(點選上方藍字,快速關註我們)
英文:Curtis Miller,編譯:伯樂線上 – 小米雲豆粥
這篇博文是用Python分析股市資料系列兩部中的第二部,內容基於我在猶他大學 數學3900 (資料科學)的課程 (閱讀第一部分《用 Python 做股市資料分析(一)》)。在這兩篇博文中,我會討論一些基礎知識,包括比如如何用pandas從雅虎財經獲得資料, 視覺化股市資料,平均數指標的定義,設計移動平均交匯點分析移動平均線的方法,回溯測試和 基準分析法。這篇文章會討論如何設計用移動平均交匯點分析移動平均線的系統,如何做回溯測試和基準分析,最後留有一些練習題以饗讀者。
註意:本文僅代表作者本人的觀點。文中的內容不應該被當做經濟建議。我不對文中程式碼負責,取用者自己負責
交易策略
在特定的預期條件達成時一個開放頭寸會被關閉。多頭頭寸表示交易中需要金融商品價格上升才能產生盈利,空頭頭寸表示交易中需要金融商品價格下降才能產生盈利。在股票交易中,多頭頭寸是牛市,空頭頭寸是熊市,反之則不成立。(股票期權交易中這個非常典型)
例如你在預計股價上漲的情況下購入股票,並計劃在股票價格上漲高於購入價時丟擲,這就是多頭頭寸。就是說你持有一定的金融產品,如果它們價格上漲,你將會獲利,並且沒有上限;如果它們價格下降,你會虧損。由於股票價格不會為負,虧損是有限度的。相反的,如果你預計股價會下跌,就從交易公司借貸股票然後賣出,同時期待未來股票價格下降後再低價買入還貸來賺取差額,這就是空頭股票。如果股價下跌你會獲利。空頭頭寸的獲利額度受股價所限(最佳情況就是股票變得一文不值,你不用花錢就能將它們買回來),而損失卻沒有下限,因為你有可能需要花很多錢才能買回股票。所以交換所只會在確定投資者有很好的經濟基礎的情況下才會讓他們空頭借貸股票。
所有股民都應該決定他在每一股上可以冒多大的風險。比如有人決定無論什麼情況他都不會在某一次交易中投入總額的10%去冒險。同時在交易中,股民要有一個撤出策略,這是讓股民退出頭寸的各種條件。股民也可以設定一個標的,這是導致股民退出頭寸的最小盈利額。同樣的,股民也需要有一個他能承受的最大損失額度。當預計損失大於可承受額度時,股民應該退出頭寸以避免更大損失(這可以透過設定停止損失委託來避免未來的損失)。
我們要設計一個交易策略,它包含用於快速交易的交易激發訊號、決定交易額度的規則和完整的退出策略。我們的標的是設計並評估該交易策略。
假設每次交易金額佔總額的比例是固定的(10%)。同時設定在每一次交易中,如果損失超過了20%的交易值,我們就退出頭寸。現在我們要決定什麼時候進入頭寸,什麼時候退出以保證盈利。
這裡我要演示移動平均交匯點分析移動平均線的方法。我會使用兩條移動平均線,一條快速的,另一條是慢速的。我們的策略是:
-
當快速移動平均線和慢速移動線交匯時開始交易
-
當快速移動平均線和慢速移動線再次交匯時停止交易
做多是指在快速平均線上升到慢速平均線之上時開始交易,當快速平均線下降到慢速平均線之下時停止交易。賣空正好相反,它是指在快速平均線下降到慢速平均線之下時開始交易,快速平均線上升到慢速平均線之上時停止交易。
現在我們有一整套策略了。在使用它之前我們需要先做一下測試。回溯測試是一個常用的測試方法,它使用歷史資料來看策略是否會盈利。例如這張蘋果公司的股票價值圖,如果20天的移動平均是快速線,50天的移動平均是慢速線,那麼我們這個策略不是很掙錢,至少在你一直做多頭頭寸的時候。
下麵讓我們來自動化回溯測試的過程。首先我們要識別什麼時候20天平均線在50天之下,以及之上。
apple[’20d-50d’] =apple[’20d’] –apple[’50d’]
apple.tail()

