來源:機器之心;作者:Jonathan Hui;
本文共1萬+字,建議閱讀10+分鐘。
本文將會從第一步開始,教你解決專案開發中會遇到的各類問題。
[ 導讀 ]在學習了有關深度學習的理論之後,很多人都會有興趣嘗試構建一個屬於自己的專案。本文將會從第一步開始,告訴你如何解決專案開發中會遇到的各類問題。
本文由六大部分組成,涵蓋深度學習 ( DL ) 專案的整個過程。我們將使用一個自動漫畫著色專案來說明深度學習的設計、程式除錯和引數調整過程。
本文主題為“如何啟動一個深度學習專案?”,分為以下六個部分:
-
第一部分:啟動一個深度學習專案
-
第二部分:建立一個深度學習資料集
-
第三部分:設計深度模型
-
第四部分:視覺化深度網路模型及度量指標
-
第五部分:深度學習網路中的除錯
-
第六部分:改善深度學習模型效能及網路調參
第一部分:啟動一個深度學習專案
1. 應該選擇什麼樣的專案?
很多人工智慧專案其實並沒有那麼嚴肅,做起來還很有趣。2017 年初,我著手啟動了一個為日本漫畫上色的專案,並作為我對生成對抗網路 ( GAN ) 研究的一部分。這個問題很難解決,但卻很吸引人,尤其是對於我這種不會畫畫的人來說!在尋找專案時,不要侷限於增量性改進,去做一款適銷對路的產品,或者建立一種學習速度更快、質量更高的新模型。
2. 除錯深度網路(DN)非常棘手
訓練深度學習模型需要數百萬次的迭代,因此查詢 bug 的過程非常艱難,而且容易崩壞。因此我們要從簡單的地方著手,循序漸進,例如模型的最佳化(如正則化)始終可以在程式碼除錯完成後進行。此外,我們還需要經常視覺化預測結果和模型度量標準,並且我們首先需要令模型跑起來,這樣就有一個可以後退的基線。我們最好不要陷在一個很大的模型,並嘗試將所有的模組都弄好。
3. 度量和學習
宏偉的專案計劃可能帶慘烈的失敗。多數個人專案的第一個版本會持續兩到四個月,這個時間非常短暫,因為研究、除錯和實驗都需要花費大量的時間。一般我們安排這些複雜的實驗,使其通宵執行,到第二天清晨時,我們希望得到足夠的資訊來採取下一步行動。在早期階段,這些實驗不應超過 12 小時,這是一條良好的經驗法則。為了做到這一點,我們將漫畫上色專案範圍縮小到單個動畫人物的上色。此外,我們需要設計很多測試,因此藉助它們分析模型在實驗中的不足之處。一般這些測試不要計劃得太遠,我們需要快速度量、學習,併為下一步設計提供足夠的反饋。
4. 研究與產品
當我們在 2017 年春季開始討論漫畫上色專案時,Kevin Frans 有一個 Deepcolor 專案,用 GAN 為漫畫新增色彩提示。

在確定標的時,你會花很大力氣來確保專案完成後仍然具有意義。GAN 模型相當複雜,2017 年初還沒達到嵌入產品所需的質量水準。然而,如果你把應用範圍縮小到產品可以巧妙處理的程度,你就可以把質量提高到商用水準。為此,無論著手啟動何種 DL 專案,都要把握好模型泛化、容量和準確性之間的平衡。
5. 成本
必須使用 GPU 來訓練實際模型。它比 CPU 快 20 到 100 倍。價格最低的亞馬遜 GPU p2.xlarge 站點實體要價 7.5 美元/天,而 8 核 GPU 的價格則高達 75 美元/天。在我們的漫畫上色專案中,一些實驗花費的時間就超過兩天,因此平均每週花費至少需要 150 美元。至於更快的 AWS 實體,花費可能高達 1500 美元/周。我們可以購買獨立計算機,而不是使用雲端計算。2018 年 2 月,搭載 Nvidia GeForce GTX 1080 Ti 的臺式機售價約為 2200 美元。在訓練精調的 VGG 模型時,它比 P2 實體大約要快 5 倍。
6. 時間線
我們將開發分為四個階段,最後三個階段在多次迭代中進行。
-
專案研究
-
模型設計
-
實現及除錯
-
實驗及調參
-
專案研究
我們會先對現有產品進行研究,以探索它們的弱點。許多 GAN 型別的解決方案使用空間顏色提示,圖案有點不清晰,有時還會出現顏色混雜。我們為自己的專案設定了兩個月的時間框架,其中有兩個優先事項:生成不帶提示的顏色及提高顏色保真度。我們的標的是:
在單個動畫角色上為灰度漫畫著色,且不使用空間顏色提示。
-
站在巨人的肩膀上
接下來,我們需要瞭解相關的研究和開源專案,許多人在開始實踐之前至少要看幾十篇論文和專案。例如,當我們深入研究 GAN 時,發現有十幾個新的 GAN 模型: DRAGAN、cGAN、LSGAN 等,閱讀研究論文可能會很痛苦,但非常有意義。
深度學習 ( DL ) 程式碼簡練,但很難排查缺陷,且很多研究論文常常遺漏了實現細節。許多專案始於開源實現,解決的問題也很相似,因此我們可以多多搜尋開源專案。因此我們在 GitHub 上查看了不同 GAN 變體的程式碼實現,並對它們進行若干次測試。
第二部分:建立一個深度學習資料集
深度學習專案的成功取決於資料集的質量。在本文的第 2 部分中,我們將探討建立優質訓練資料集的核心問題。

1. 公開及學術資料集
對於研究專案,可以搜尋已建立的公開資料集。這些資料集可以提供更整齊的樣本和基線模型效能。如果你有多個可用的公開資料集,請選擇與你的問題最相關且質量最好的樣本。
2. 自定義資料集
對於實際問題,我們需要來自問題領域的樣本。首先嘗試查詢公共資料集。關於建立高質量自定義資料集的研究還有所欠缺。如果沒有可用的資料,請搜尋你可以抓取資料的位置。該位置通常有很多參考,但資料質量通常較低,還需要投入大量精力進行整理。在抓取樣本之前,要專門抽出時間評估所有選項並選擇最相關的選項。
高質量資料集應該包括以下特徵:
-
類別均衡
-
資料充足
-
資料和標記中有高質量資訊
-
資料和標記錯誤非常小
-
與你的問題相關
不要一次爬取所有資料。我們經常藉助標簽和分類來抓取網站樣本,從而獲取與我們的問題相關的資料。最好的爬取方法是在你的模型中訓練、測試少量樣本,並根據得到的經驗教訓改善抓取方法。
清理你抓取的資料非常重要,否則,即使最好的模型設計也達不到與人類水平相當的表現。Danbooru 和 Safebooru 是兩個非常受歡迎的動漫人物來源,但是一些深入學習的應用程式偏愛 Getchu,以獲得更高質量的繪圖。我們可以使用一組標簽從 Safebooru 下載影象,並直觀地檢查樣本並執行測試來分析錯誤(表現不佳的樣本)。
模型訓練和視覺評估都提供了進一步的資訊來細化我們的標簽選擇。隨著迭代的繼續,我們將學到更多,並逐漸進行樣本積累。我們還需要使用分類器進一步過濾與問題無關的樣本,如清除所有人物過小的影象等。與學術資料集相比,小型專案收集的樣本很少,在適當情況下可以應用遷移學習。
下麵的左圖由 PaintsChainer 提供,右圖由最終的模型上色:

我們決定用一些訓練樣本來對演演算法進行測試。結果並沒有給人驚喜,應用的顏色較少,樣式也不正確。


由於對模型進行了一段時間的訓練,我們知道什麼樣的繪圖表現欠佳。正如預期的那樣,結構錯綜複雜的繪圖更難上色。

這說明好好選擇樣本非常重要。作為一款產品,PaintsChainer 專註於它們擅長的線條型別,這點非常明智。這次我使用了從網際網路上挑選的乾凈線條藝術,結果再次給人驚喜。
這裡有一些經驗教訓:資料沒有好壞之分,只是有些資料不能滿足你的需求。此外,隨著樣本類別的增加,訓練和保持輸出質量會變得更加困難,刪除不相關的資料可以得到一個更好的模型。
在開發早期,我們認識到一些繪圖有太多錯綜複雜的結構。在不顯著增加模型容量的情況下,這些繪圖在訓練中產生的價值很小,因此最好不要使用,否則只會影響訓練效率。
3. 重點回顧
-
盡可能使用公共資料集;
-
尋找可以獲取高質量、多樣化樣本的最佳網站;
-
分析錯誤並過濾掉與實際問題無關的樣本;
-
迭代地建立你的樣本;
-
平衡每個類別的樣本數;
-
訓練之前先整理樣本;
-
收集足夠的樣本。如果樣本不夠,應用遷移學習。
第三部分:設計深度模型
第三部分介紹了一些高層次的深度學習策略,接下來我們將詳細介紹最常見的設計選擇,這可能需要一些基本的 DL 背景。
1. 簡單靈活
設計初始要簡單、小巧。在學習階段,人們腦海中會充斥大量很酷的觀念。我們傾向於一次性把所有細節都編碼進來。但這是不現實的,最開始就想要超越頂尖的結果並不實際。從較少網路層和自定義開始設計,後面再做一些必要的超引數精調方案。這些都需要查證損失函式一直在降低,不要一開始就在較大的模型上浪費時間。
在簡短的 Debug 之後,我們的模型經過 5000 次迭代產生了簡單的結果。但至少該模型所上的顏色開始限制在固定區域內,且膚色也有些顯露出來。

