- 一、微服務介紹
- 二、微服務實踐先知
- 三、微服務重要部件
一、微服務介紹
1. 什麼是微服務
在介紹微服務時,首先得先理解什麼是微服務,顧名思義,微服務得從兩個方面去理解,什麼是”微”、什麼是”服務”, 微 狹義來講就是體積小、著名的”2 pizza 團隊”很好的詮釋了這一解釋(2 pizza 團隊最早是亞馬遜 CEO Bezos提出來的,意思是說單個服務的設計,所有參與人從設計、開發、測試、運維所有人加起來 只需要2個披薩就夠了 )。 而所謂服務,一定要區別於系統,服務一個或者一組相對較小且獨立的功能單元,是使用者可以感知最小功能集。
2. 微服務由來
微服務最早由Martin Fowler與James Lewis於2014年共同提出,微服務架構風格是一種使用一套小服務來開發單個應用的方式途徑,每個服務執行在自己的行程中,並使用輕量級機制通訊,通常是HTTP API,這些服務基於業務能力構建,並能夠透過自動化部署機制來獨立部署,這些服務使用不同的程式語言實現,以及不同資料儲存技術,並保持最低限度的集中式管理。
3. 為什麼需要微服務?
在傳統的IT行業軟體大多都是各種獨立系統的堆砌,這些系統的問題總結來說就是擴充套件性差,可靠性不高,維護成本高。到後面引入了SOA服務化,但是,由於 SOA 早期均使用了匯流排樣式,這種匯流排樣式是與某種技術棧強系結的,比如:J2EE。這導致很多企業的遺留系統很難對接,切換時間太長,成本太高,新系統穩定性的收斂也需要一些時間。最終 SOA 看起來很美,但卻成為了企業級奢侈品,中小公司都望而生畏。
3.1 最期的單體架構帶來的問題
單體架構在規模比較小的情況下工作情況良好,但是隨著系統規模的擴大,它暴露出來的問題也越來越多,主要有以下幾點:
1.複雜性逐漸變高
- 比如有的專案有幾十萬行程式碼,各個模組之間區別比較模糊,邏輯比較混亂,程式碼越多複雜性越高,越難解決遇到的問題。
2.技術債務逐漸上升
- 公司的人員流動是再正常不過的事情,有的員工在離職之前,疏於程式碼質量的自我管束,導致留下來很多坑,由於單體專案程式碼量龐大的驚人,留下的坑很難被髮覺,這就給新來的員工帶來很大的煩惱,人員流動越大所留下的坑越多,也就是所謂的技術債務越來越多。
3.部署速度逐漸變慢
- 這個就很好理解了,單體架構模組非常多,程式碼量非常龐大,導致部署專案所花費的時間越來越多,曾經有的專案啟動就要一二十分鐘,這是多麼恐怖的事情啊,啟動幾次專案一天的時間就過去了,留給開發者開發的時間就非常少了。
4.阻礙技術創新
- 比如以前的某個專案使用struts2寫的,由於各個模組之間有著千絲萬縷的聯絡,程式碼量大,邏輯不夠清楚,如果現在想用spring mvc來重構這個專案將是非常困難的,付出的成本將非常大,所以更多的時候公司不得不硬著頭皮繼續使用老的struts架構,這就阻礙了技術的創新。
5.無法按需伸縮
- 比如說電影模組是CPU密集型的模組,而訂單模組是IO密集型的模組,假如我們要提升訂單模組的效能,比如加大記憶體、增加硬碟,但是由於所有的模組都在一個架構下,因此我們在擴充套件訂單模組的效能時不得不考慮其它模組的因素,因為我們不能因為擴充套件某個模組的效能而損害其它模組的效能,從而無法按需進行伸縮。
3.2 微服務與單體架構區別
- 單體架構所有的模組全都耦合在一塊,程式碼量大,維護困難,微服務每個模組就相當於一個單獨的專案,程式碼量明顯減少,遇到問題也相對來說比較好解決。
- 單體架構所有的模組都共用一個資料庫,儲存方式比較單一,微服務每個模組都可以使用不同的儲存方式(比如有的用redis,有的用mysql等),資料庫也是單個模組對應自己的資料庫。