我們將差異的符號稱為狀態轉換。快速移動平均線在慢速移動平均線之上代表牛市狀態;相反則為熊市。以下的程式碼用於識別狀態轉換。
# np.where() is a vectorized if-else function, where a condition is checked for each component of a vector, and the first argument passed is used when the condition holds, and the other passed if it does not
apple[“Regime”] = np.where(apple[’20d-50d’] > 0, 1, 0)
# We have 1’s for bullish regimes and 0’s for everything else. Below I replace bearish regimes’s values with -1, and to maintain the rest of the vector, the second argument is apple[“Regime”]
apple[“Regime”] = np.where(apple[’20d-50d’] 0, –1, apple[“Regime”])
apple.loc[‘2016-01-01’:‘2016-08-07’,“Regime”].plot(ylim = (–2,2)).axhline(y = 0, color = “black”, lw = 2)

apple[“Regime”].plot(ylim =(-2,2)).axhline(y =0, color =”black”, lw =2)
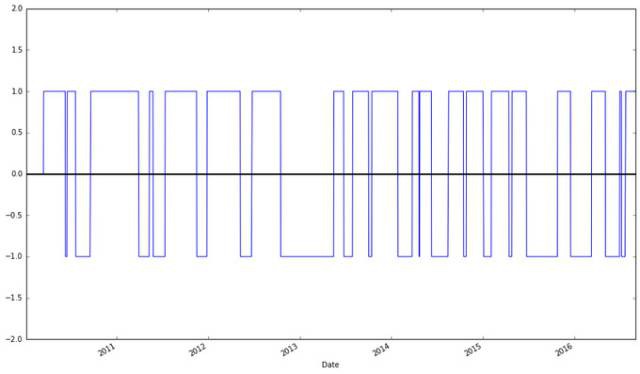
apple[“Regime”].value_counts()
1 966
–1 663
0 50
Name: Regime, dtype: int64
從上面的曲線可以看到有966天蘋果公司的股票是牛市,663天是熊市,有54天沒有傾向性。(原文中牛市和熊市說反了,譯文中更正;原文數字跟程式碼結果對不上,譯文按照程式碼結果更正)
交易訊號出現在狀態轉換之時。牛市出現時,買入訊號被啟用;牛市完結時,賣出訊號被啟用。同樣的,熊市出現時賣出訊號被啟用,熊市結束時,買入訊號被啟用。(只有在你空頭股票,或者使用一些其他的方法例如用股票期權賭市場的時候這種情況才對你有利)

# To ensure that all trades close out, I temporarily change the regime of the last row to 0
regime_orig = apple.ix[–1, “Regime”]
apple.ix[–1, “Regime”] = 0
apple[“Signal”] = np.sign(apple[“Regime”] – apple[“Regime”].shift(1))
# Restore original regime data
apple.ix[–1, “Regime”] = regime_orig
apple.tail()

apple[“Signal”].plot(ylim =(-2, 2))