在模型是否開始上色上,以上結果給了我們有價值的反饋。所以不要從大模型開始,不然你會花費大量時間 Debug 和訓練模型。
2. 優先性以及增量設計
首先為了創造簡單的設計,我們需要選出優先項。把複雜問題分解成小問題,一步一步解決。做深度學習的正確策略是快速的執行學到的東西。在跳到使用無暗示(no hints)模型之前,我們先使用帶有空間顏色暗示的模型。不要一步跳到”無暗示”模型設計,例如我們首先去掉暗示中的空間資訊,顏色質量會急劇下降,所以我們轉變優先性,在做下一步前先精煉我們的模型。在設計模型的過程中,我們會遇到許多驚喜。相比於做個要不斷改變的長期計劃,還不如以優先性驅動的計劃。使用更短、更小的設計迭代,從而保證專案可管理性。
3. 避免隨機改進
首先分析自己模型的弱點,而不是隨意地改進,例如用雙向 LSTM 或者 PReLU。我們需要根據視覺化模型誤差(表現極差的場景)以及效能引數來確定模型問題。隨意做改進反而適得其反,會成比例的增加訓練成本,而回報極小。
4. 限制
我們把限制應用到網路設計,從而保證訓練更高效。建立深度學習並不是簡單的把網路層堆在一起。增加好的限制(constraints)能使得學習更為有效,或者更智慧。例如,應用註意機制,能讓網路知道註意哪裡,在變分自編碼器中,我們訓練隱藏因子使其服從正態分佈。在設計中,我們應用去噪方法透過歸零除去空間顏色暗示的大量分數。啼笑皆非的是,這使得模型能更好地學習、泛化。
5. 設計細節
文章接下來的部分,將討論深度學習專案中會遇到的一些常見的設計選擇。
-
深度學習軟體框架
自谷歌 2015 年 11 月釋出 TensorFlow 以來,短短 6 個月就成為了最流行的深度學習框架。雖然短期看起來難有競爭對手,但一年後 Facebook 就釋出了 PyTorch,且極大的受研究社群的關註。到 2018 年,已經有大量的深度學習平臺可供選擇,包括 TensorFlow、PyTorch、Caffe、Caffe2、MXNet、CNTK 等。
一些研究員之所以轉向 PyTorch 有一主要因素:PyTorch 設計上註重端使用者(end-user),API 簡單且直觀。錯誤資訊可以直觀地理解,API 檔案也非常完整。PyTorch 中的特徵,例如預訓練模型、資料預處理、載入常用資料集都非常受歡迎。
TensorFlow 也非常棒,但目前為止它還是採用自下而上的方式,使其變得極為複雜。TensorFlow 的 API 很冗長,Debug 也不一樣,它大概有十幾種建立深度網路的 API 模型。
截止到 2018 年 2 月,TensorFlow 依然獨佔鰲頭。開發者社群依然是是最大的。這是非常重要的因素。如果你想要用多個機器訓練模型,或者把推理引擎部署到移動手機上,TensorFlow 是唯一的選擇。然而,如果其他平臺變得更加專註端使用者,我們可以預見將會有更多從小專案轉向中級專案。
隨著 TensorFlow 的發展,有很多 API 可供選擇來建立深度網路。最高層的 API 是提供隱式積分的評估器,而 TensorBoard 提供了效能評估。最低層的 API 非常冗長,在許多模組中都有。現在,它用封裝器 API 合併到了 tf.layers、tf.metrics 和 tf.losses 模組,從而更容易地建立深度網路層。
對想要更直觀 API 的研究者來說,還有 Keras、TFLearn、TF-Slim 等可以選擇,這些都可直接在 TensorFlow 上使用。我建議是選擇帶有所需要的預訓練模型與工具(來下載資料集)的框架,此外在學術界,用 Keras API 做原型設計相當流行。
-
遷移學習
不要做重覆的工作。許多深度學習軟體平臺都有 VGG19、ResNet、Inception v3 這樣的預訓練模型。從頭開始訓練非常耗費時間。就像 2014 年 VGG 論文中所說的,”VGG 模型是用 4 塊英偉達 Titan Black GPU 訓練的,根據架構訓練單個網路需要 2-3 周的時間。”
許多預訓練模型可用於解決深度學習難題。例如,我們使用預訓練 VGG 模型提取影象特徵,並將這些特徵反饋到 LSTM 模型來生成描述。許多預訓練模型都用 ImageNet 資料集訓練,如果你的標的資料和 ImageNet 差別不大,我們將固定大部分模型引數,只重新訓練最後幾個完全連線的層。否則,我們就要使用訓練資料集對整個網路進行端到端的重訓練。但是在這兩種情況下,由於模型已經過預訓練,再訓練所需的迭代將大大減少。由於訓練時間較短,即使訓練資料集不夠大,也可以避免過擬合。這種遷移學習在各個學科都很有效,例如用預先訓練好的英語模型訓練漢語模型。
然而,這種遷移學習僅適用於需要複雜模型來提取特徵的問題。在我們的專案中,我們的示例與 ImageNet 不同,我們需要對模型進行端到端的重新訓練。然而,當我們只需要相對簡單的潛在因素(顏色)時,來自 VGG19 的訓練複雜度太高。因此,我們決定建立一個新的更簡單的 CNN 特徵提取模型。
-
成本函式
並非所有的成本函式都是等價的,它會影響模型的訓練難度。有些成本函式是相當標準的,但有些問題域需要仔細考慮。
-
分類問題:交叉熵,折頁損失函式(SVM)
-
回歸: 均方誤差(MSE)
-
物件檢測或分割:交並比(IoU)
-
策略最佳化:KL 散度
-
詞嵌入:噪音對比估計(NCE)
-
詞向量:餘弦相似度
在理論分析中看起來不錯的成本函式在實踐中可能不太好用。例如,GAN 中鑒別器網路的成本函式採用了更為實用也更經得起實驗考驗的方法,而不是理論分析中看起來不錯的方法。在一些問題域中,成本函式可以是部分猜測加部分實驗,也可以是幾個成本函式的組合。我們的專案始於標準 GAN 成本函式。此外,我們還添加了使用 MSE 和其他正則化成本的重建成本。然而,如何找到更好的成本函式是我們專案中尚未解決的問題之一,我們相信它將對色彩保真度產生重大影響。
-
度量標準
良好的度量標準有助於更好地比較和調整模型。對於特殊問題,請檢視 Kaggle 平臺,該平臺組織了許多 DL 競賽,並提供了詳細的度量標準。不幸的是,在我們的專案中,你很難定義一個精確的公式來衡量藝術渲染的準確性。
-
正則化
L1 正則化和 L2 正則化都很常見,但 L2 正則化在深度學習中更受歡迎。
L1 正則化有何優點?L1 正則化可以產生更加稀疏的引數,這有助於解開底層表示。由於每個非零引數會往成本上新增懲罰,與 L2 正則化相比,L1 更加青睞零引數,即與 L2 正則化中的許多微小引數相比,它更喜歡零引數。L1 正則化使過濾器更乾凈、更易於解釋,因此是特徵選擇的良好選擇。L1 對異常值的脆弱性也較低,如果資料不太乾凈,執行效果會更好。然而,L2 正則化仍然更受歡迎,因為解可能更穩定。
-
梯度下降
始終密切監視梯度是否消失或爆炸,梯度下降問題有許多可能的原因,這些原因難以證實。不要跳至學習速率調整或使模型設計改變太快,小梯度可能僅僅由程式設計 Bug 引起,如輸入資料未正確縮放或權重全部初始化為零。
如果消除了其他可能的原因,則在梯度爆炸時應用梯度截斷(特別是對於 NLP)。跳過連線是緩解梯度下降問題的常用技術。在 ResNet 中,殘差模組允許輸入繞過當前層到達下一層,這有效地增加了網路的深度。
-
縮放
縮放輸入特徵。我們通常將特徵縮放為以零為均值在特定範圍內,如 [-1, 1]。特徵的不適當縮放是梯度爆炸或降低的一個最常見的原因。有時我們從訓練資料中計算均值和方差,以使資料更接近正態分佈。如果縮放驗證或測試資料,要再次利用訓練資料的均值和方差。
-
批歸一化和層歸一化
每層啟用函式之前節點輸出的不平衡性是梯度問題的另一個主要來源,必要時需要對 CNN 應用批次歸一化(BN)。如果適當地標準化(縮放)輸入資料,DN 將學習得更快更好。在 BN 中,我們從每批訓練資料中計算每個空間位置的均值和方差。例如,批大小為 16,特徵圖具有 10 X10 的空間維度,我們計算 100 個平均值和 100 個方差(每個位置一個)。每個位置處的均值是來自 16 個樣本的對應位置平均值,我們使用均值和方差來重新歸一化每個位置的節點輸出。BN 提高了準確度,同時縮短了訓練時間。
然而,BN 對 RNN 無效,我們需要使用層歸一化。在 RNN 中,來自 BN 的均值和方差不適合用來重新歸一化 RNN 單元的輸出,這可能是因為 RNN 和共享引數的迴圈屬性。在層歸一化中,輸出由當前樣本的層輸出計算的平均值和方差重新歸一化。一個含有 100 個元素的層僅使用來自當前輸入的一個平均值方差來重新歸一化該層。
-
Dropout
可以將 Dropout 應用於層以歸一化模型。2015 年批次歸一化興起之後,dropout 熱度降低。批次歸一化使用均值和標準差重新縮放節點輸出。這就像噪聲一樣,迫使層對輸入中的變數進行更魯棒的學習。由於批次歸一化也有助於解決梯度下降問題,因此它逐漸取代了 Dropout。
結合 Dropout 和 L2 正則化的好處是領域特定的。通常,我們可以在調優過程中測試 dropout,並收集經驗資料來證明其益處。
-
啟用函式
在 DL 中,ReLU 是最常用的非線性啟用函式。如果學習速率太高,則許多節點的啟用值可能會處於零值。如果改變學習速率沒有幫助,我們可以嘗試 leaky ReLU 或 PReLU。在 leaky ReLU 中,當 x < 0 時,它不輸出 0,而是具有小的預定義向下斜率(如 0.01 或由超引數設定)。引數 ReLU(PReLU)往前推動一步。每個節點將具有可訓練斜率。
-
拆分資料集
為了測試實際效能,我們將資料分為三部分: 70 % 用於訓練,20 % 用於驗證,10 % 用於測試。確保樣本在每個資料集和每批訓練樣本中被充分打亂。在訓練過程中,我們使用訓練資料集來構建具有不同超引數的模型。我們使用驗證資料集來執行這些模型,並選擇精確度最高的模型。但是保險起見,我們使用 10 % 的測試資料進行最後的錯亂檢查。如果你的測試結果與驗證結果有很大差異,則應將資料打亂地更加充分或收集更多的資料。
-
基線
設定基線有助於我們比較模型和 Debug,例如我們可使用 VGG19 模型作為分類問題的基線。或者,我們可以先擴充套件一些已建立的簡單模型來解決我們的問題。這有助於我們更好地瞭解問題,並建立效能基線進行比較。在我們的專案中,我們修改了已建立的 GAN 實現並重新設計了作為基線的生成網路。
-
檢查點
我們定期儲存模型的輸出和度量以供比較。有時,我們希望重現模型的結果或重新載入模型以進一步訓練它。檢查點允許我們儲存模型以便以後重新載入。但是,如果模型設計已更改,則無法載入所有舊檢查點。我們也使用 Git 標記來跟蹤多個模型,併為特定檢查點重新載入正確的模型。我們的設計每個檢查點佔用 4gb 空間。在雲環境中工作時,應相應配置足夠的儲存。我們經常啟動和終止 Amazon 雲實體,因此我們將所有檔案儲存在 Amazon EBS 中,以便於重新連線。
-
自定義層
深度學習軟體包中的內建層已經得到了更好的測試和最佳化。儘管如此,如果想自定義層,你需要:
-
用非隨機資料對前向傳播和反向傳播程式碼進行模組測試;
-
將反向傳播結果和樸素梯度檢查進行對比;
-
在分母中新增小量的ϵ或用對數計算來避免 NaN 值。
-
歸一化
深度學習的一大挑戰是可復現性。在除錯過程中,如果初始模型引數在 session 間保持變化,就很難進行除錯。因此,我們明確地對所有隨機發生器初始化了種子。我們在專案中對 python、NumPy 和 TensorFlow 都初始化了種子。在精調過程中,我們我們關閉了種子初始化,從而為每次執行生成不同的模型。為了復現模型的結果,我們將對其進行 checkpoint,併在稍後重新載入它。
6. 最佳化器
Adam 最佳化器是深度學習中最流行的最佳化器之一。它適用於很多種問題,包括帶稀疏或帶噪聲梯度的模型。其易於精調的特性使得它能快速獲得很好的結果。實際上,預設的引數配置通常就能工作得很好。Adam 最佳化器結合了 AdaGrad 和 RMSProp 的優點。Adam 對每個引數使用相同的學習率,並隨著學習的進行而獨立地適應。Adam 是基於動量的演演算法,利用了梯度的歷史資訊。因此,梯度下降可以執行得更加平滑,並抑制了由於大梯度和大學習率導致的引數振蕩問題。
-
Adam 最佳化器調整
Adam 有 4 個可配置引數:
-
學習率(預設 0.001);
-
β1:第一個矩估計的指數衰減率(預設 0.9);
-
β2:第二個矩估計的指數衰減率(預設 0.999),這個值在稀疏梯度問題中應該被設定成接近 1;
-
ϵ(預設值 1e^-8)是一個用於避免除以零運算的小值。
β(動量)透過累積梯度的歷史資訊來平滑化梯度下降。通常對於早期階段,預設設定已經能工作得很好。否則,最可能需要改變的引數應該是學習率。
7. 總結
以下是對深度學習專案的主要步驟的簡單總結:
• Define task (Object detection, Colorization of line arts)
• Collect dataset (MS Coco, Public web sites)
◦ Search for academic datasets and baselines
◦ Build your own (From Twitter, News, Website,…)
• Define the metrics
◦ Search for established metrics
• Clean and preprocess the data
◦ Select features and transform data
◦ One-hot vector, bag of words, spectrogram etc...
◦ Bucketize, logarithm scale, spectrogram
◦ Remove noise or outliers
◦ Remove invalid and duplicate data
◦ Scale or whiten data
• Split datasets for training, validation and testing
◦ Visualize data
◦ Validate dataset
• Establish a baseline
◦ Compute metrics for the baseline
◦ Analyze errors for area of improvements
• Select network structure
◦ CNN, LSTM…
• Implement a deep network
◦ Code debugging and validation
◦ Parameter initialization
◦ Compute loss and metrics
◦ Choose hyper-parameters
◦ Visualize, validate and summarize result
◦ Analyze errors
◦ Add layers and nodes
◦ Optimization
• Hyper-parameters fine tunings
• Try our model variants
第四部分:視覺化深度網路模型及度量指標
在為深度神經網路排除故障方面,人們總是太快、太早地下結論了。在瞭解如何排除故障前,我們要先考慮要尋找什麼,再花費數小時時間追蹤故障。這部分我們將討論如何視覺化深度學習模型和效能指標。
1. TensorBoard
在每一步追蹤每個動作、檢查結果非常重要。在預置包如 TensorBoard 的幫助下,視覺化模型和效能指標變得簡單,且獎勵幾乎是同時的。
2. 資料視覺化(輸入、輸出)
驗證模型的輸入和輸出。在向模型饋送資料之前,先儲存一些訓練和驗證樣本用於視覺驗證。取消資料預處理。將畫素值重新調整回 [0, 255]。檢查多個批次,以確定我們沒有重覆相同批次的資料。左下影象是一些訓練樣本,右下方驗證樣本。