- 單體架構所有的模組開發所使用的技術一樣,微服務每個模組都可以使用不同的開發技術,開發樣式更靈活。

3.3 微服務與SOA區別
微服務,從本質意義上看,還是 SOA 架構。但內涵有所不同,微服務並不繫結某種特殊的技術,在一個微服務的系統中,可以有 Java 編寫的服務,也可以有 Python編寫的服務,他們是靠Restful架構風格統一成一個系統的。所以微服務本身與具體技術實現無關,擴充套件性強。
4. 微服務本質
- 微服務,關鍵其實不僅僅是微服務本身,而是系統要提供一套基礎的架構,這種架構使得微服務可以獨立的部署、執行、升級,不僅如此,這個系統架構還讓微服務與微服務之間在結構上“松耦合”,而在功能上則表現為一個統一的整體。這種所謂的“統一的整體”表現出來的是統一風格的介面,統一的許可權管理,統一的安全策略,統一的上線過程,統一的日誌和審計方法,統一的排程方式,統一的訪問入口等等。
- 微服務的目的是有效的拆分應用,實現敏捷開發和部署 。
- 微服務提倡的理念團隊間應該是 inter-operate, not integrate 。inter-operate是定義好系統的邊界和介面,在一個團隊內全棧,讓團隊自治,原因就是因為如果團隊按照這樣的方式組建,將溝通的成本維持在系統內部,每個子系統就會更加內聚,彼此的依賴耦合能變弱,跨系統的溝通成本也就能降低。
5. 什麼樣的專案適合微服務
微服務可以按照業務功能本身的獨立性來劃分,如果系統提供的業務是非常底層的,如:作業系統核心、儲存系統、網路系統、資料庫系統等等,這類系統都偏底層,功能和功能之間有著緊密的配合關係,如果強制拆分為較小的服務單元,會讓整合工作量急劇上升,並且這種人為的切割無法帶來業務上的真正的隔離,所以無法做到獨立部署和執行,也就不適合做成微服務了。
能不能做成微服務,取決於四個要素:
- 小:微服務體積小,2 pizza 團隊。
- 獨:能夠獨立的部署和執行。
- 輕:使用輕量級的通訊機制和架構。
- 松:為服務之間是松耦合的。
6. 微服務折分與設計
- 從單體式結構轉向微服務架構中會持續碰到服務邊界劃分的問題:比如,我們有user 服務來提供使用者的基礎資訊,那麼使用者的頭像和圖片等是應該單獨劃分為一個新的service更好還是應該合併到user服務裡呢?如果服務的粒度劃分的過粗,那就回到了單體式的老路;如果過細,那服務間呼叫的開銷就變得不可忽視了,管理難度也會指數級增加。目前為止還沒有一個可以稱之為服務邊界劃分的標準,只能根據不同的業務系統加以調節
- 拆分的大原則是當一塊業務不依賴或極少依賴其它服務,有獨立的業務語意,為超過2個的其他服務或客戶端提供資料,那麼它就應該被拆分成一個獨立的服務模組。
6.1 微服務設計原則
單一職責原則
- 意思是每個微服務只需要實現自己的業務邏輯就可以了,比如訂單管理模組,它只需要處理訂單的業務邏輯就可以了,其它的不必考慮。
服務自治原則
- 意思是每個微服務從開發、測試、運維等都是獨立的,包括儲存的資料庫也都是獨立的,自己就有一套完整的流程,我們完全可以把它當成一個專案來對待。不必依賴於其它模組。
輕量級通訊原則
- 首先是通訊的語言非常的輕量,第二,該通訊方式需要是跨語言、跨平臺的,之所以要跨平臺、跨語言就是為了讓每個微服務都有足夠的獨立性,可以不受技術的鉗制。
介面明確原則
- 由於微服務之間可能存在著呼叫關係,為了儘量避免以後由於某個微服務的介面變化而導致其它微服務都做調整,在設計之初就要考慮到所有情況,讓介面儘量做的更通用,更靈活,從而儘量避免其它模組也做調整。
7. 微服務優勢與缺點
7.1 特性
- 每個微服務可獨立執行在自己的行程裡;
- 一系列獨立執行的微服務共同構建起了整個系統;
