原文題目:Propensity Modeling, Causal Inference, and Discovering Drivers of Growth
作者:Edwin Chen 翻譯:張逸 校對:盧苗苗
本文共5400字,建議閱讀9分鐘。
本文透過舉例為你介紹因果推測方法、傾向建模及增長的驅動因素。
在正文之前,先想象這樣一個場景。
你剛開始一份新工作,而且最近看了《僵屍世界大戰》這部電影,正處於一種懷疑人生的狀態。再加上前不久你的兩個初創公司因為缺乏資料開不下去了,所以你看什麼都不太順眼。
你最先開始考慮銷售團隊的影響。他們到底為公司帶來了多少額外的收入?你遇見的銷售人員們說他們推銷的客戶有90%都買了公司的產品,但你還是心存疑問:這些客戶中,到底有多少是因為銷售員的功勞才決定購買的?
所以你查看了工作日誌,並且註意到一些有意思的事兒:上個星期是hack week,一半的銷售員都因為要打電話收集資料而騰不出空來,然而這一週客戶的轉化率卻沒有發生變化。
正在百思不得其解的時候,一個同事走到桌邊來。他拿了一提Soylent飲料,想讓你嘗嘗。這個飲料看起來不怎麼樣,所以你問同事它好在哪,同事說他朋友喝了這個飲料幾個月以後就能跑馬拉鬆了。所以呢?他們剛開始跑嗎?–當然不是,人家去年就能跑馬拉鬆了!
Causal Inference(因果推斷)
事物之間的因果關係毫無疑問是很重要的,但難點就在於如何確定這種關係。
考慮以下幾個問題:
-
某個病人吃了一種新藥以後身體情況有所好轉,這種好轉是因為藥物的作用還是本來他的身體就在恢復?
-
是你的銷售團隊確實起到了作用,還是他們僅僅是向那些本來就要購買商品的客戶進行了推銷?
-
喝Soylent飲料(或者你公司的巨額廣告投入)值得嗎?
在理想世界中,只要我們樂意,就可以做實驗來驗證—實驗才是檢驗因果關係的最好標準。但現實情況是我們不能這樣做。就拿剛才那些例子來說,你不能讓病人服用安慰劑或者未經測試的藥品,這是有違道德的。而且公司經理們恐怕不會願意為了潛在的短期收益把精力放在隨機的客戶上。同理,那些靠銷售額領取獎金的銷售團隊也會反對這樣做。
那麼我們應該如何在沒有A/B測試的情況下理解因果關係?這就是propensity modeling(傾向建模)和其他因果推斷技術發揮作用的地方。
Propensity Modeling(傾向建模)
繼續Soylent飲料的例子,我們用傾向建模的技術來分析喝soylent飲料到底有什麼作用。為瞭解釋清楚這個概念,接下來要開始一場思想實驗。
假定Brad Pitt有一個雙胞胎的哥哥,兄弟倆哪都一樣:Brad1和Brad2一起起床,吃一樣的事物,進行同樣強度的體能鍛煉等等。有一天,Brad 1 碰巧從街上的促銷員那裡得到了最後一打Soylent飲料,但Brad 2沒有這樣的好運氣。所以Soylent只出現在了Brad1的食譜上。在這種情況下,可以認為,雙胞胎此後出現的任何行為差異就是這個飲料造成的。
將這種情景帶入現實世界,我們用下麵的方法來估計Soylent對健康的影響:
-
對於每一個喝Soylent的人來說,找到一個各方面都比較接近他的不喝這個飲料的人。比如我們會將喝Soylent的Jay-Z和不喝Soylent的Kanye當做一組,或者喝Soylent的Keira 配對不喝Soylent的Knightley這樣。
-
接下來我們就觀察二者的不同之處來量化soylent的影響。
然而,在實踐時找到兩個非常相近的雙胞胎是很困難的,如果Jay-Z比Kanye平均多睡一個小時,那麼怎麼保證二者真的很接近呢?