apple[“Signal”].value_counts()
0.0 1637
–1.0 21
1.0 20
Name: Signal, dtype: int64
我們會買入蘋果公司的股票20次,丟擲21次 (原文數字跟程式碼結果不符,譯文根據程式碼結果更正)。如果我們只選了蘋果公司的股票,六年內只有21次交易發生。如果每次多頭轉空頭的時候我們都採取行動,我們將會參與21次交易。(請記住交易次數不是越多越好,畢竟交易不是免費的)
你也許註意到了這個系統不是很穩定。快速平均線在慢速平均線之上就激發交易,即使這個狀態只是短短一瞬,這樣會導致交易馬上終止(這樣並不好因為現實中每次交易都要付費,這個費用會很快消耗掉收益)。同時所有的牛市瞬間轉為熊市,如果你允許同時押熊市和牛市,那就會出現每次交易結束就自動激發另一場押相反方向交易的詭異情況。更好的系統會要求有更多的證據來證明市場的發展方向,但是這裡我們不去追究那個細節。
下麵我們來看看每次買入賣出時候的股票價格。
apple.loc[apple[“Signal”] ==1, “Close”]
Date
2010–03–16 224.449997
2010–06–18 274.070011
2010–09–20 283.230007
2011–05–12 346.569988
2011–07–14 357.770004
2011–12–28 402.640003
2012–06–25 570.770020
2013–05–17 433.260010
2013–07–31 452.529984
2013–10–16 501.110001
2014–03–26 539.779991
2014–04–25 571.939980
2014–08–18 99.160004
2014–10–28 106.739998
2015–02–05 119.940002
2015–04–28 130.559998
2015–10–27 114.550003
2016–03–11 102.260002
2016–07–01 95.889999
2016–07–25 97.339996
Name: Close, dtype: float64
apple.loc[apple[“Signal”] ==-1, “Close”]
Date
2010–06–11 253.509995
2010–07–22 259.020000
2011–03–30 348.630009
2011–03–31 348.510006
2011–05–27 337.409992
2011–11–17 377.410000
2012–05–09 569.180023
2012–10–17 644.610001
2013–06–26 398.069992
2013–10–03 483.409996
2014–01–28 506.499977
2014–04–22 531.700020
2014–06–11 93.860001
2014–10–17 97.669998
2015–01–05 106.250000
2015–04–16 126.169998
2015–06–25 127.500000
2015–12–18 106.029999
2016–05–05 93.239998
2016–07–08 96.680000
2016–09–01 106.730003
Name: Close, dtype: float64
# Create a DataFrame with trades, including the price at the trade and the regime under which the trade is made.
apple_signals = pd.concat([
pd.DataFrame({“Price”: apple.loc[apple[“Signal”] == 1, “Close”],
“Regime”: apple.loc[apple[“Signal”] == 1, “Regime”],
“Signal”: “Buy”}),
pd.DataFrame({“Price”: apple.loc[apple[“Signal”] == –1, “Close”],
“Regime”: apple.loc[apple[“Signal”] == –1, “Regime”],
“Signal”: “Sell”}),
])
apple_signals.sort_index(inplace = True)
apple_signals

# Let’s see the profitability of long trades
apple_long_profits = pd.DataFrame({
“Price”: apple_signals.loc[(apple_signals[“Signal”] == “Buy”) &
apple_signals[“Regime”] == 1, “Price”],
“Profit”: pd.Series(apple_signals[“Price”] – apple_signals[“Price”].shift(1)).loc[
apple_signals.loc[(apple_signals[“Signal”].shift(1) == “Buy”) & (apple_signals[“Regime”].shift(1) == 1)].index
].tolist(),
“End Date”: apple_signals[“Price”].loc[
apple_signals.loc[(apple_signals[“Signal”].shift(1) == “Buy”) & (apple_signals[“Regime”].shift(1) == 1)].index
].index
})
apple_long_profits
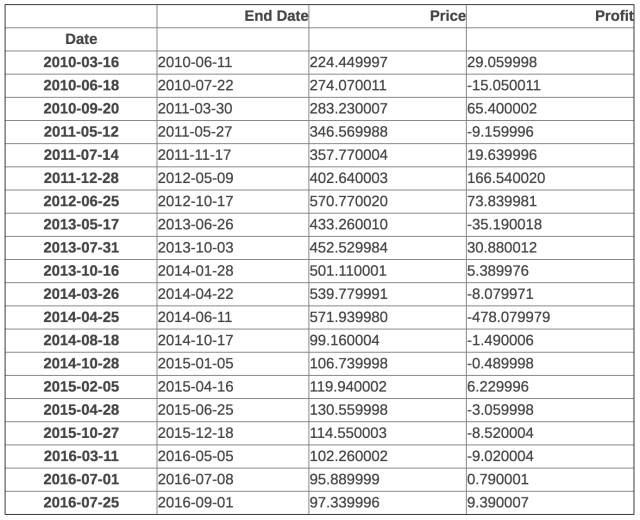
從上表可以看出2013年5月17日那天蘋果公司股票價格大跌,我們的系統會表現很差。但是那個價格下降不是因為蘋果遇到了什麼大危機,而僅僅是一次分股。由於分紅不如分股那麼顯著,這也許會影響系統行為。
# Let’s see the result over the whole period for which we have Apple data
pandas_candlestick_ohlc(apple, stick = 45, otherseries = [“20d”, “50d”, “200d”])