- 每個服務為獨立的業務開發,一個微服務一般完成某個特定的功能,比如:訂單管理,使用者管理等;
- 微服務之間透過一些輕量級的通訊機制進行通訊,例如透過REST API或者RPC的方式進行呼叫。
7.2 特點
易於開發和維護
- 由於微服務單個模組就相當於一個專案,開發這個模組我們就只需關心這個模組的邏輯即可,程式碼量和邏輯複雜度都會降低,從而易於開發和維護。
啟動較快
- 這是相對單個微服務來講的,相比於啟動單體架構的整個專案,啟動某個模組的服務速度明顯是要快很多的。
區域性修改容易部署
- 在開發中發現了一個問題,如果是單體架構的話,我們就需要重新釋出並啟動整個專案,非常耗時間,但是微服務則不同,哪個模組出現了bug我們只需要解決那個模組的bug就可以了,解決完bug之後,我們只需要重啟這個模組的服務即可,部署相對簡單,不必重啟整個專案從而大大節約時間。
技術棧不受限
- 比如訂單微服務和電影微服務原來都是用java寫的,現在我們想把電影微服務改成nodeJs技術,這是完全可以的,而且由於所關註的只是電影的邏輯而已,因此技術更換的成本也就會少很多。
按需伸縮
- 我們上面說了單體架構在想擴充套件某個模組的效能時不得不考慮到其它模組的效能會不會受影響,對於我們微服務來講,完全不是問題,電影模組透過什麼方式來提升效能不必考慮其它模組的情況。
7.3 缺點
運維要求較高
- 對於單體架構來講,我們只需要維護好這一個專案就可以了,但是對於微服務架構來講,由於專案是由多個微服務構成的,每個模組出現問題都會造成整個專案執行出現異常,想要知道是哪個模組造成的問題往往是不容易的,因為我們無法一步一步透過debug的方式來跟蹤,這就對運維人員提出了很高的要求。
分散式的複雜性
- 對於單體架構來講,我們可以不使用分散式,但是對於微服務架構來說,分散式幾乎是必會用的技術,由於分散式本身的複雜性,導致微服務架構也變得複雜起來。
介面調整成本高
- 比如,使用者微服務是要被訂單微服務和電影微服務所呼叫的,一旦使用者微服務的介面發生大的變動,那麼所有依賴它的微服務都要做相應的調整,由於微服務可能非常多,那麼調整介面所造成的成本將會明顯提高。
重覆勞動
- 對於單體架構來講,如果某段業務被多個模組所共同使用,我們便可以抽象成一個工具類,被所有模組直接呼叫,但是微服務卻無法這樣做,因為這個微服務的工具類是不能被其它微服務所直接呼叫的,從而我們便不得不在每個微服務上都建這麼一個工具類,從而導致程式碼的重覆。
8. 微服務開發框架
目前微服務的開發框架,最常用的有以下四個:
- Spring Cloud:http://projects.spring.io/spring-cloud(現在非常流行的微服務架構)
- Dubbo:http://dubbo.io
- Dropwizard:http://www.dropwizard.io (關註單個微服務的開發)
- Consul、etcd&etc.;(微服務的模組)
9. Sprint cloud 和 Sprint boot區別
Spring Boot:
旨在簡化建立產品級的Spring應用和服務,簡化了配置檔案,使用嵌入式web伺服器,含有諸多開箱即用微服務功能,可以和spring cloud聯合部署。
Spring Cloud:
微服務工具包,為開發者提供了在分散式系統的配置管理、服務發現、斷路器、智慧路由、微代理、控制匯流排等開發工具包。
二、微服務實踐先知
1. 客戶端如何訪問這些服務?(API Gateway)
