自從三月份生產、非生產全面上線 Kubernetes 後,本以為部署的問題可以舒一口氣了,但是斷斷續續在生產、非生產環境發現一個詭異的問題,這禮拜又除錯了三天,在快要放棄的時候居然找到原因了,此缺陷影響目前(2018-5-23)為止所有 Kubernetes 版本(見後面更新,誇大了),包括 GitHub 當前 master 分支[1],後果是某種情況觸發下,Kubernetes service 不能提供服務,影響非常惡劣。
問題的現象是,在某種情況下,一個或者多個 Kubernetes service 對應的 Kubernetes endpoints 消失幾分鐘至幾十分鐘,然後重新出現,然後又消失,用 “kubectl get ep –all-namespaces” 不斷查詢,可以觀察到一些 AGE 在分鐘級別的 endpoints 要麼忽然消失,要麼 AGE 突然變小從一分鐘左右起步。Endpoints 的不穩定,必然導致對應的 Kubernetes service 無法穩定提供服務。有人在 GitHub 上報告了 issue[2],但是一直沒得到開發人員註意和解決。
首先解釋下 Kubernetes 大體上的實現機制,有助於理解下麵的破案過程。
Kubernetes 的實現原理跟配置管理工具 CFengine、Ansible、Salt 等非常類似:configuration convergence——不斷的比較期望的配置和實際的配置,修訂實際配置以收斂到期望配置。
Kubernetes 的關鍵系統服務有 api-server、scheduler、controller-manager 三個。api-server 一方面作為 Kubernetes 系統的訪問入口點,一方面作為背後 etcd 儲存的代理伺服器,Kubernetes 裡的所有資源物件,包括 Service、Deployment、ReplicaSet、DaemonSet、Pod、Endpoint、ConfigMap、Secret 等等,都是透過 api-server 檢查格式後,以 protobuf 格式序列化並存入 etcd。這就是一個寫入“期望配置”的過程。
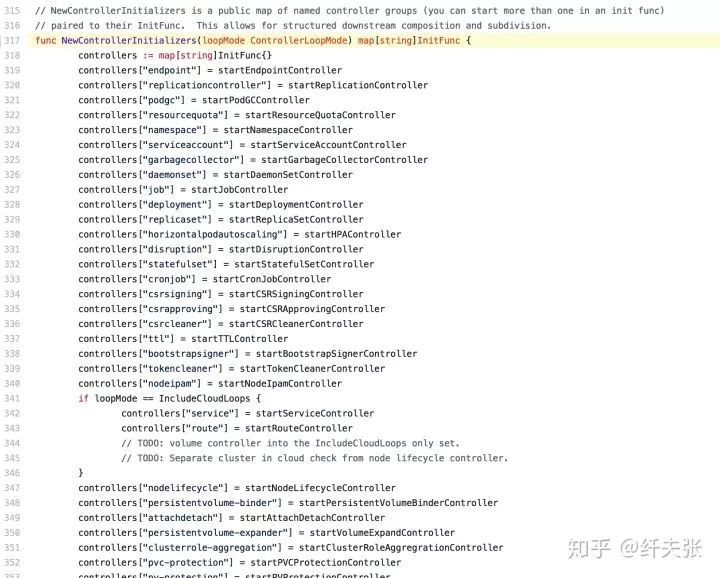
Controller-manager 服務裡包含了很多 controller 實體,對應各種資源型別:
v1.12.0-alpha.0/cmd/kube-controller-manager/app/controllermanager.go#L317
這些 controller 做的事情就是收斂:它透過 api-server 的 watch API 去間接的 watch etcd,以收取 etcd 裡資料的 changelog,對改變(包括ADD、DELETE、UPDATE)的資源(也就是期望的“配置“),逐個與透過 kubelet + Docker 收集到的資訊(實際“配置”)做對比並修正差異。
比如 etcd 裡增加了一個 Pod 資源,那麼 controller 就要請求 scheduler 排程,然後請求 kubelet 建立 Pod,如果etcd裡刪除了一個 Service 資源,那麼就要刪除其對應的 endpoint 資源,而這個 endpoint 刪除操作會被 kube-proxy 監聽到而觸發實際的 iptables 命令。
