
專欄介紹:《香儂說》為香儂科技打造的一款以機器學習與自然語言處理為專題的訪談節目。由斯坦福大學,麻省理工學院, 卡耐基梅隆大學,劍橋大學等知名大學計算機系博士生組成的“香儂智囊”撰寫問題,採訪頂尖科研機構(斯坦福大學,麻省理工學院,卡耐基梅隆大學,谷歌,DeepMind,微軟研究院,OpenAI 等)中人工智慧與自然語言處理領域的學術大牛, 以及在博士期間就做出開創性工作而直接進入頂級名校任教職的學術新星,分享他們廣為人知的工作背後的靈感以及對相關領域大方向的把控。
本期採訪嘉賓是斯坦福大學計算機系教授 Percy Liang。隨後我們計劃陸續推出 Eduard Hovy(卡耐基梅隆大學),Dan Jurafsky(斯坦福大學),Anna Korhonen(劍橋大學),吳恩達(斯坦福大學),Ilya Sukskever (OpenAI),William Yang Wang(加州大學聖芭芭拉分校),Jason Weston(Facebook人工智慧研究院),Steve Young(劍橋大學)等人的訪談,敬請期待。
斯坦福大學計算機系助理教授、斯坦福人工智慧實驗室成員 Percy Liang 主要研究方向為自然語言處理(對話系統,語意分析等方向)及機器學習理論,他與他的學生合作的論文剛剛獲得 ACL 2018 短論文獎,其本人亦是 2016 年 IJCAI 計算機和思想獎(Computers and Thought Award)得主。
Percy 的團隊推出的 SQuAD 閱讀理解挑戰賽是行業內公認的機器閱讀理解標準水平測試,也是該領域的頂級賽事,被譽為機器閱讀理解界的 ImageNet(影象識別領域的頂級賽事)。參賽者來自全球學術界和產業界的研究團隊,包括微軟亞洲研究院、艾倫研究院、IBM、Salesforce、Facebook、谷歌以及卡內基·梅隆大學、斯坦福大學等知名企業研究機構和高校,賽事對自然語言理解的進步有重要的推動作用。
香儂科技:SQuaD (The Stanford Question Answering Dataset) 在推進機器閱讀理解和問答領域非常成功。然而,除了可以被 NLP 研究者用來開發更好的閱讀理解系統,你認為這個資料集是否潛藏著其他機會?
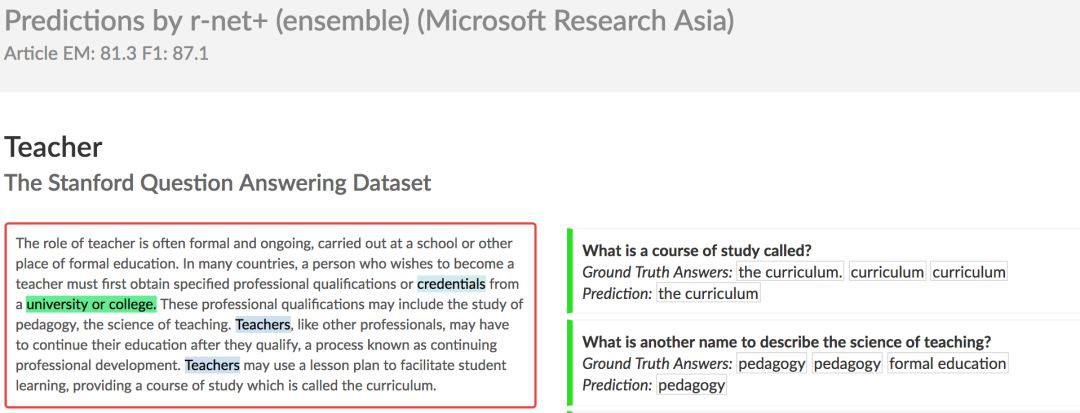
▲ 圖1. SQuaD中的樣本舉例
Percy:雖然 SQuaD(實際上,任何閱讀理解資料集)名義上都是關於閱讀理解的,但我認為它們可以有兩個方面更廣泛的影響:第一,資料集鼓勵人們開發新的通用模型。例如,神經機器翻譯產生了基於註意力的模型,這在機器學習領域裡如今已成為最常見的模型之一。第二,在一個資料集上訓練的模型對其他任務是有價值的。例如,在 ImageNet 上訓練摺積神經網路,模型會學習到可用於各種視覺問題的通用影象特徵。
SQuaD 所帶來的影響與上面列出的兩個例子類似(儘管可能不及它們那麼大)。SQuaD 已經達到了極限,因為多個系統已經超過了這個資料集上的人類水平。
但是,正如 Robin Jia 和我在 EMNLP 2017 的一篇論文中所展示的那樣,這樣的系統可以很容易地被對抗樣本所愚弄,在即將到來的 ACL 2018 中,我們有一篇論文將釋出 SQuaD 2.0,它包含 5 萬個額外的問題,它們看起來像是有答案的問題,但實際上沒有答案。希望這樣一個新的資料集,與最新層出不窮的其他資料集(例如,RACE、TriviaQA 等)的出現,將有助於推動該領域的進步。
香儂科技:過去您和您的學生已經做了許多非常有影響力的關於人工智慧安全的工作(Raghunathan et al. ICLR 2018,Steinhardt et al. NIPS 2017)。同時,您還對神經網路的可解釋性進行了研究,包括 Koh et al., ICML 2017 最佳論文。您認為提高深度神經網路的解釋性有助於解決人工智慧的安全問題嗎?為什麼?
