僅在第一個請求到達時建立到provider的tcp連線,保證provider已經啟動完畢可以接受請求。
四、中間協議設計
考慮到高吞吐量,低延遲,採用了udp協議,請求為單包單請求,資料格式為dubbo請求格式,相應包為單包多相應,資料格式為dubbo響應。即consumer agent端實現協議轉換,provider agent端實現udp轉tcp。
由於請求僅存在於一個包中,所以無需考慮亂序情況,直接將收到的資料包進行重組發到dubbo的tcp連線上,提供最大的吞吐量和最低的延遲。具體處理操作如圖3。

圖3 udp重組轉發tcp
同時為了減少系統呼叫,可以一直取udp包,當緩衝滿後一次性寫入tcp的緩衝中。同理在tcp轉udp時,可以將資料湊成接近MTU,減少網路壓力。如圖4所示。

圖4 udp單包多相應
還有很多工程上的技巧,比如調整緩衝區大小等,保證每次非同步呼叫都能成功,減少系統呼叫次數。
五、負載均衡演演算法
負載均衡採用計數方法實現,每次請求傳送到和配置負載比例差距最大的Provider上,如果3臺都超出200負載,則進行請求排隊,當有請求傳回時,優先排程排隊請求。整體如圖5所示。

圖5 負載均衡演演算法
六、創新點及工程價值
-
1、consumer agent實現負載均衡和請求控制,能夠有效在consumer使用排隊機制端遏制過載,不把過載傳遞到網路傳輸上。
-
2、兩個agent間使用udp傳輸,利用udp的低損耗,因為是單包單請求,即使亂序也能隨意合併重組,丟包不會造成協議出錯,僅造成超時出錯,非常適合這種實時性和吞吐量要求高的情況。
-
3、在請求id中儲存了呼叫者和時間戳,能正確相應合適的http呼叫者的同時,能夠統計效能資料,作為調參依據。
-
4、多執行緒等待epoll的et樣式,能夠充分挖掘網絡卡通訊潛力,不存在單執行緒複製速度比網路傳輸慢的情況,同時省去了任務佇列,每個處理執行緒具備一定的CPU計算處理能力,也能最小化響應時間,使用自旋鎖後保證一個連線的訊息不會被多個執行緒處理,健壯性有保障。
-
5、設定合適的tcp緩衝區大小,在不阻塞情況下保證每次write呼叫都會成功。
複賽部分
一、 賽題重述及理解
複賽的主要考察點是單機實現100W規模的佇列資訊儲存與讀取,具體考察如何在單行程空間中的實現1M個佇列的資訊儲存,如何設計合理的資料儲存及索引結構,在特定硬碟的情況下完成高效能的順序寫、隨機讀和順序讀功能。同時由於測評環境是4C8G的,如何合理分配利用系統資源也是很重要的(任何對佇列儲存的東西都會放大100W倍,同時維護這麼多資料需要佔用更多的系統資源)。
針對上述考察點,本隊提出了一套完整的佇列訊息資料儲存方案,稀疏索引儲存方案。程式開發迭代中的總共提出了3套寫入方案,2套讀方案,分別在Java和C++平臺上進行了實現。
二、 整體系統架構
系統的整體結構較為簡單和清晰,主要分為以下幾個部分:每個佇列對應一個物件,用於維護buffer等必要結構;一個容器負責將佇列名對映到佇列物件;檔案管理物件負責維護讀寫檔案;負責整體讀寫狀態切換和管理的控制模組。如圖6所示。

圖6 複賽系統整體架構
三、 訊息儲存方案
考慮到順序寫、隨機讀、順序讀的使用場景,參考檔案系統以簇為單位的檔案儲存方式,設計了以塊為單位的佇列訊息儲存方式。

圖7 佇列訊息儲存方式
考慮到不定長訊息及超長訊息的情況,設計了變長整形+訊息體的結構記錄單條訊息,同時支援跨塊的訊息。

圖8 訊息資料儲存方式
每個塊開頭都是變長整形,每個VarInt儲存的都是目前還剩的訊息體長度(便於快速跳過或判斷訊息是否繼續跨塊),這種結構支援任意長度的訊息,如果塊剩餘空間不足寫VarInt,則padding。
考慮到節省磁碟空間,在CPU充足的情況下,可以採用訊息資料壓縮,但是線上CPU緊張,考慮到通用性並未使用特化壓縮演演算法。實際測試中由於訊息生成效能及CPU效能的問題,未開啟壓縮功能,但在程式中預留了壓縮介面,以適應各種場合。圖9所示為預留的壓縮介面。