我們不希望我們的交易系統的表現受到分紅和分股的影響。一個解決方案是利用歷史的分紅分股資料來設計交易系統,這些資料可以真實地反映股市的行為從而幫助我們找到最佳解決方案,但是這個方法要更複雜一些。另一個方案就是根據分紅和分股來調整股票的價格。
雅虎財經只提供調整之後的股票閉市價格,不過這些對於我們調整開市,高價和低價已經足夠了。調整閉市股價是這樣實現的:

讓我們回到開始,先調整股票價格,然後再來評價我們的交易系統。
def ohlc_adj(dat):
“””
:param dat: pandas DataFrame with stock data, including “Open”, “High”, “Low”, “Close”, and “Adj Close”, with “Adj Close” containing adjusted closing prices
:return: pandas DataFrame with adjusted stock data
This function adjusts stock data for splits, dividends, etc., returning a data frame with
“Open”, “High”, “Low” and “Close” columns. The input DataFrame is similar to that returned
by pandas Yahoo! Finance API.
“””
return pd.DataFrame({“Open”: dat[“Open”] * dat[“Adj Close”] / dat[“Close”],
“High”: dat[“High”] * dat[“Adj Close”] / dat[“Close”],
“Low”: dat[“Low”] * dat[“Adj Close”] / dat[“Close”],
“Close”: dat[“Adj Close”]})
apple_adj = ohlc_adj(apple)
# This next code repeats all the earlier analysis we did on the adjusted data
apple_adj[“20d”] = np.round(apple_adj[“Close”].rolling(window = 20, center = False).mean(), 2)
apple_adj[“50d”] = np.round(apple_adj[“Close”].rolling(window = 50, center = False).mean(), 2)
apple_adj[“200d”] = np.round(apple_adj[“Close”].rolling(window = 200, center = False).mean(), 2)
apple_adj[’20d-50d’] = apple_adj[’20d’] – apple_adj[’50d’]
# np.where() is a vectorized if-else function, where a condition is checked for each component of a vector, and the first argument passed is used when the condition holds, and the other passed if it does not
apple_adj[“Regime”] = np.where(apple_adj[’20d-50d’] > 0, 1, 0)
# We have 1’s for bullish regimes and 0’s for everything else. Below I replace bearish regimes’s values with -1, and to maintain the rest of the vector, the second argument is apple[“Regime”]
apple_adj[“Regime”] = np.where(apple_adj[’20d-50d’] 0, –1, apple_adj[“Regime”])
# To ensure that all trades close out, I temporarily change the regime of the last row to 0
regime_orig = apple_adj.ix[–1, “Regime”]
apple_adj.ix[–1, “Regime”] = 0
apple_adj[“Signal”] = np.sign(apple_adj[“Regime”] – apple_adj[“Regime”].shift(1))
# Restore original regime data
apple_adj.ix[–1, “Regime”] = regime_orig
# Create a DataFrame with trades, including the price at the trade and the regime under which the trade is made.
apple_adj_signals = pd.concat([
pd.DataFrame({“Price”: apple_adj.loc[apple_adj[“Signal”] == 1, “Close”],
“Regime”: apple_adj.loc[apple_adj[“Signal”] == 1, “Regime”],
“Signal”: “Buy”}),
pd.DataFrame({“Price”: apple_adj.loc[apple_adj[“Signal”] == –1, “Close”],
“Regime”: apple_adj.loc[apple_adj[“Signal”] == –1, “Regime”],
“Signal”: “Sell”}),
])
apple_adj_signals.sort_index(inplace = True)
apple_adj_long_profits = pd.DataFrame({
“Price”: apple_adj_signals.loc[(apple_adj_signals[“Signal”] == “Buy”) &
apple_adj_signals[“Regime”] == 1, “Price”],
“Profit”: pd.Series(apple_adj_signals[“Price”] – apple_adj_signals[“Price”].shift(1)).loc[
apple_adj_signals.loc[(apple_adj_signals[“Signal”].shift(1) == “Buy”) & (apple_adj_signals[“Regime”].shift(1) ==1)].index
].tolist(),
“End Date”: apple_adj_signals[“Price”].loc[
apple_adj_signals.loc[(apple_adj_signals[“Signal”].shift(1) == “Buy”) & (apple_adj_signals[“Regime”].shift(1) ==1)].index
].index
})
pandas_candlestick_ohlc(apple_adj, stick = 45, otherseries = [“20d”, “50d”, “200d”])