Percy:到目前為止,人工智慧研究的主要驅動力一直是獲得預測更準確的模型。但是,最近可解釋性和魯棒性/安全性的問題得到了更多的關註,我認為這是特別重要的,因為機器學習現在的很多應用往往涉及生命安全,非同兒戲。如自主駕駛、醫療保健等。
然而,可解釋性和魯棒性是模糊的術語,人們對它們並沒有統一的定義。在這一點上,我認為仍然有許多概念性工作要做,使這些術語形式化,這樣人們才可以做出可量化的進步。我們已經透過使用影響函式(influence functions, Koh et al. ICML 2017)和半定鬆弛(Raghunathan et al. ICLR 2018)在形式化這些術語方面取得了一些初步的進展,而這兩種方法都是統計和最佳化的經典工具。我認為機器學習仍然是一種“雛形”階段;它距離成為一個成熟的工程學科還有一段路程要走。
香儂科技:您的許多自然語言處理研究與人類語言處理有著密切的聯絡(例如,Wang et al., ACL 2016 傑出論文獎:透過人機互動使機器從零開始學習語言,He et al. ACL 2017: 透過學習動態知識圖譜嵌入來構建對稱合作型聊天機器人)。您認為理解人類語言處理在何種程度上會幫助我們建立更好的機器語言處理系統?
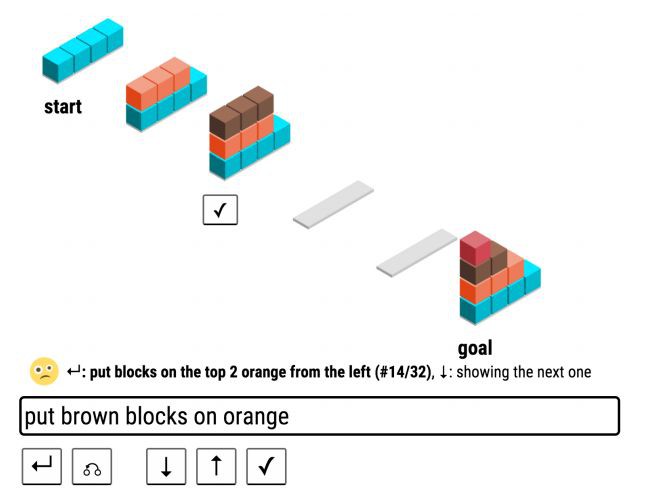
▲ 圖2. Wang et al. ACL 2016 中的 SHRDLURN 語言遊戲:機器需透過與人互動從零開始學習語言。
Percy:的確,我們有很多情況下利用眾包或直接讓模型與人類互動來學習語言,這是因為從根本上講,語言是關於與人的交流的。有時候,我覺得這一點在 NLP 社群中是缺失的。現在大部分的工作都是基於大資料的任務——機器翻譯、問答、資訊提取。這與人類如何透過語言來學習新的知識能力,和完成任務有很大的不同。
我認為,理解語言的目的不是簡簡單單地模仿人類。而是,如果我們想要建立可以與人類互動的系統,這些系統從根本上需要理解人類是如何思考和行動的,至少是在行為層面上。溝通和語言並不僅僅是關於詞語,而是關於詞語背後的個體和他們的標的。
香儂科技:正如您在您的網站上提到的,您是一個強烈支援高效和可重覆性研究的人。您一直在致力於開發 CodaLab Worksheets,這是可以使研究人員完整記錄一個實驗從原始資料到最終結果的全過程的平臺。您認為在機器學習中可重覆性研究的最大障礙是什麼?我們應該怎麼突破它們?