註意上面 controller 透過 watch 獲取 changelog 只是一個實現上的最佳化,它沒有周期性的拿出所有的資源物件然後逐個判斷,在叢集規模很大時,這樣的全量收斂是很慢的,後果就是叢集的排程、自我修複進行的非常慢。
有了大框架的理解後,endpoints 被誤刪的地方是很容易找到的:
v1.12.0-alpha.0/pkg/controller/endpoint/endpoints_controller.go#L396
然後問題來了,什麼情況下那個 Services(namespace).Get(name) 會傳回錯誤呢?透過註釋,可以看到在 service 刪除時會走到 397 行裡去,把無用的 endpoints 刪掉,因為 endpoint 是給 service 服務的,service 不存在時,endpoint 沒有存在的意義。
然後問題來了,透過 “kubectl get svc” 可以看到出問題期間,服務資源一直都在,並沒有重建,也沒有剛剛部署,甚至很多服務資源都是建立了幾個月,為啥它對應的 endpoints 會被誤刪然後重建呢?這個問題困擾了我兩個月,花了很長時間和很多腦細胞,今天在快放棄時突然有了重大發現。
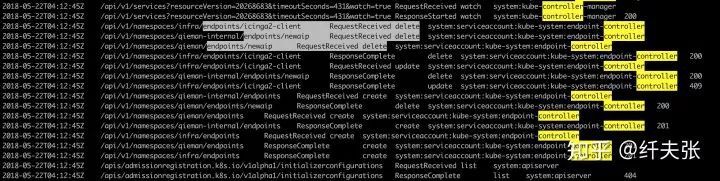
由於我司搭建的 Kubernetes 叢集開啟了 X509 認證以及 RBAC 許可權控制,為了便於審查,我開啟了 kube-apiserver 的審計日誌,在出問題時,審計日誌中有個特別的樣式:
審計日誌中,在每個 endpoint delete & create 發生前,都有一個 “/api/v1/services…watch=true” 的 watch 呼叫,上面講到,controller-manager 要不斷的去爬 etcd 裡面資源的 changelog,這裡很奇怪的問題是,這個呼叫的 “resourceVersion=xxx” 的版本值始終不變,難道不應該不斷從 changelog 末尾繼續爬取因為 resourceVersion 不斷遞增麼?
透過一番艱苦卓絕的連猜帶蒙,終於找到“爬取changelog”對應的程式碼[3]:
v1.12.0-alpha.0/staging/src/k8s.io/client-go/tools/cache/reflector.go#L394
上面的程式碼對 resourceVersion 的處理邏輯是: 遍歷 event 串列,取當前 event 的 “resourceVersion” 欄位作為新的要爬取的“起始resourceVersion”,所以很顯然遍歷結束後,”起始resourceVersion” 也就是最後一條 event 的 “resourceVersion”。
好了,我們來看看 event 串列漲啥樣,把上面 api-server 的請求照搬就可以看到了:
kubectl proxy
curl -s localhost:8001/api/v1/services?resourceVersion=xxxx&timeoutSeconds;=yyy&watch;=true
/api/v1/services 的輸出,僅示意,註意跟上面的審計日誌不是同一個時間段的
可以很明顯看到,坑爹,resourceVersion 不是遞增的!