圖9 預留的壓縮介面
四、 佇列寫入方案
設計好了訊息儲存方案,剩下的就是合適的訊息讀寫方案了,由於讀取方案比較固定,而寫入由於系統資源的匱乏(4C8G),需要合理設計。
1、mmap方案(Java實現)(淘汰)
本方案使用取用計數機制控制mmap生命週期,同時mmap的塊儲存在hash cache(定長slot基於hash衝突淘汰的cache演演算法)中,cache也會增加取用計數,這樣在連續寫檔案時保證了較好cache命中率。實現結構如圖10所示。

圖10 mmap方案
-
優點:完全不用flush操作,因為讀寫都是取用mmap實現的。
-
缺點:由於page cache臟超過20%會block寫入執行緒,為了不阻塞執行緒,佇列塊的大小必須非常小(512bytes,1M佇列512MB),效能較差。
2、整體記憶體取用方案(Java實現)(淘汰)
考慮到mmap直接作用在page cache上,受臟頁比例影響,難以提升緩衝大小,故考慮使用整體記憶體方案,機制和mmap類似。同樣使用取用計數機制控制寫入緩衝區記憶體塊的生命週期,額外使用獨立執行緒負責將緩衝區刷盤。該方法能夠等待新緩衝區記憶體塊有效保障不寫入過載,同時使用環形緩衝實現記憶體塊及等待物件復用。使用2K大小block的java程式線上成績為167w。方案整體流程如圖11所示。

圖11整體記憶體取用方案
-
優點:沒有額外複製,非同步寫入不會阻塞。
-
缺點:由於記憶體限制,存在寫入執行緒等待刷盤資料釋放,block大小受限制(2K,如果使用4K則會存在寫入等待記憶體交換出來,寫入有波動,效能不是最優)。
3、分片記憶體池方案(C++實現)(最優成績)
綜合前2種方案後,提出採用分片記憶體池+iovec記憶體重組寫入的方案。具體實現為將block分為更小的slice,每次緩衝區申請一個slice,寫滿一個block後用iovec提交。
寫入執行緒將提交的slice用iovec拼接成更大的part,整體寫入磁碟。寫入後將slice釋放回記憶體池便於後續佇列緩衝使用。雖然均勻寫入是一種糟糕的寫入方式,存在緩衝申請激增的情況,但由於分片機制的存在,每次激增為1M*slice的大小,可以透過slice大小控制。具體流程如圖12,13所示。

圖12分片記憶體池方案
-
優點:更細粒度的記憶體分配和釋放,4K大小block情況下緩衝區能均勻移動,不會阻塞,寫入和落盤同步進行;能在有限記憶體中實現更大的block。
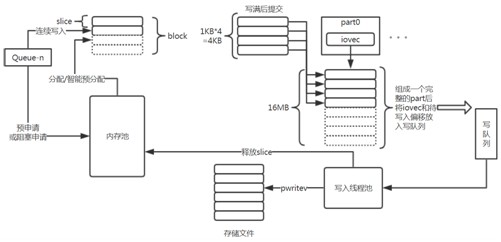
圖13 分片記憶體方案細節
內部使用的ring buffer方案及程式碼如圖14所示,所有物件均實現了復用。

圖14 ring buffer實現細節
五、 索引方案
由於記憶體空間限制,索引記錄所有訊息的偏移並不是個好方案。本系統方案採用了稀疏索引,因為設計的訊息儲存結構保證塊內訊息能夠自行區分,僅記錄塊資訊即可。只要能知道訊息所在的塊的位置和訊息是該塊的第幾個即可定位到該訊息。
每個訊息塊僅需要記錄3個資訊:塊所在檔案偏移(塊號);塊內訊息數;上個塊訊息是否跨塊。透過索引定位到具體訊息資料的方法也十分簡單。
-
1、透過從前往後累加每個塊的訊息數量,快速定位到訊息所在塊;
-
2、透過索引查詢到塊所在檔案偏移,並完整讀出塊(4K讀);
-
3、透過是否跨塊資訊和標的訊息ID,確定需要跳過的訊息數,快速跳過無用訊息。
-
4、讀取標的訊息。具體流程如圖15所示。