傳統的開發方式,所有的服務都是本地的,UI可以直接呼叫,現在按功能拆分成獨立的服務,跑在獨立的一般都在獨立的虛擬機器上的 Java行程了。客戶端UI如何訪問他的?後臺有N個服務,前臺就需要記住管理N個服務,一個服務下線/更新/升級,前臺就要重新部署,這明顯不服務我們 拆分的理念,特別當前臺是移動應用的時候,通常業務變化的節奏更快。另外,N個小服務的呼叫也是一個不小的網路開銷。還有一般微服務在系統內部,通常是無狀態的,使用者登入資訊和許可權管理最好有一個統一的地方維護管理(OAuth)。
所以,一般在後臺N個服務和UI之間一般會一個代理或者叫API Gateway,他的作用包括
- 提供統一服務入口,讓微服務對前臺透明
- 聚合後臺的服務,節省流量,提升效能
- 提供安全,過濾,流控等API管理功能
- 我的理解其實這個API Gateway可以有很多廣義的實現辦法,可以是一個軟硬一體的盒子,也可以是一個簡單的MVC框架,甚至是一個Node.js的服務端。他們最重要的作用是為前臺(通常是移動應用)提供後臺服務的聚合,提供一個統一的服務出口,解除他們之間的耦合,不過API Gateway也有可能成為單點故障點或者效能的瓶頸。

2. 服務之間如何通訊?(服務呼叫)
因為所有的微服務都是獨立的Java行程跑在獨立的虛擬機器上,所以服務間的通行就是IPC(inter process communication),已經有很多成熟的方案。現在基本最通用的有兩種方式。這幾種方式,展開來講都可以寫本書,而且大家一般都比較熟悉細節了, 就不展開講了。
- REST(JAX-RS,Spring Boot)
- RPC(Thrift, Dubbo)
- 非同步訊息呼叫(Kafka, Notify)

一般同步呼叫比較簡單,一致性強,但是容易出呼叫問題,效能體驗上也會差些,特別是呼叫層次多的時候。RESTful和RPC的比較也是一個很有意 思的話題。一般REST基於HTTP,更容易實現,更容易被接受,服務端實現技術也更靈活些,各個語言都能支援,同時能跨客戶端,對客戶端沒有特殊的要 求,只要封裝了HTTP的SDK就能呼叫,所以相對使用的廣一些。RPC也有自己的優點,傳輸協議更高效,安全更可控,特別在一個公司內部,如果有統一個的開發規範和統一的服務框架時,他的開發效率優勢更明顯些。就看各自的技術積累實際條件,自己的選擇了。
而非同步訊息的方式在分散式系統中有特別廣泛的應用,他既能減低呼叫服務之間的耦合,又能成為呼叫之間的緩衝,確保訊息積壓不會衝垮被呼叫方,同時能 保證呼叫方的服務體驗,繼續乾自己該乾的活,不至於被後臺效能拖慢。不過需要付出的代價是一致性的減弱,需要接受資料最終一致性;還有就是後臺服務一般要 實現冪等性,因為訊息發送出於效能的考慮一般會有重覆(保證訊息的被收到且僅收到一次對效能是很大的考驗);最後就是必須引入一個獨立的broker,如 果公司內部沒有技術積累,對broker分散式管理也是一個很大的挑戰。
3. 這麼多服務怎麼查詢?(服務發現)
在微服務架構中,一般每一個服務都是有多個複製,來做負載均衡。一個服務隨時可能下線,也可能應對臨時訪問壓力增加新的服務節點。服務之間如何相互 感知?服務如何管理?這就是服務發現的問題了。一般有兩類做法,也各有優缺點。基本都是透過zookeeper等類似技術做服務註冊資訊的分散式管理。當 服務上線時,服務提供者將自己的服務資訊註冊到ZK(或類似框架),並透過心跳維持長連結,實時更新連結資訊。服務呼叫者透過ZK定址,根據可定製演演算法,找到一個服務,還可以將服務資訊快取在本地以提高效能。當服務下線時,ZK會發通知給服務客戶端。
客戶端做:優點是架構簡單,擴充套件靈活,只對服務註冊器依賴。缺點是客戶端要維護所有呼叫服務的地址,有技術難度,一般大公司都有成熟的內部框架支援,比如Dubbo。
服務端做:優點是簡單,所有服務對於前臺呼叫方透明,一般在小公司在雲服務上部署的應用採用的比較多。

4. 服務掛了怎麼辦?