有時,驗證輸入資料的直方圖很棒。完美情況下,它應該是以 0 為中心的,區間在 -1 和 1 之間。如果特徵在不同的尺度中,那麼梯度要麼下降要麼爆炸(根據學習率而定)。
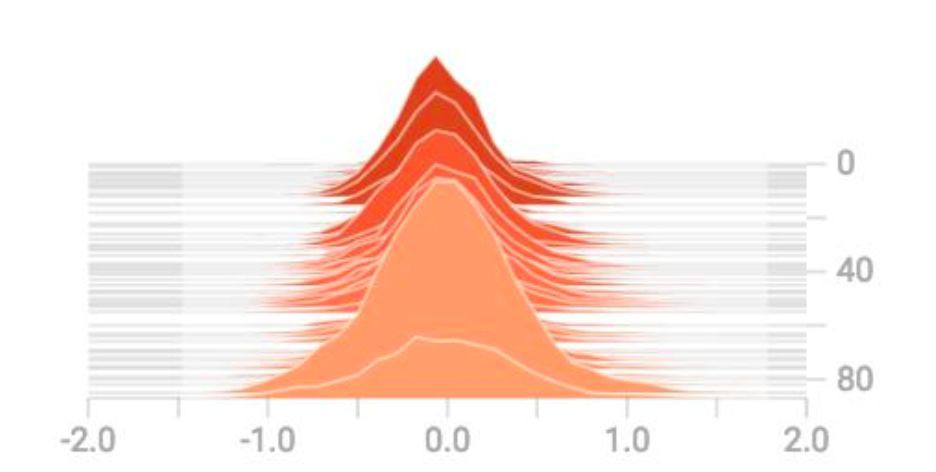
定期儲存對應模型的輸出,用於驗證和誤差分析。例如,驗證輸出中的顏色稍淺。