Propensity modeling(傾向建模)就是這種雙胞胎匹配過程的簡化。我們並不是根據所有的變數來匹配兩個個體,而是根據一個簡單的數字來匹配所有使用者—–他們喝soylent的可能性(“傾向”)
下麵是建立傾向分析的細節:
-
首先,選定一些變數作為特徵(比如吃的食物種類,睡眠時間,居住地點等)
-
根據這些變數建立一個機率模型(即邏輯斯特回歸)預測人們是否會喝Soylent。比如說,我們的訓練集由一群人組成,其中有一部分人在2014年3月的第一週訂購了Soylent,我們會訓練一個分類器來對哪些人會喝Soylent進行建模。
-
該模型將使用者開始飲用Soylent的機率估計稱為“傾向得分”
-
形成一定數量的“桶”,比如總計有十個等級(第一個桶代表喝飲料的傾向是0.0-0.1,第二個桶是0.1-0.2,以此類推),將所有的實驗資料放入對應的“桶”中。
-
最後,比較每個桶中喝飲料與不喝飲料的樣本資料(比如測量他們隨後的身體素質、體重或者任何其他健康指標)來估計Soylent的因果效應。

比如說,這有一個虛構的喝與不喝Soylent人群年齡的分佈圖。我們可以看到,喝Soylent的人群年齡要稍大一些。這個混雜的事實是我們不能簡單地進行相關性分析的原因之一。
在訓練好Soylent傾向估計的模型並將使用者分配到對應桶中後,下邊這幅圖展示了Soylent對一個人每週運動里程的影響。

在上面的圖表(假設的)中,每一幅行都代表了不同傾向等級的人群,開頭代表的是三月的第一週,此時對照組收到了他們的Soylent飲料。在這個星期之前,我們可以看出,兩組的資料軌跡差異不大,但當對照組開始按計劃飲用Soylent之後,他們每週跑步的距離增加,這就形成了我們對飲料因果效應的估計。
當然,還有一些其他的因果推測方法。下麵會講兩個我最喜歡的:
Regression Discontinuity(斷點回歸法)
這個例子是這樣的:
Quora最近開始在它的top writers主頁上展示徽章,我們想知道這個功能到底會產生什麼樣的影響。(假設現在功能已經上線,不能進行A/B測試了)。更具體的,我們想知道在主頁展示徽章這個功能會不會給使用者增加更多的關註者?
為了簡化分析,假定2013一整年中獲得贊數超過5000的使用者有資格獲得徽章。那麼斷點回歸的關註點是那些剛剛好獲得徽章(即有5000個贊)和那些差一點夠資格(獲得4999個贊)的使用者,他們之間的差異或多或少是隨機的。我們可以用這個閾值來估計因果效應。
比如說,在下麵這個虛構的圖表中,在5000贊這個界限處的不連續性表明,獲得勛章的作者平均會多大約100多個粉絲。

自然實驗法
不過,理解了top writer徽章的作用並沒有什麼意思,它只是為瞭解釋這個概念舉的簡單例子。更值得深入探討的問題是:當使用者新發現了一個喜歡的作者後會怎麼樣?作者是否激勵他們寫一些他們自己的內容,去探索更多的相同的內容,並透過管理使他們更多參與到網站呢?換句話說,跟使用者瀏覽隨機的帖子相比,他們與這些厲害的作者之間建立聯絡是不是很重要?
為了更進一步討論,得暫且先把這個虛構的Quora案例放下。來看看一個我在谷歌工作時研究的類似問題。
例如很多人會選擇週日晚上待在家裡追家庭主婦的更新,看完劇以後,人們可能就會停在這個頻道上找其他節目來看。
這個問題是這樣的:現在我們想知道給使用者匹配一個“完美的YouTube頻道”之後會發生什麼,這種推薦的價值在何處?