分散式最大的特性就是網路是不可靠 的。透過微服務拆分能降低這個風險,不過如果沒有特別的保障,結局肯定是噩夢。我們剛遇到一個線上故障就是一個很不起眼的SQL計數功能,在訪問量上升 時,導致資料庫load彪高,影響了所在應用的效能,從而影響所有呼叫這個應用服務的前臺應用。所以當我們的系統是由一系列的服務呼叫鏈組成的時候,我們必須確保任一環節出問題都不至於影響整體鏈路。相應的手段有很多:
- 重試機制
- 限流
- 熔斷機制
- 負載均衡
- 降級(本地快取) 這些方法基本上都很明確通用,就不詳細說明瞭。比如Netflix的Hystrix:https://github.com/Netflix/Hystrix

5. 微服務需要考慮的問題
這裡有一個圖非常好的總結微服務架構需要考慮的問題,包括
- API Gateway
- 服務間呼叫
- 服務發現
- 服務容錯
- 服務部署
- 資料呼叫
三、微服務重要部件
1. 微服務基本能力

2. 服務註冊中心
服務之間需要建立一種服務發現機制,用於幫助服務之間互相感知彼此的存在。服務啟動時會將自身的服務資訊註冊到註冊中心,並訂閱自己需要消費的服務。
服務註冊中心是服務發現的核心。它儲存了各個可用服務實體的網路地址(IPAddress和Port)。服務註冊中心必須要有高可用性和實時更新功能。上面提到的 Netflix Eureka 就是一個服務註冊中心。它提供了服務註冊和查詢服務資訊的REST API。服務透過使用POST請求註冊自己的IPAddress和Port。每30秒傳送一個PUT請求掃清註冊資訊。透過DELETE請求登出服務。客戶端透過GET請求獲取可用的服務實體資訊。 Netflix的高可用(Netflix achieves high availability )是透過在Amazon EC2執行多個實體來實現的,每一個Eureka服務都有一個彈性IP Address。當Eureka服務啟動時,有DNS伺服器動態的分配。Eureka客戶端透過查詢 DNS來獲取Eureka的網路地址(IP Address和Port)。一般情況下,都是傳回和客戶端在同一個可用區Eureka伺服器地址。 其他能夠作為服務註冊中心的有:
- etcd —– 高可用,分散式,強一致性的,key-value,Kubernetes和Cloud Foundry都是使用了etcd。
- consul —–一個用於discovering和configuring的工具。它提供了允許客戶端註冊和發現服務的API。Consul可以進行服務健康檢查,以確定服務的可用性。
- zookeeper —— 在分散式應用中被廣泛使用,高效能的協調服務。 Apache Zookeeper 最初為Hadoop的一個子專案,但現在是一個頂級專案。
2.1 zookeeper服務註冊和發現
簡單來講,zookeeper可以充當一個服務登錄檔(Service Registry),讓多個服務提供者形成一個叢集,讓服務消費者透過服務登錄檔獲取具體的服務訪問地址(ip+埠)去訪問具體的服務提供者。如下圖所示:
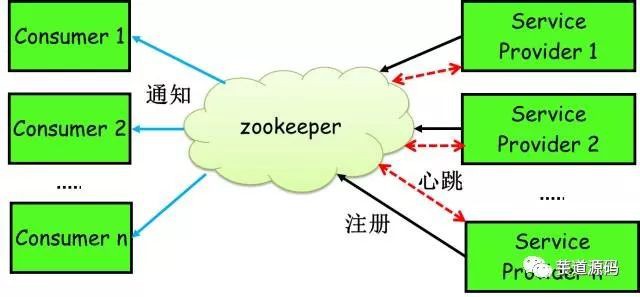
具體來說,zookeeper就是個分散式檔案系統,每當一個服務提供者部署後都要將自己的服務註冊到zookeeper的某一路徑上: /{service}/{version}/{ip:port}, 比如我們的HelloWorldService部署到兩臺機器,那麼zookeeper上就會建立兩條目錄:分別為/HelloWorldService/1.0.0/100.19.20.01:16888 /HelloWorldService/1.0.0/100.19.20.02:16888。
zookeeper提供了“心跳檢測”功能,它會定時向各個服務提供者傳送一個請求(實際上建立的是一個 socket 長連線),如果長期沒有響應,服務中心就認為該服務提供者已經“掛了”,並將其剔除,比如100.19.20.02這臺機器如果宕機了,那麼zookeeper上的路徑就會只剩/HelloWorldService/1.0.0/100.19.20.01:16888。