3. 指標(損失 & 準確率)
除了定期記錄損失和準確率之外,我們還可以記錄和繪製它們,以分析其長期趨勢。下圖是 TensorBoard 上展示的準確率和交叉熵損失。
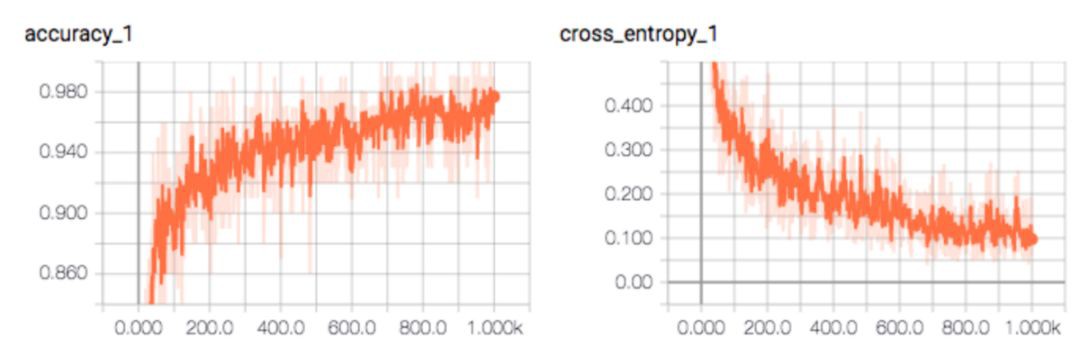
繪製損失圖能夠幫助我們調整學習率。損失的任意長期上升表明學習率太高了。如果學習率較低,則學習的速度變慢。

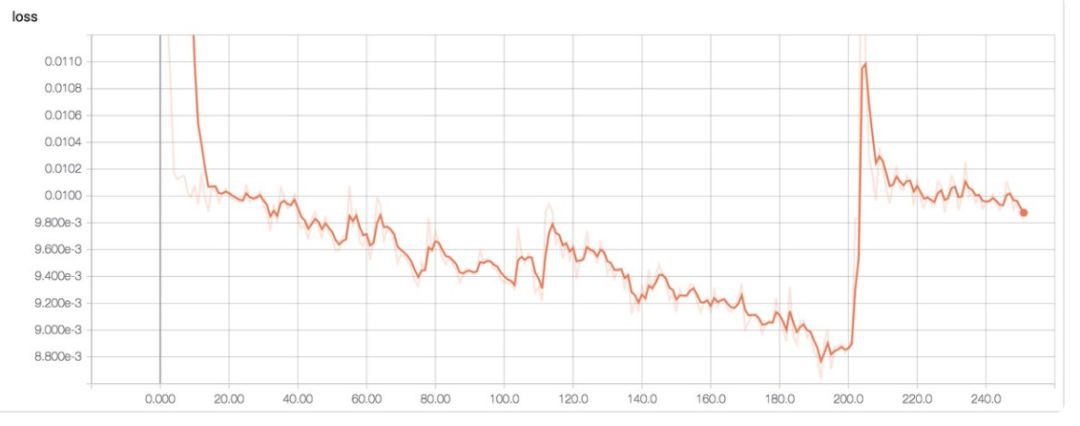
這裡是另一個學習率太高的真實樣本。我們能看到損失函式突然上升(可能由梯度突然上升引起)。
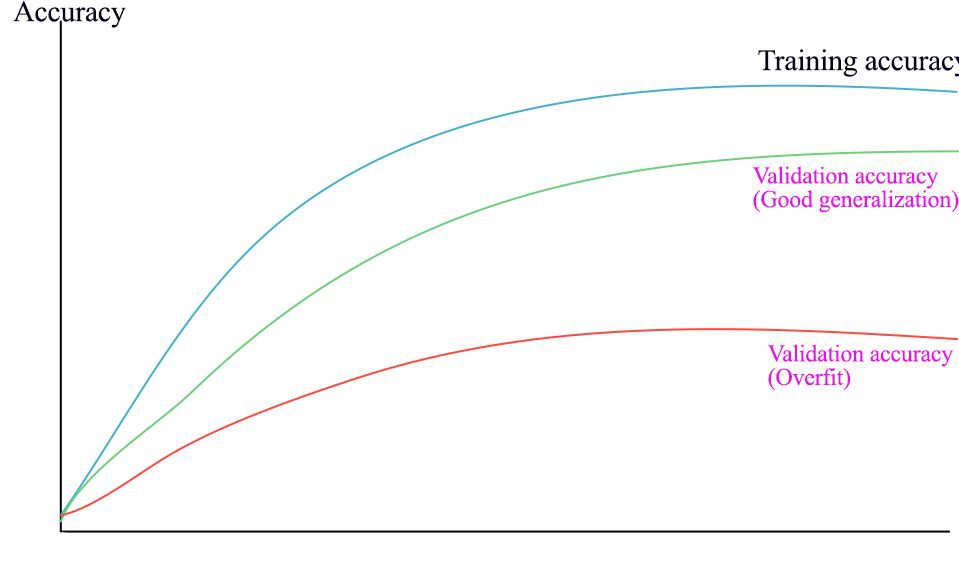
我們使用準確率圖調整正則化因子。如果驗證和訓練準確率之間存在很大差距,則該模型出現過擬合。為了緩解過擬合,我們需要提高正則化因子。
4. 小結
權重 & 偏置:我們緊密監控權重和偏置。下圖是層 1 在不同訓練迭代中的權重和偏置。出現大型(正/負)權重是不正常的。正態分佈的權重表明訓練過程很順利(但是也不一定)。
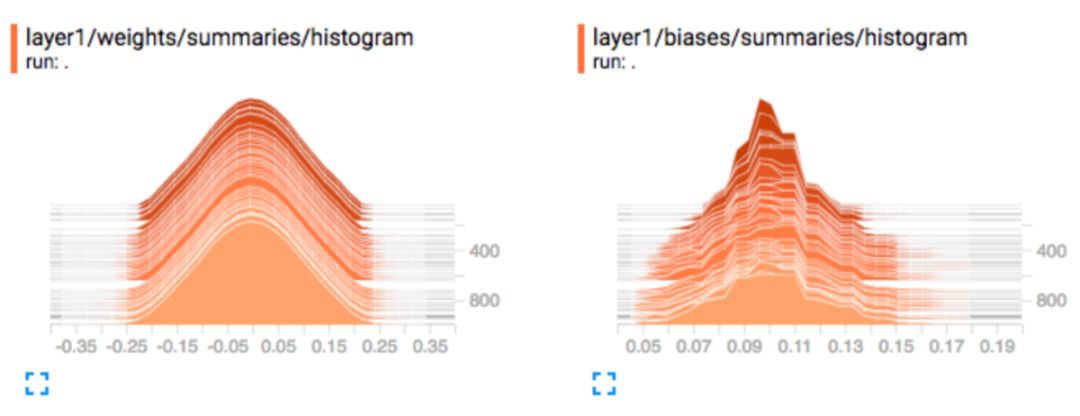
啟用:為了梯度下降以實現最佳效能,啟用函式之前的節點輸出應該呈正態分佈。如果不是,那麼我們可能向摺積層應用批歸一化,或者向 RNN 層應用層歸一化。我們還監控啟用函式之後無效節點(0 啟用)的數量。
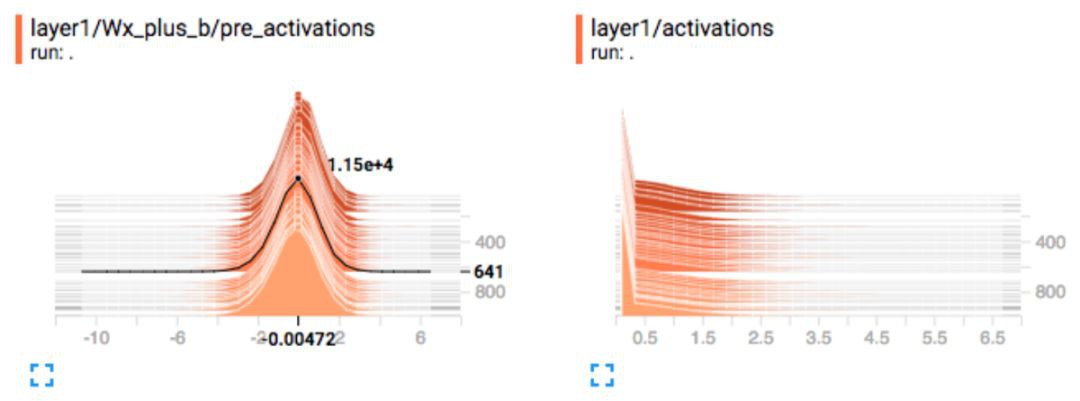
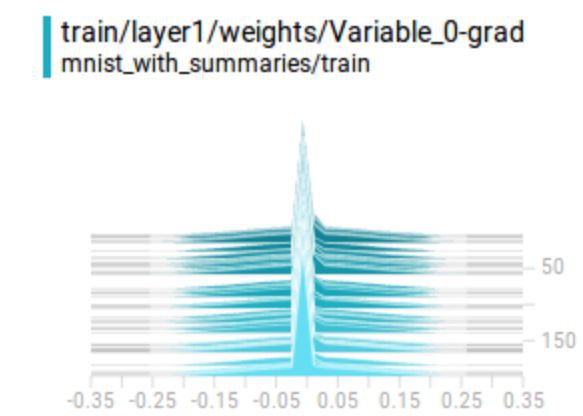
梯度:我們監控每一層的梯度,以確定一個最嚴肅的深度學習問題:梯度消失或爆炸。如果梯度從最右層向最左層快速下降,那麼就出現了梯度消失問題。
這或許不是很常見:我們可視化了 CNN 濾波器。它識別出模型提取的特徵的型別。如下圖所示,前兩個摺積層在檢測邊界和顏色。