這個非遞增的問題其實很容易想明白,resourceVersion 並不是 event 的序列號,它是 Kubernetes 資源自身的版本號,如果把 etcd 看作 Subversion,兩者都有一個全域性遞增的版本號,把 Kubernetes 資源看作 Subversion 裡儲存的檔案。 在 svn revision=100 時存入一個檔案 A,那麼A的版本是 100,然後不斷提交其它檔案的修改到 svn,然後在某個版本刪掉 A,此時用 svn log 看到的相關檔案的“自身最後一次修改版本”並不是遞增的,最後一條的“自身最後一次修改版本”是 100。
所以真相大白了,reflector.go 那段遍歷 etcd “changelog” 的程式碼,誤以為 event 序列的 resourceVersion 是遞增的了,雖然絕大部分時候是這樣的。由於這段程式碼是通用的,所有資源都受這個影響,所以是非常嚴重的 bug,之前看到很多人報告(我自己也遇到)controller-manager 報錯 “reflector.go:341] k8s.io/kubernetes/pkg/controller/bootstrap/bootstrapsigner.go:152: watch of *v1.ConfigMap ended with: too old resource version: ” 很可能也是這個導致的,因為它失誤從很老的 resourceVersion 開始爬取 etcd “changelog”,但 etcd 已經把太老的 changelog 給 “compact” 掉了。
陸續建立、刪除、建立 Kubernetes service 物件,然後”kubectl delete svc xxx”刪掉建立時間靠前的 service,也就是往 service event list 末尾插入了一條 resourceVersion 比較小的記錄,這將使得 controller-manager 去從已經爬過的 service event list 位置重新爬取重放,然後就重放了 service 的 ADDED、DELETED event,於是 controller-manager 記憶體裡快取的 service 物件被刪除,導致 EndpointController 刪除了“不存在的”service 對應的 endpoints。
-
用 docker restart 重啟 kube-controller-manager 容器,強迫其從 event list 最新位置開始爬取。
-
建立一個 service,其 resourceVersion 會是 etcd 的最新全域性版本號,這個 ADDED event 會出現在 event list 末尾,從而 controller-manager 從這個最新的 resourceVersion 開始爬取。
-
“kubectl edit” 修改某個 service,加點無意義的 label 之類的,儲存,這樣其 resourceVersion 也會更新,之後跟上一個 workaround 原理一樣了。
Kubernetes 裡凡是建立後基本不變的資源,比如 service、configmap、secrets 都會受這個影響,它們的版本號都很久,刪一個後都會觸發這個 bug,比如 configmap,可能就會被重覆的更新,對映到容器裡的 config file 也就不斷更新,對於不支援 config hot reload 的服務沒有影響,對於支援 config hot reload 的服務,會頻繁的重新載入配置檔案重新初始化,可能導致意想不到的問題。
Bug 的修複很簡單,在遍歷 event list 選擇 resourceVersion 時,總是取 max(event.resourceVersion, currentResourceVersion) 即可,我提了個 pull request 給 Kubernetes 官方看看,希望我這個粗暴的修正不會帶來新的問題。
【更新】:avoid wrongly replaying old events in kube-controller-manager by Dieken · Pull Request #64209 · kubernetes/kubernetes[4] 官方開發同學很快指出這個問題已經修正了,就在 1.9.3,我正好用的 1.9.2,看了下 1.9.3 的更新說明,他媽的輕描淡寫啊!
Fixes an issue where the resourceVersion of an object in a DELETE watch event was not the resourceVersion of the delete itself, but of the last update to the object. This could disrupt the ability of clients clients to re-establish watches properly. (#58547[5], @liggitt[6])
按 liggitt 的說法,升級到這些版本就好了:v1.8.8+、v1.9.3+ and v1.10.0+。
-
https://github.com/kubernetes/kubernetes/tree/eacf6f05b1b6995c5f8bd04ab35861340c7fef08
-
https://github.com/kubernetes/kubernetes/issues/57897
-
https://github.com/kubernetes/kubernetes/blob/v1.12.0-alpha.0/staging/src/k8s.io/client-go/tools/cache/reflector.go#L394
-
https://github.com/kubernetes/kubernetes/pull/64209#issuecomment-391403378
-
https://github.com/kubernetes/kubernetes/pull/58547
-
https://github.com/liggitt
原文連結:https://zhuanlan.zhihu.com/p/37217575

本次培訓內容包括:Docker基礎、容器技術、Docker映象、資料共享與持久化、Docker三駕馬車、Docker實踐、Kubernetes基礎、Pod基礎與進階、常用物件操作、服務發現、Helm、Kubernetes核心元件原理分析、Kubernetes服務質量保證、排程詳解與應用場景、網路、基於Kubernetes的CI/CD、基於Kubernetes的配置管理等,點選瞭解具體培訓內容。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。