服務消費者會去監聽相應路徑(/HelloWorldService/1.0.0),一旦路徑上的資料有任務變化(增加或減少),zookeeper都會通知服務消費方服務提供者地址串列已經發生改變,從而進行更新。
更為重要的是zookeeper 與生俱來的容錯容災能力(比如leader選舉),可以確保服務登錄檔的高可用性。
3. 負載均衡
服務高可用的保證手段,為了保證高可用,每一個微服務都需要部署多個服務實體來提供服務。此時客戶端進行服務的負載均衡。
3.1 負載均衡的常見策略
3.1.1 隨機
把來自網路的請求隨機分配給內部中的多個伺服器。
3.1.2 輪詢
每一個來自網路中的請求,輪流分配給內部的伺服器,從1到N然後重新開始。此種負載均衡演演算法適合伺服器組內部的伺服器都具有相同的配置並且平均服務請求相對均衡的情況。
3.1.3 加權輪詢
根據伺服器的不同處理能力,給每個伺服器分配不同的權值,使其能夠接受相應權值數的服務請求。例如:伺服器A的權值被設計成1,B的權值是3,C的權值是6,則伺服器A、B、C將分別接受到10%、30%、60%的服務請求。此種均衡演演算法能確保高效能的伺服器得到更多的使用率,避免低效能的伺服器負載過重。
3.1.4 IP Hash
這種方式透過生成請求源IP的雜湊值,並透過這個雜湊值來找到正確的真實伺服器。這意味著對於同一主機來說他對應的伺服器總是相同。使用這種方式,你不需要儲存任何源IP。但是需要註意,這種方式可能導致伺服器負載不平衡。
3.1.5 最少連線數
客戶端的每一次請求服務在伺服器停留的時間可能會有較大的差異,隨著工作時間加長,如果採用簡單的輪循或隨機均衡演演算法,每一臺伺服器上的連線行程可能會產生極大的不同,並沒有達到真正的負載均衡。最少連線數均衡演演算法對內部中需負載的每一臺伺服器都有一個資料記錄,記錄當前該伺服器正在處理的連線數量,當有新的服務連線請求時,將把當前請求分配給連線數最少的伺服器,使均衡更加符合實際情況,負載更加均衡。此種均衡演演算法適合長時處理的請求服務,如FTP。
4. 容錯
容錯,這個詞的理解,直面意思就是可以容下錯誤,不讓錯誤再次擴張,讓這個錯誤產生的影響在一個固定的邊界之內,“千里之堤毀於蟻穴”我們用容錯的方式就是讓這種蟻穴不要變大。那麼我們常見的降級,限流,熔斷器,超時重試等等都是容錯的方法。
在呼叫服務叢集時,如果一個微服務呼叫異常,如超時,連線異常,網路異常等,則根據容錯策略進行服務容錯。目前支援的服務容錯策略有快速失敗,失效切換。如果連續失敗多次則直接熔斷,不再發起呼叫。這樣可以避免一個服務異常拖垮所有依賴於他的服務。
4.1 容錯策略
4.1.1 快速失敗
服務只發起一次待用,失敗立即報錯。通常用於非冪等下性的寫操作
4.1.2 失效切換
服務發起呼叫,當出現失敗後,重試其他伺服器。通常用於讀操作,但重試會帶來更長時間的延遲。重試的次數通常是可以設定的
4.1.3 失敗安全
失敗安全, 當服務呼叫出現異常時,直接忽略。通常用於寫入日誌等操作。
4.1.4 失敗自動恢復
當服務呼叫出現異常時,記錄失敗請求,定時重發。通常用於訊息通知。
4.1.5 forking Cluster
並行呼叫多個伺服器,只要有一個成功,即傳回。通常用於實時性較高的讀操作。可以透過forks=n來設定最大並行數。
4.1.6 廣播呼叫
廣播呼叫所有提供者,逐個呼叫,任何一臺失敗則失敗。通常用於通知所有提供者更新快取或日誌等本地資源資訊。
5. 熔斷
熔斷技術可以說是一種“智慧化的容錯”,當呼叫滿足失敗次數,失敗比例就會觸發熔斷器開啟,有程式自動切斷當前的RPC呼叫,來防止錯誤進一步擴大。實現一個熔斷器主要是考慮三種樣式,關閉,開啟,半開。各個狀態的轉換如下圖。