對於 CNN,我們可以看到特徵圖在學習什麼。下圖捕捉了特定圖中具備最高啟用函式的 9 張圖(右側)。它還使用解摺積網路從特徵圖中重建空間影象(左圖)。

Visualizing and Understanding Convolutional Networks, Matthew D Zeiler et al.
這種影象重建很少進行。但是在生成模型中,我們經常改變一個潛在因子、保持其他不變。它驗證該模型是否在智慧地學習。

Dynamic Routing Between Capsules, Sara Sabour, Nicholas Frosst, Geoffrey E Hinton
第五部分:深度學習網路中的除錯
1. 深度學習的問題解決步驟
在前期開發中,我們會同時遇到多個問題。就像前面提到的,深度學習訓練由數百萬次迭代組成。找到 bug 非常難,且容易崩潰。從簡單開始,漸漸做一些改變。正則化這樣的模型最佳化可以在程式碼 degug 後做。以功能優先的方式檢查模型:
-
把正則化因子設定為 0;
-
不要其他正則化(包括 dropouts);
-
使用預設設定的 Adam 最佳化器;
-
使用 ReLU;
-
不要資料增強;
-
更少的深度網路層;
-
擴大輸入資料,但不要非必要預處理;
-
不要在長時間訓練迭代或者大 batch size 上浪費時間。
用小量的訓練資料使模型過擬合是 debug 深度學習的最好方式。如果在數千次迭代內,損失值不下降,進一步 debgug 程式碼。準確率超越瞎猜的概念,你就獲得了第一個裡程碑。然後對模型做後續的修改:增加網路層和自定義;開始用完整訓練資料做訓練;透過監控訓練和驗證資料集之間的準確率差別,來增加正則化控制過擬合。
如果卡住了,去掉所有東西,從更小的問題開始上手。
2. 初始化超引數
許多超引數與模型最佳化更為相關。關掉超引數或者使用預設值。使用 Adam 最佳化器,它速度快、高效且預設學習率也很好。前期的問題主要來自於 bug,而不是模型設計和精調問題。在做微調之前,先過一遍下麵的檢查串列。這些問題更常見,也容易檢查。如果損失值還沒下降,就調整學習率。如果損失值降的太慢,學習率增加 10。如果損失值上升或者梯度爆炸,學習率降低 10。重覆這個過程,直到損失值逐漸下降。典型的學習率在 1 到 1e-7 之間。
3. 檢查串列
資料:
-
視覺化並檢查輸入資料(在資料預處理之後,饋送到模型之前);
-
檢查輸入標簽的準確率(在資料擾動之後);
-
不要一遍又一遍的饋送同一 batch 的資料;
-
適當的縮放輸入資料(一般可縮放到區間 (-1, 1) 之間,且具有零均值);
-
檢查輸出的範圍(如,在區間 (-1, 1) 之間);
-
總是使用訓練集的平均值/方差來重新調節驗證/測試集;
-
模型所有的輸入資料有同樣的維度;
-
獲取資料集的整體質量(是否有太多異常值或者壞樣本)。
模型:
-
模型引數準確的初始化,權重不要全部設定為 0;
-
對啟用或者梯度消失/爆炸的網路層做 debug(從最右邊到最左邊);
-
對權重大部分是 0 或者權重太大的網路層做 debug;
-
檢查並測試損失函式;
-
對預訓練模型,輸入資料範圍要匹配模型中使用的範圍;
-
推理和測試中的 Dropout 應該總是關掉。
4. 權重初始化
把權重全部初始化到 0 是最常見的錯誤,深度網路也學不到任何東西。權重要按照高斯分佈做初始化:

5. 縮放與歸一化
人們對縮放與歸一化都有很好地理解,但這仍舊是最被輕視的問題之一。如果輸入特徵和節點輸出都被歸一化,就能更容易地訓練模型。如果做的不準確,損失值就不會隨著學習率降低。我們應該監控輸入特徵和每層節點輸出的的直方圖。要適當的縮放輸入。而對節點的輸出,完美的形狀是零均值,且值不太大(正或負)。如果不是且遇到該層有梯度問題,則在摺積層做批歸一化,在 RNN 單元上做層歸一化。
6. 損失函式
檢查和測試損失函式的準確性。模型的損失值一定要比隨機猜測的值低。例如,在 10 類別分類問題中,隨機猜測的的交叉熵損失是-ln(1/10)。
7. 分析誤差
檢查表現不好(誤差)的地方並加以改進,且對誤差進行視覺化。在我們的專案中,模型表現對結構高度糾纏的影象表現不好。例如,增加更多帶有更小濾波器的摺積層來解開小特徵。如果有必要就增強資料或者收集更多類似的樣本來更好的訓練模型。在一些情景下,你可能想要移除這些樣本,限制在更聚焦的模型。