▲ 圖3. CodaLab工作原理,詳見CodaLab官方網站:https://worksheets.codalab.org/
Percy:可重覆性在所有科學領域都是一個巨大的問題,人工智慧也不例外,雖然我認為作為人工智慧研究者,我們真的沒有任何藉口——這一切只是在資料上跑程式碼。這個領域確實在開放程式碼和資料上有了很大的進步,但是往往程式碼和資料是不足以再現一篇論文的結果的,因為程式碼是如何執行的可能沒有被記錄下來。
CodaLab 透過跟蹤程式碼實際執行的整個過程,可以保證最終結果是由該程式碼和資料產生的。我們試圖使 CodaLab 盡可能方便易用——人們可以使用任何程式語言、資料格式等。
然而,挑戰仍然存在:人們還沒有足夠的動力去達到這種程度的可重覆性。即使大家都知道,這樣其實是更好的,因為存在網路效應——如果每個人都是用 CodaLab 來達到更高的可重覆性,那麼在別人的工作基礎上開發自己的模型就會容易得多,而且研究的速度也會大大加快。我認為這一切只是時間的問題。
香儂科技:在加入斯坦福大學之前,您從加州大學伯克利分校獲得博士學位,併在谷歌做過一段時間博士後。作為一個機器學習的研究者,您的思維方式是如何隨著時間的推移而改變的?
Percy:當我讀博士的時候,我非常喜歡機器學習的建模、演演算法和分析。但是我意識到即使是很強的演演算法也是有侷限性的:你會看到系統所犯的錯誤,然後你意識到如果只有一個固定的資料集你可能就是做不出來最完善的演演算法。後來我在斯坦福大學的時候(也是部分源於我在谷歌的時間的影響),我開始將資料-建模兩件事放在一起思考。儘管人們可能認為不存在資料短缺的問題(畢竟,這不是大資料時代嗎),事實上,擁有大量的好用的資料仍是一個挑戰。
我們已經提出了許多能夠改變這一問題的方法(例如,在 Wang et al., ACL 2015 中,我們有一篇論文研究瞭如何透過讓人們改述句子而不是註釋邏輯形式的方式來構建語意分析器)。把資料和建模放在一起思考可以拓寬解決方案的各種可能,讓你更有創造力。

▲ 圖4. 透過讓人們改述句子而不是註釋邏輯形式的方式來快速構建語意分析器 (圖片來源於Wang et al., ACL 2015)
香儂科技:作為一個機器學習的研究者,您認為最令人興奮的是什麼事情?
Percy:研究機器學習使你既能思考潛在的數學原理,又能思考如何對社會產生真正的積極影響。
香儂科技:作為一個機器學習的研究者,您認為最令人沮喪的是什麼事情?
Percy:有時你只是在黑暗中探險。你看到一個系統的錯誤,你會做一些試圖修複它們的事情,然而並沒有什麼改進。在某種意義上,當你不理解一個東西的內在機制時,你才會使用機器學習,因為這個東西的機制太複雜了(不然的話你就直接寫一個程式了)。
香儂科技:剛進入 NLP 領域的學生來說,該如何培養對於科研專案的品味?
Percy:學習基本原理並廣泛閱讀,尤其是在 NLP 和 AI 之外,你永遠不知道從程式語言、語言學、認知科學、最佳化、統計學中得到的想法是否與你正在做的事情有關。
人總是很容易被那些很酷炫的模型帶偏,會在自己的研究中加入各種華麗複雜的演演算法——你應該試圖做相反的事情:用簡單的方法解決問題比用複雜的方法解決問題更令人嘆服。
選擇一個你心懷信仰的問題,並滿懷激情去探索它。你會知道是它,因為它會讓你夜不能寐,一直想一直想。把這個問題變成一個屬於你的問題,你的私人珍藏。

香儂招聘
香儂科技 (http://shannon.ai/) ,是一家深耕金融領域的人工智慧公司,旨在利用機器學習和人工智慧演演算法提取、整合、分析海量金融資訊,讓 AI 為金融各領域賦能。
公司在 2017 年 12 月創立,獲紅杉中國基金獨家數千萬元融資。創始人之一李紀為是斯坦福大學計算機專業歷史上第一位僅用三年時間就獲得博士的人。過去三年 Google ScholarCitation>1,800,h-index達21。公司碩士以上比例為 100%,博士佔比超 30%,成員皆來自斯坦福、MIT、CMU、Princeton、北京大學、清華大學、人民大學、南開大學等國內外知名學府。
全職或實習加入香儂研發團隊,請點選檢視香儂招聘貼
簡歷投遞郵箱:hr@shannonai.com
Tips:聽說在郵件標題中註明“PaperWeekly”,能大大提升面試邀約率
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群刷論文