我們在處理異常的時候,要根據具體的業務情況來決定處理方式,比如我們呼叫商品介面,對方只是臨時做了降級處理,那麼作為閘道器呼叫就要切到可替換的服務上來執行或者獲取託底資料,給使用者友好提示。還有要區分異常的型別,比如依賴的服務崩潰了,這個可能需要花費比較久的時間來解決。也可能是由於伺服器負載臨時過高導致超時。作為熔斷器應該能夠甄別這種異常型別,從而根據具體的錯誤型別調整熔斷策略。增加手動設定,在失敗的服務恢復時間不確定的情況下,管理員可以手動強制切換熔斷狀態。最後,熔斷器的使用場景是呼叫可能失敗的遠端服務程式或者共享資源。如果是本地快取本地私有資源,使用熔斷器則會增加系統的額外開銷。還要註意,熔斷器不能作為應用程式中業務邏輯的異常處理替代品。
有一些異常比較頑固,突然發生,無法預測,而且很難恢復,並且還會導致級聯失敗(舉個例子,假設一個服務叢集的負載非常高,如果這時候叢集的一部分掛掉了,還佔了很大一部分資源,整個叢集都有可能遭殃)。如果我們這時還是不斷進行重試的話,結果大多都是失敗的。因此,此時我們的應用需要立即進入失敗狀態(fast-fail),並採取合適的方法進行恢復。
我們可以用狀態機來實現CircuitBreaker,它有以下三種狀態:
- 關閉( Closed ):預設情況下Circuit Breaker是關閉的,此時允許操作執行。CircuitBreaker內部記錄著最近失敗的次數,如果對應的操作執行失敗,次數就會續一次。如果在某個時間段內,失敗次數(或者失敗比率)達到閾值,CircuitBreaker會轉換到開啟( Open )狀態。在開啟狀態中,Circuit Breaker會啟用一個超時計時器,設這個計時器的目的是給叢集相應的時間來恢復故障。當計時器時間到的時候,CircuitBreaker會轉換到半開啟( Half-Open )狀態。
- 開啟( Open ):在此狀態下,執行對應的操作將會立即失敗並且立即丟擲異常。
- 半開啟( Half-Open ):在此狀態下,Circuit Breaker會允許執行一定數量的操作。如果所有操作全部成功,CircuitBreaker就會假定故障已經恢復,它就會轉換到關閉狀態,並且重置失敗次數。如果其中 任意一次 操作失敗了,Circuit Breaker就會認為故障仍然存在,所以它會轉換到開啟狀態並再次開啟計時器(再給系統一些時間使其從失敗中恢復)
6. 限流和降級
保證核心服務的穩定性。為了保證核心服務的穩定性,隨著訪問量的不斷增加,需要為系統能夠處理的服務數量設定一個極限閥值,超過這個閥值的請求則直接拒絕。同時,為了保證核心服務的可用,可以對否些非核心服務進行降級,透過限制服務的最大訪問量進行限流,透過管理控制檯對單個微服務進行人工降級
7. SLA
SLA:Service-LevelAgreement的縮寫,意思是服務等級協議。 是關於網路服務供應商和客戶間的一份合同,其中定義了服務型別、服務質量和客戶付款等術語。 典型的SLA包括以下專案:
- 分配給客戶的最小頻寬;
- 客戶頻寬極限;
- 能同時服務的客戶數目;
- 在可能影響使用者行為的網路變化之前的通知安排;
- 撥入訪問可用性;
- 運用統計學;
- 服務供應商支援的最小網路利用效能,如99.9%有效工作時間或每天最多為1分鐘的停機時間;
- 各類客戶的流量優先權;
- 客戶技術支援和服務;
- 懲罰規定,為服務供應商不能滿足 SLA需求所指定。
8. API閘道器
這裡說的閘道器是指API閘道器,直面意思是將所有API呼叫統一接入到API閘道器層,有閘道器層統一接入和輸出。一個閘道器的基本功能有:統一接入、安全防護、協議適配、流量管控、長短連結支援、容錯能力。有了閘道器之後,各個API服務提供團隊可以專註於自己的的業務邏輯處理,而API閘道器更專註於安全、流量、路由等問題。
9. 多級快取