apple_adj_long_profits
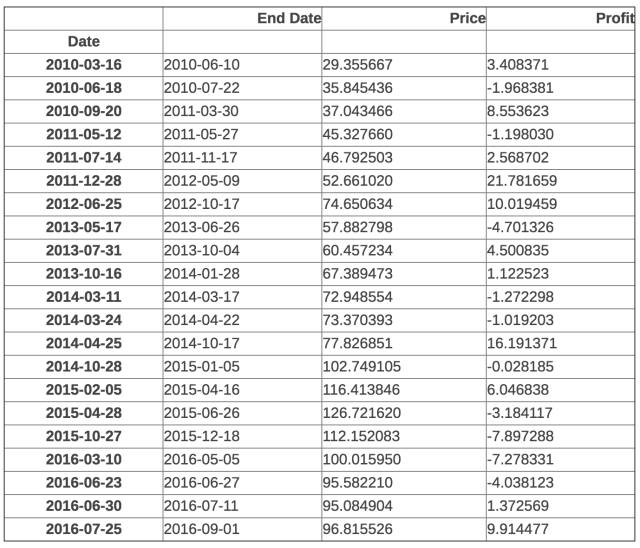
可以看到根據分紅和分股調整之後的價格圖變得很不一樣了。之後的分析我們都會用到這個調整之後的資料。
假設我們在股市有一百萬,讓我們來看看根據下麵的條件,我們的系統會如何反應:
-
每次用總額的10%來進行交易
-
退出頭寸如果虧損達到了交易額的20%
模擬的時候要記住:
-
每次交易有100支股票
-
我們的避損規則是當股票價格下降到一定數值時就丟擲。我們需要檢查這段時間內的低價是否低到可以出發避損規則。現實中除非我們買入看空期權,我們無法保證我們能以設定低值價格賣出股票。這裡為了簡潔我們將設定值作為賣出值。
-
每次交易都會付給中介一定的佣金。這裡我們沒有考慮這個。
下麵的程式碼演示瞭如何實現回溯測試:
# We need to get the low of the price during each trade.
tradeperiods =pd.DataFrame({“Start”: apple_adj_long_profits.index,
“End”: apple_adj_long_profits[“End Date”]})
apple_adj_long_profits[“Low”] =tradeperiods.apply(lambdax: min(apple_adj.loc[x[“Start”]:x[“End”], “Low”]), axis =1)
apple_adj_long_profits