-
使用者對某一新頻道的喜愛會不會帶來對該頻道一些超出本身的關註度? 因為使用者可能會專門傳回YouTube並留在新頻道觀看更多的節目。(倍增效應)
-
喜歡上一個新頻道是否會增加在這個頻道上的活動?(正面的影響)
-
新頻道是否取代了YouTube上現有的互動?畢竟使用者沒有多少時間能花在網站上(中立的影響)
-
完美頻道是否真的減少了使用者在網站上花費的時間?因為他們一旦知道怎麼迅速直接的找到想看的東西,就不會再網站上閑逛很久(負面的影響)。
同樣的,在這個案例中進行A/B測試是不現實的,因為不能強制讓使用者喜歡或阻止他們瀏覽某一個頻道(我們可以進行推薦,但不能保證使用者會買賬)。
一個解決辦法是利用自然實驗(在這個場景中,經驗本身產生了類似隨機的賦值。)來研究這種影響。以下是具體的方法:
設想某個使用者在每週三都上傳一個新影片。一個月之後,因為要去旅遊,所以他通知收看這個頻道的其他使用者接下來的幾周都不會有影片上傳。
這些使用者這時候會有什麼反應?因為只有這個頻道能夠訪問YouTube,所以他們在星期三就不上YouTube了嗎?還是根本沒有什麼影響,因為這些使用者只有在首頁上出現這些影片的時候才會點開看?
想象一下,如果這個頻道改在每週五上傳影片,這些使用者還會不會繼續關註它?既然他們正在訪問YouTube,他們只是為了新的影片,或許只是他們的訪問導致了一連串的搜尋和相關的內容?
事實證明,這種情況經常會發生。比如以下是一個受歡迎的頻道上傳影片的日曆。你可以看到,在2011年,它喜歡在週二和週五上傳影片,但在年底的時候改為週三和週六。
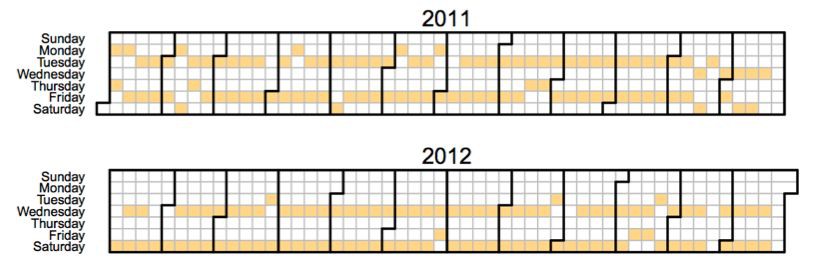
把這種轉變當做一個自然實驗,就好像是“隨機”地把特定時間一個受歡迎的頻道轉移到另外的日子。從這,我們可以理解一個好的推薦的重要性。
上邊這個例子作為一個自然實驗有點過於複雜了,為了更清晰的闡明這個觀點,假設我們需要理解收入情況對精神健康的影響,我們不能強行讓一些人變得有錢或者沒錢,與之相關的研究顯然存在不足。這篇文章(連結:https://opinionator.blogs.nytimes.com/2014/01/18/what-happens-when-the-poor-receive-a-stipend/)描述了一種自然實驗,即一群切諾基印第安人在向其成員分發開賭場所得的利潤時,會“隨機”地讓其中一些人擺脫貧困。
在我上述的場景中,假定程式設計週期間並沒有什麼特別之處,另一個例子就是利用程式設計周,將其作為能類似隨機“阻止”銷售團隊完成他們的工作的工具。
驅動力發掘
讓我們回到傾向建模這個問題。
假設現在我們成為公司發展團隊的一員,當下的任務是弄清楚如何才能將那些隨機的使用者轉換成為常客。
這時可以採取傾向建模的方法。我們選擇一些特徵(比如說手機APP,登入註冊資訊,對某特定使用者的關註等等)併為每一個特徵建立一個傾向模型。然後,我們可以對所有參與因果估計的特徵進行排名,用這個有序的特徵串列來決定我們下一次的標的群體。(或者我們使用這些資料告訴執行團隊我們需要更多的資源)。這是構建參與回歸模型(或流失回歸模型)以及檢查每個特徵權重的一個稍微更複雜的方法。
不過即便是寫了這個帖子,我也並不熱衷於對技術領域的很多應用進行傾向建模。(我沒有在醫療領域工作過,所以不敢保證它的實用性到底怎樣,但我覺得可能在這個領域還是比較需要傾向建模),就算下一次遇到類似的場景,我也會保留更多的意見。畢竟,進行因果推斷是非常困難的,我們沒辦法控制所有的潛在影響因素,而這些因素恰恰會給實驗結果帶來偏差。另外,我們必須選擇要包含在模型當中的特徵(記住,構建特徵非常耗時而且很困難)。這一點意味著我們對這些特徵是否有用已經有了明確的判斷,但是我們真正想做的卻是發現那些隱藏的動機。
那麼接下來還能怎麼辦?