圖15 訊息資料定位流程
定位完成後可以連續讀,一旦發現長度超出當前塊,則說明讀到跨塊訊息,繼續切到下一塊讀取即可。
六、 隨機讀與連續讀
隨機讀取的訊息落到一個塊內有較大的機率,故即使是讀一個小範圍的資料,大部分情況能一次IO讀取完成。針對連續讀,記錄每次讀取到的位置,如果下次訪問是從0或上次讀取的位置,則認為是連續消費,對佇列的下一個塊發起readahead操作,將其讀入到page cache中,實測可以提升40%效能。由於塊的大小是4K,連續讀時不會讀入任何無效資料,作業系統的page cache能提供非常高的讀取效能。
七、 Map容器最佳化
由於訊息寫入介面是以佇列名對佇列進行區分的,佇列名到佇列物件的對映也是系統的瓶頸所在。針對數字字尾佇列名進行特殊hash計算處理,可以降低衝突機率。對於字尾計算hash衝突的情況,使用正常雜湊計算,離散到32個加鎖的unordered map中進行儲存,保證魯棒性和效能。由於字尾的區分度高,spin lock基本沒有衝突,100W插入比傳統map快幾百ms,100W查詢快幾十ms。Suffix map結構如圖16所示。

圖16 suffix map結構
八、 讀寫狀態切換
程式一開始就設計有記憶體和磁碟協同工作的程式碼,但由於緩衝佔用記憶體過大,使得後續隨機讀和連續讀(依賴page cache)存在效能下降的問題,採用了讀之前將緩衝全部落盤的策略。
在第一次讀的時候,block所有讀執行緒,落盤,釋放所有緩衝記憶體(~5.5G)然後開始讀取操作。由於空餘緩衝是全部填充padding的,即使再寫入佇列,資料也不會出錯。同時整體狀態可以切換回寫狀態(需重新申請緩衝記憶體)。
九、 創新性與工程價值
-
1、針對記憶體不足使用記憶體分片+iovec重組寫技術,達到在小記憶體的情況下寫記憶體和寫硬碟同時進行的目的,極大提升了寫磁碟效能。線上測試寫時存在CPU idle>0現象,說明生產已大於寫盤速度。
-
2、針對佇列名稱改進了map,提出suffix map,針對字尾進行hash(現實情況下也大量存在編號結尾的佇列名),極大降低了hash碰撞機率(測評資料中沒有碰撞),同時用自旋鎖和多個細粒度的unordered_map處理了碰撞情況,提升效能的時候保證了map的正確性魯棒性。
-
3、先寫緩衝,緩衝滿了排隊,最後填滿一個大block後刷盤,極大利用了SSD順序寫入效能,同時在佇列不均勻時也能提供同樣的高效能。
-
4、變長整形+訊息儲存,及跨塊訊息,超長訊息的處理機制保證任意長度訊息都能正確處理,並有同樣的高效能。
-
5、稀疏索引,只對塊的偏移和訊息數量做記錄,整個索引大小僅29*(4(blockId)+2(number))*1000000≈166MB,完全可以儲存在記憶體中。
-
6、使用ring buffer,分散寫入和等待物件,採用取用機制(最後釋放取用的執行緒負責提交該塊到寫入佇列中),工作期間沒有任何物件建立和銷毀,建立在陣列上,充分利用cpu cache,提升了效能。
-
7、整體記憶體分配,然後分片,使用完成後整體釋放,降低了記憶體管理的cpu消耗。
-
8、設計時考慮了緩衝和磁碟協同工作讀,不用將緩衝刷盤僅僅只用等待當前io完成,正確性可以保證,但由於佔用太多記憶體,效能不好,故後期改為全刷盤操作。
-
9、設計時候考慮了佇列索引自增漲演演算法,但由於tcmalloc分配記憶體不釋放,後面改為定長的了(有宏控制開關)。
-
10、所有長度,池大小等引數都可以拿宏修改,可以修改適應大記憶體等各種情況。
本號對所涉及的技術做了總結、彙總和打包(20+本),請識別小程式或點選原文連結獲取電子書詳細資訊。

推薦閱讀
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲閱讀原文瞭解更多。

求知若渴, 虛心若愚