# Now we have all the information needed to simulate this strategy in apple_adj_long_profits
cash =1000000
apple_backtest =pd.DataFrame({“Start Port. Value”: [],
“End Port. Value”: [],
“End Date”: [],
“Shares”: [],
“Share Price”: [],
“Trade Value”: [],
“Profit per Share”: [],
“Total Profit”: [],
“Stop-Loss Triggered”: []})
port_value =.1# Max proportion of portfolio bet on any trade
batch =100# Number of shares bought per batch
stoploss =.2# % of trade loss that would trigger a stoploss
forindex, row inapple_adj_long_profits.iterrows():
batches =np.floor(cash *port_value) //np.ceil(batch *row[“Price”]) # Maximum number of batches of stocks invested in
trade_val =batches *batch *row[“Price”] # How much money is put on the line with each trade
ifrow[“Low”] (1–stoploss) *row[“Price”]: # Account for the stop-loss
share_profit =np.round((1–stoploss) *row[“Price”], 2)
stop_trig =True
else:
share_profit =row[“Profit”]
stop_trig =False
profit =share_profit *batches *batch # Compute profits
# Add a row to the backtest data frame containing the results of the trade
apple_backtest =apple_backtest.append(pd.DataFrame({
“Start Port. Value”: cash,
“End Port. Value”: cash +profit,
“End Date”: row[“End Date”],
“Shares”: batch *batches,
“Share Price”: row[“Price”],
“Trade Value”: trade_val,
“Profit per Share”: share_profit,
“Total Profit”: profit,
“Stop-Loss Triggered”: stop_trig
}, index =[index]))
cash =max(0, cash +profit)
apple_backtest
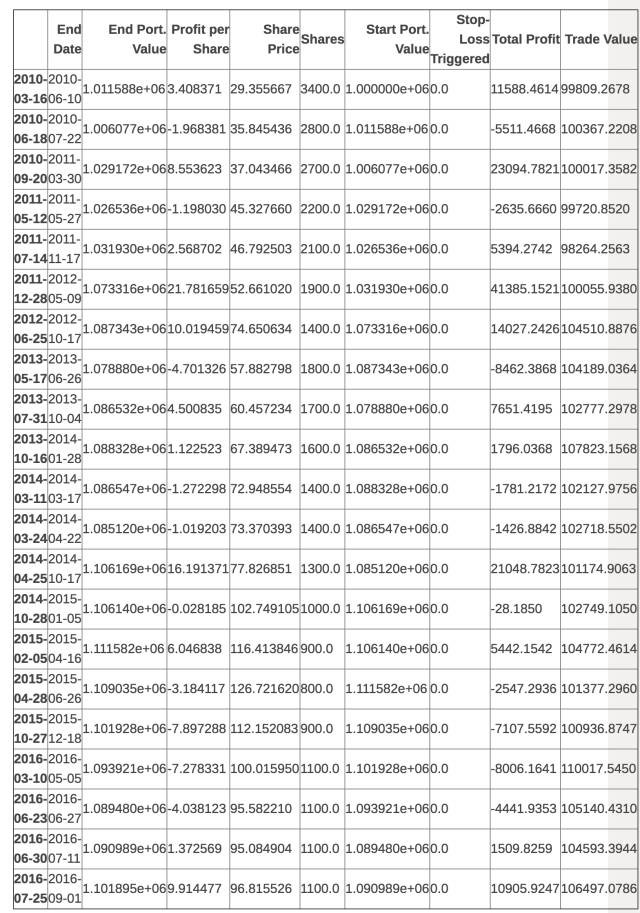
apple_backtest[“End Port. Value”].plot()

我們的財產總額六年增加了10%。考慮到每次交易額只有總額的10%,這個成績不算差。
同時我們也註意到這個策略並沒有引發停止損失委託。這意味著我們可以不需要它麼?這個難說。畢竟這個激發事件完全取決於我們的設定值。
停止損失委託是被自動啟用的,它並不會考慮股市整體走勢。也就是說不論是股市真正的走低還是暫時的波動都會激發停止損失委託。而後者是我們需要註意的因為在現實中,由價格波動激發停止損失委託不僅讓你支出一筆交易費用,同時還無法保證最終的賣出價格是你設定的價格。
下麵的連結分別支援和反對使用停止損失委託,但是之後的內容我不會要求我們的回溯測試系統使用它。這樣可以簡化系統,但不是很符合實際(我相信工業系統應該有停止損失委託)。
現實中我們不會只用總額的10%去押一支股票而是投資多種股票。在給定的時間可以跟不同公司同時交易,而且大部分財產應該在股票上,而不是現金。現在我們開始投資多支股票 (原文是stops,感覺是typo,譯文按照stocks翻譯),並且在兩條移動平均線交叉的時候退市(不使用止損)。我們需要改變回溯測試的程式碼。我們會用一個pandas的DataFrame來儲存所有股票的買賣,上一層的迴圈也需要記錄更多的資訊。
下麵的函式用於產生買賣訂單,以及另一回溯測試函式。
程式碼過長,微信閱讀體驗不好,可點選「閱讀原文」在網頁版檢視
signals =ma_crossover_orders([(“AAPL”, ohlc_adj(apple)),
(“MSFT”, ohlc_adj(microsoft)),
(“GOOG”, ohlc_adj(google)),
(“FB”, ohlc_adj(facebook)),
(“TWTR”, ohlc_adj(twitter)),
(“NFLX”, ohlc_adj(netflix)),
(“AMZN”, ohlc_adj(amazon)),
(“YHOO”, ohlc_adj(yahoo)),
(“SNY”, ohlc_adj(yahoo)),
(“NTDOY”, ohlc_adj(nintendo)),
(“IBM”, ohlc_adj(ibm)),
(“HPQ”, ohlc_adj(hp))],
fast =20, slow =50)
signals