打個比方,如果想知道為什麼有些使用者會成為網站的深度使用者,我們何不直接問他們呢?
具體來說,我們可以這樣做:
-
首先選定幾百個使用者群體進行調查
-
在問卷中,我們會問使用者,與去年相比,他們參與某一個網站的程度是增加,下降還是基本保持不變?緊接著,詢問使用者為什麼會出現這種變化,讓他們描述最近一次瀏覽這個網站的情況,或者讓他們補充一些細節(例如他們的人口統計資訊)。
-
最後,我們把在去年一年中參與度明顯增加的使用者的反饋篩選出來(如果相反,則選出顯著下降的人群),分析他們給出的原因。
比如,下麵是我在YouTube上進行此項研究時收到的一個有意思的反饋。

“我是一個音樂重度粉,最近沉迷於彈吉他,所以這一段時間會在YouTube上多看一些音樂會還有其他音樂相關的影片。當然了,包括很多的吉他教學影片(網址是www.justinguitar.com)”
從這個反饋中我們發現:使用者有了一個新的線下愛好,然後會將這種愛好轉嫁到YouTube上。這很好理解,比如想要開始在家做飯的人會到YouTube上尋找烹飪教程,想要開始打網球或者其他運動的使用者會去找教學影片,大學生會找一些類似可汗學院的頻道來輔助學習。換句話說,線下的活動會影響到線上行為。在這種情況下,我們就無需猜測使用者到底對什麼內容感興趣(比如說,他們喜歡Facebook上的什麼文章,他們在Twitter上追棒誰,他們喜歡Reddit上的什麼文章),而是將關註點放在怎麼把這些現實生活中的喜好轉化到數字世界中。
這種“線下愛好”的想法肯定不會成為我投入到任何參與樣式中的一個特徵,即使只是因為這種特徵很難生成。(我們怎麼能知道哪些影片是與真實世界的喜好相對應的呢?)
但是既然我們懷疑它是一種潛在的增長驅動力(“潛在”,因為調查不一定具有代表性),這是我們可以深入探討的問題。
結語
總結一下:在沒有條件進行隨機試驗的時候,傾向建模是判斷因果影響的一個有力技術手段。
不過,這種建立在觀察研究之上的純粹的相關性分析可能會產生一些誤導。舉一個我最喜歡的例子:我們發現某個城市警察越多,犯罪案件可能會越多—但這總不能意味著我們應該為了減少犯罪數量而減少警力吧?
還有一個例子,Gelman曾就研究激素替代療法得出的矛盾結論在哈佛護士健康研究上發了一個帖子(有興趣的朋友可以詳細看一下,這裡不展開講了)(http://andrewgelman.com/2005/01/07/could_propensit/)
也就是說,只有資料足夠優質,得到的模型才會比較好。但是我們又很難去把所有的隱藏變數考慮在內,結果就是可能你絞盡腦汁設計出來的模型在實際中並不比隨機模型好多少。因此,可以考慮是不是還有其他的方法,無論是易於理解的因果分析技術,還是簡單的去對使用者進行調研,甚至說目前比較難實現的隨機試驗等等,這些最後都會對你的研究有幫助。
原文連結:http://blog.echen.me/2014/08/15/propensity-modeling-causal-inference-and-discovering-drivers-of-growth/
譯者簡介:張逸,中國傳媒大學大三在讀,主修數字媒體技術。對資料科學充滿好奇,感慨於它創造出來的新世界。目前正在摸索和學習中,希望自己勇敢又熱烈,學最有意思的知識,交最志同道合的朋友。
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