最簡單的快取就是查一次資料庫然後將資料寫入快取比如redis中並設定過期時間。因為有過期失效因此我們要關註下快取的穿透率,這個穿透率的計算公式,比如查詢方法queryOrder(呼叫次數1000/1s)裡面巢狀查詢DB方法queryProductFromDb(呼叫次數300/s),那麼redis的穿透率就是300/1000,在這種使用快取的方式下,是要重視穿透率的,穿透率大了說明快取的效果不好。還有一種使用快取的方式就是將快取持久化,也就是不設定過期時間,這個就會面臨一個資料更新的問題。一般有兩種辦法,一個是利用時間戳,查詢預設以redis為主,每次設定資料的時候放入一個時間戳,每次讀取資料的時候用系統當前時間和上次設定的這個時間戳做對比,比如超過5分鐘,那麼就再查一次資料庫。這樣可以保證redis裡面永遠有資料,一般是對DB的一種容錯方法。還有一個就是真正的讓redis做為DB使用。就是圖裡面畫的透過訂閱資料庫的binlog透過資料異構系統將資料推送給快取,同時將將快取設定為多級。可以透過使用jvmcache作為應用內的一級快取,一般是體積小,訪問頻率大的更適合這種jvmcache方式,將一套redis作為二級remote快取,另外最外層三級redis作為持久化快取。
10. 超時和重試
超時與重試機制也是容錯的一種方法,凡是發生RPC呼叫的地方,比如讀取redis,db,mq等,因為網路故障或者是所依賴的服務故障,長時間不能傳回結果,就會導致執行緒增加,加大cpu負載,甚至導致雪崩。所以對每一個RPC呼叫都要設定超時時間。對於強依賴RPC呼叫資源的情況,還要有重試機制,但是重試的次數建議1-2次,另外如果有重試,那麼超時時間就要相應的調小,比如重試1次,那麼一共是發生2次呼叫。如果超時時間配置的是2s,那麼客戶端就要等待4s才能傳回。因此重試+超時的方式,超時時間要調小。這裡也再談一下一次PRC呼叫的時間都消耗在哪些環節,一次正常的呼叫統計的耗時主要包括: ①呼叫端RPC框架執行時間 + ②網路傳送時間 + ③服務端RPC框架執行時間 + ④服務端業務程式碼時間。呼叫方和服務方都有各自的效能監控,比如呼叫方tp99是500ms,服務方tp99是100ms,找了網路組的同事確認網路沒有問題。那麼時間都花在什麼地方了呢,兩種原因,客戶端呼叫方,還有一個原因是網路發生TCP重傳。所以要註意這兩點。
11. 執行緒池隔離
在抗量這個環節,Servlet3非同步的時候,有提到過執行緒隔離。執行緒隔離的之間優勢就是防止級聯故障,甚至是雪崩。當閘道器呼叫N多個介面服務的時候,我們要對每個介面進行執行緒隔離。比如,我們有呼叫訂單、商品、使用者。那麼訂單的業務不能夠影響到商品和使用者的請求處理。如果不做執行緒隔離,當訪問訂單服務出現網路故障導致延時,執行緒積壓最終導致整個服務CPU負載滿。就是我們說的服務全部不可用了,有多少機器都會被此刻的請求塞滿。那麼有了執行緒隔離就會使得我們的閘道器能保證區域性問題不會影響全域性。
12. 降級和限流
關於降級限流的方法業界都已經有很成熟的方法了,比如FAILBACK機制,限流的方法令牌桶,漏桶,訊號量等。這裡談一下我們的一些經驗,降級一般都是由統一配置中心的降級開關來實現的,那麼當有很多個介面來自同一個提供方,這個提供方的系統或這機器所在機房網路出現了問題,我們就要有一個統一的降級開關,不然就要一個介面一個介面的來降級。也就是要對業務型別有一個大閘刀。還有就是 降級切記暴力降級,什麼是暴力降級的,比如把論壇功能降調,結果使用者顯示一個大白板,我們要實現快取住一些資料,也就是有託底資料。限流一般分為分散式限流和單機限流,如果實現分散式限流的話就要一個公共的後端儲存服務比如redis,在大nginx節點上利用lua讀取redis配置資訊。我們現在的限流都是單機限流,並沒有實施分散式限流。
13. 閘道器監控和統計

API閘道器是一個序列的呼叫,那麼每一步發生的異常要記錄下來,統一儲存到一個地方比如elasticserach中,便於後續對呼叫異常的分析。鑒於公司docker申請都是統一分配,而且分配之前docker上已經存在3個agent了,不再允許增加。我們自己實現了一個agent程式,來負責採集伺服器上面的日誌輸出,然後傳送到kafka叢集,再消費到elasticserach中,透過web查詢。現在做的追蹤功能還比較簡單,這塊還需要繼續豐富。