8. 正則化精調
關掉正則化(使得模型過擬合)直到做出合理的預測。
一旦模型程式碼可以工作了,接下來調整的引數是正則化因子。我們需要增加訓練資料的體量,然後增加正則化來縮小訓練和驗證準確率之間的差別。不要做的太過分,因為我們想要稍微讓模型過擬合。密切監測資料和正則化成本。長時間尺度下,正則化損失不應該控制資料損失。如果用大型正則化還不能縮小兩個準確率間的差距,那先 degug 正則化程式碼或者方法。
類似於學習率,我們以對數比例改變測試值,例如開始時改變 1/10。註意,每個正則化因子都可能是完全不同的數量級,我們可以反覆調整這些引數。
9. 多個損失函式
在第一次實現中,避免使用多個資料損失函式。每個損失函式的權重可能有不同的數量級,也需要一些精力去調整。如果我們只有一個損失函式,就可以只在意學習率了。
10. 固定變數
當我們使用預訓練模型,我們可以固定特定層的模型引數,從而加速計算。一定要再次檢查是否有變數固定的錯誤。
11. 單元測試
正如極少會被談到的,我們應該對核心模組進行單元測試,以便於程式碼改變時實現依舊穩健。如果其引數用隨機發生器(randomizer)做初始化,檢查一個網路層的輸出不太簡單。另外,我們可以模仿輸入資料、檢查輸出。對每個模組(層),我們可以檢查:
-
訓練和推理輸出的形狀;
-
可訓練變數的數量(不是引數的數量)。
12. 維度誤匹配
要一直跟蹤 Tensor(矩陣)的形狀,並將其歸檔到程式碼中。對形狀是 [N, channel, W, H ] 的 Tensor,如果 W(寬)和 H(高)有同樣的維度,二者交換程式碼不會出錯。因此,我們應該用非對稱形狀做程式碼單元測試。例如,我們用 [4, 3]Tensor,而非 [4, 4] 做測試。
第六部分:改善深度學習模型效能及網路調參
1. 提升模型容量
要想提升模型容量,我們可以向深度網路(DN)逐漸新增層和節點。更深的層會輸出更複雜的模型。我們還可以降低濾波器大小。較小的濾波器(3×3 或 5×5)效能通常優於較大的濾波器。

調參過程更重實踐而非理論。我們逐漸新增層和節點,可以與模型過擬合,因為我們可以用正則化方式再將其調低。重覆該迭代過程直到準確率不再提升,不再值得訓練、計算效能的降低。
但是,GPU 的記憶體是有限的。截止 2018 年初,高階顯示卡 NVIDIA GeForce GTX 1080 TI 的記憶體為 11GB。兩個仿射層之間隱藏節點的最大數量受記憶體大小的限制。
對於非常深層的網路,梯度消失問題很嚴重。我們可以新增跳躍連線(類似 ResNet 中的殘差連線)來緩解該問題。
2. 模型 & 資料集設計變化
以下是提升效能的檢查串列:
-
在驗證資料集中分析誤差(糟糕的預測結果);
-
監控啟用函式。在啟用函式不以零為中心或非正態分佈時,考慮批歸一化或層歸一化;
-
監控無效節點的比例;
-
使用梯度截斷(尤其是 NLP 任務中)來控制梯度爆炸問題;
-
Shuffle 資料集(手動或透過程式);
-
平衡資料集(每個類別具備相似數量的樣本)。
我們應該在啟用函式之前密切監控啟用直方圖。如果它們的規模差別很大,那麼梯度下降將會無效。使用歸一化。如果深度網路有大量無效節點,那麼我們應該進一步追蹤該問題。它可能是由 bug、權重初始化或梯度消失導致的。如果都不是,則試驗一些高階 ReLU 函式,如 leaky ReLU。
3. 資料集收集 & 清洗
如果你想構建自己的資料集,那麼最好的建議就是仔細研究如何收集樣本。找最優質的資源,過濾掉與你問題無關的所有資料,分析誤差。在我們的專案中,具備高度糾纏結構的影象效能非常糟糕。我們可以新增摺積層和小型濾波器來改變模型。但是模型已經很難訓練了。我們可以新增更多糾纏樣本做進一步訓練,但是已經有了很多了……另一種方式:我們可以精細化專案範圍,縮小樣本範圍。
4. 資料增強
收集有標簽的資料是一件昂貴的工作。對於圖片來說,我們可以使用資料增強方法如旋轉、隨機剪裁、移位等方式來對已有資料進行修改,生成更多的資料。顏色失真則包括色調、飽和度和曝光偏移。

5. 半監督學習
我們還可以使用無標註資料補充訓練資料。使用模型分類資料。把具備高置信預測的樣本新增到具備對應標簽預測的訓練資料集中。
6. 調整
-
學習率調整
我們先簡單回顧一下如何調整學習率。在早期開發階段,我們關閉任意非關鍵超引數或設定為 0,包括正則化。在具備 Adam 最佳化器的情況下,預設學習率通常效能就很好了。如果我們對自己的程式碼很有信心,但是損失並沒有下降,則需要調整學習率。典型的學習率在 1 和 1e-7 之間。每次把學習率降低 10%,併在簡短迭代中進行測試,密切監控損失。如果它持續上升,那麼學習率太高了。如果它沒有下降,則學習率太低。提高學習率,直到損失提前變得平緩。
下麵是一個真實樣本,展示了學習率太高的情況,這導致成本突然上漲:
在不經常用的實踐中,人們監控 W ratio 的更新情況:

-
如果 ratio > 1e-3,則考慮調低學習率;
-
如果 ratio < 1e-3,則考慮提高學習率。
-
超引數調整
在模型設計穩定後,我們也可以進一步調整模型。最經常調整的超引數是:
-
mini-batch 尺寸;
-
學習率;
-
正則化因子;
-
特定層的超引數(如 dropout)。
-
Mini-batch 尺寸
通常的批尺寸是 8、16、32 或 64。如果批尺寸太小,則梯度下降不會很順暢,模型學習的速度慢,損失可能會振蕩。如果批尺寸太大,則完成一次訓練迭代(一輪更新)的時間太長,得到的傳回結果較小。在我們的專案中,我們降低批尺寸,因為每次訓練迭代時間太長。我們密切監控整個學習速度和損失。如果損失振蕩劇烈,則我們會知道批尺寸降低的幅度太大了。批尺寸影響正則化因子等超引數。一旦我們確定好批尺寸,我們通常就鎖定了值。
-
學習率 & 正則化因子
我們可以使用上述方法進一步調整學習率和正則化因子。我們監控損失,來控制學習率和驗證與訓練準確率之間的差距,從而調整正則化因子。我們沒有把學習率降低 10%,而是降低 3%(精細調整中或許更小)。
調參不是線性過程。超引數是有關聯的,我們將反覆調整超引數。學習率和正則化因子高度相關,有時需要一起調。不要太早進行精細調整,有可能浪費時間。設計改變的話這些努力就白費了。
-
Dropout
Dropout 率通常在 20% 到 50% 之間。我們先從 20% 開始。如果模型出現過擬合,則提高值。
-
其他調整
-
稀疏度
-
啟用函式
模型引數的稀疏度能使計算最佳化變得簡單,並減少能耗(這對於移動裝置來說至關重要)。如果需要,我們可以用 L1 正則化替代 L2 正則化。ReLU 是最流行的啟用函式。對於一些深度學習競賽,人們使用更高階的 ReLU 變體以提高準確率。在一些場景中它還可以減少無效節點。
-
高階調參
一些高階精細調參方法:
-
學習率衰減排程
-
動量(Momentum)
-
早停
我們沒有使用固定的學習率,而是定期降低學習率。超引數包括學習率下降的頻率和幅度。例如,你可以在每十萬次迭代時減少 0.95 的學習率。要調整這些引數,我們需要監控成本,以確定引數下降地更快但又不至於過早平緩。
高階最佳化器使用動量使梯度下降過程流暢進行。Adam 最佳化器中存在兩種動量設定,分別控制一階(預設 0.9)和二階(預設 0.999)動量。對於具備梯度陡降的問題領域如 NLP,我們可以稍稍提高動量值。
當驗證誤差持續上升時,過擬合可透過停止訓練來緩解。

但是,這隻是概念的視覺化。實時誤差可能暫時上升,然後再次下降。我們可以定期檢查模型,記錄對應的驗證誤差。稍後我們來選擇模型。
7. 網格搜尋
一些超引數是高度相關的。我們應該使用對數尺度上的可能性網格一起調整它們。例如:對於兩個超引數λ和γ,我們從相應的初始值開始,併在每個步驟中將其降低 10 倍:
-
(e-1, e-2, … and e-8);
-
(e-3, e-4, … and e-6)。
相應的網格會是 [(e-1, e-3), (e-1, e-4), … , (e-8, e-5) 和 (e-8, e-6)]。
我們沒有使用明確的交叉點,而是稍微隨機移動了這些點。這種隨機性可能會幫助我們發現一些隱藏的性質。如果最佳點位於網格的邊界(藍色點),我們則會在邊界區域進行重新測試。

網格搜尋的計算量很大。對於較小的專案,它們會被零星使用。我們開始用較少的迭代來調整粗粒度引數。在後期的細調階段,我們會使用更長的迭代,並將數值調至 3(或更低)。
8. 模型集合
在機器學習中,我們可以從決策樹中投票進行預測。這種方法非常有效,因為判斷失誤通常是有區域性性質的:兩個模型發生同一個錯誤的機率很小。在深度學習中,我們可以從隨機猜測開始訓練(提交一個沒有明確設定的隨機種子),最佳化模型也不是唯一的。我們可以使用驗證資料集測試多次選出表現最佳的模型,也可以讓多個模型進行內部投票,最終輸出預測結果。這種方式需要進行多個會話,肯定非常耗費系統資源。我們也可以訓練一次,檢查多個模型,隨後在這個過程中選出表現最佳的模型。透過集合模型,我們可以基於這些進行準確的預測:
-
每個模型預測的”投票”;
-
基於預測置信度進行加權投票。
模型集合在提高一些問題的預測準確率上非常有效,經常會被深度學習資料競賽的隊伍所採用。
9. 模型提升
在微調模型以外,我們也可以嘗試使用模型的不同變體來提升效能。例如,我們可以考慮使用色彩生成器部分或全部替代標準 LSTM。這種概念並不陌生:我們可以分步繪製圖片。

直觀地說,在影象生成任務中引入時間序列方法是有優勢的,這種方法已經在 DRAW: A Recurrent Neural Network For Image Generation 中被證明過了。
-
微調與模型提升
效能重大提升的背後往往是模型設計的改變。不過有些時候對模型進行微調也可以提升機器學習的效能。最終的判斷可能會取決於你對相應任務的基準測試結果。
10. Kaggle
在開發過程中,你或許會有一些簡單的問題,如:我需要使用 Leak ReLU 嗎?。有時候問題很簡單,但你永遠無法在任何地方找到答案。在一些論文中,你會看到 Leak ReLU 的優越性,但另一些專案的經驗顯示並沒有效能提升。太多的專案,太多的變數都缺乏衡量多種可能性的驗證結果。Kaggle 是一個資料科學競賽的開放平臺,其中深度學習是很重要的一部分。深入觀察一些優秀選手的方法,你或許就可以找到最為普遍的效能指標了。而且,一些資料競賽團隊還會把自己的程式碼(被稱為 kernel)上傳開源。只要留心探索,Kaggle 會是一個很棒的資訊源。
11. 實驗框架
深度學習開發需要依賴大量經驗,調節超引數是一件非常乏味的工作。建立一個實驗框架可以加速這一過程。例如:一些人會開發程式碼將模型定義外化為字串以便調節。然而這些努力通常不能為小團隊帶來收益。以我的經驗,這樣做的話程式碼的簡潔性和可追溯性損失會遠比受益要大,這意味著難以對程式碼進行簡單的修改。易於閱讀的程式碼必然有著簡潔和靈活的特性。與此相反,很多 AI 雲產品已經開始提供自動調節超引數的特性。雖然目前這種技術仍處於初始階段,但無需人類自己編寫框架的流程應該是大勢所趨,請時刻註意這一趨勢。
12. 結論
現在,你已擁有了調整完畢的模型,可以正式部署了。希望這個系列教程對你有所幫助。深度學習可以幫助我們解決很多問題——其適用範圍超出你的想象。想使用深度學習代替前端設計?你可以嘗試一下 pix2code!
原文連結(需翻牆):
https://medium.com/@jonathan_hui/how-to-start-a-deep-learning-project-d9e1db90fa72
https://medium.com/@jonathan_hui/build-a-deep-learning-dataset-part-2-a6837ffa2d9e
https://medium.com/@jonathan_hui/deep-learning-designs-part-3-e0b15ef09ccc
https://medium.com/@jonathan_hui/visualize-deep-network-models-and-metrics-part-4-9500fe06e3d0
https://medium.com/@jonathan_hui/debug-a-deep-learning-network-part-5-1123c20f960d
https://medium.com/@jonathan_hui/improve-deep-learning-models-performance-network-tuning-part-6-29bf90df6d2d
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