475 rows × 3 columns
bk =backtest(signals, 1000000)
bk
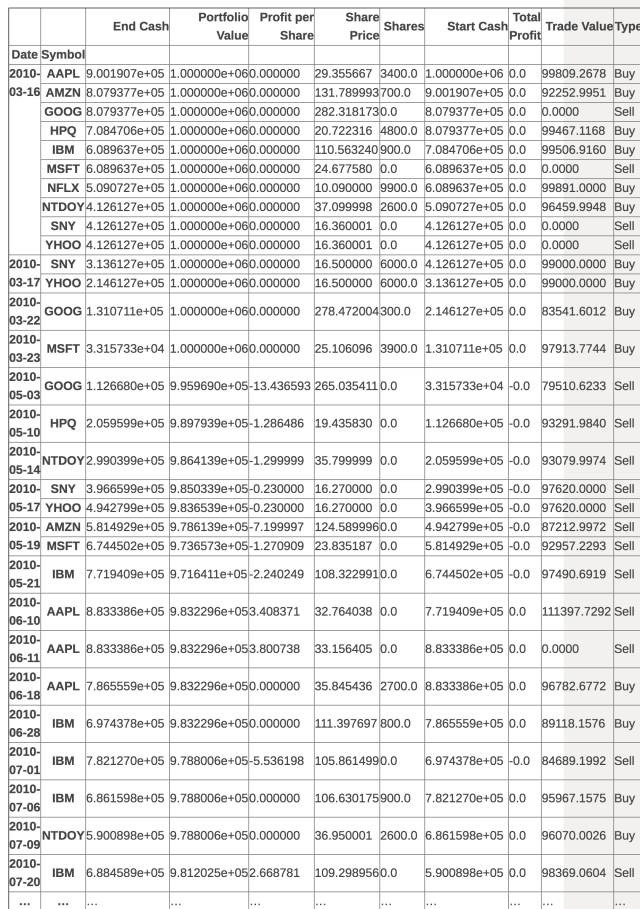

475 rows × 9 columns
bk[“Portfolio Value”].groupby(level =0).apply(lambdax: x[-1]).plot()

更為現實的投資組合可以投資任何12支股票而達到100%的收益。這個看上去不錯,但是我們可以做得更好。
基準分析法
基準分析法可以分析交易策略效率的好壞。所謂基準分析,就是將策略和其他(著名)策略進行比較從而評價該策略的表現好壞。
每次你評價交易系統的時候,都要跟買入持有策略(SPY)進行比較。除了一些信託基金和少數投資經理沒有使用它,該策略在大多時候都是無敵的。有效市場假說強調沒有人能戰勝股票市場,所以每個人都應該購入指數基金,因為它能反應整個市場的構成。SPY是一個交易型開放式指數基金(一種可以像股票一樣交易的信託基金),它的價格有效反映了S&P; 500中的股票價格。買入並持有SPY,說明你可以有效地匹配市場回報率而不是戰勝它。
下麵是SPY的資料,讓我們看看簡單買入持有SPY能得到的回報:
spyder =web.DataReader(“SPY”, “yahoo”, start, end)
spyder.iloc[[0,–1],:]

batches =1000000//np.ceil(100*spyder.ix[0,“Adj Close”]) # Maximum number of batches of stocks invested in
trade_val =batches *batch *spyder.ix[0,“Adj Close”] # How much money is used to buy SPY
final_val =batches *batch *spyder.ix[–1,“Adj Close”] +(1000000–trade_val) # Final value of the portfolio
final_val
2180977.0
# We see that the buy-and-hold strategy beats the strategy we developed earlier. I would also like to see a plot.
ax_bench =(spyder[“Adj Close”] /spyder.ix[0, “Adj Close”]).plot(label =“SPY”)
ax_bench =(bk[“Portfolio Value”].groupby(level =0).apply(lambdax: x[–1]) /1000000).plot(ax =ax_bench, label =“Portfolio”)
ax_bench.legend(ax_bench.get_lines(), [l.get_label() forl inax_bench.get_lines()], loc =‘best’)
ax_bench
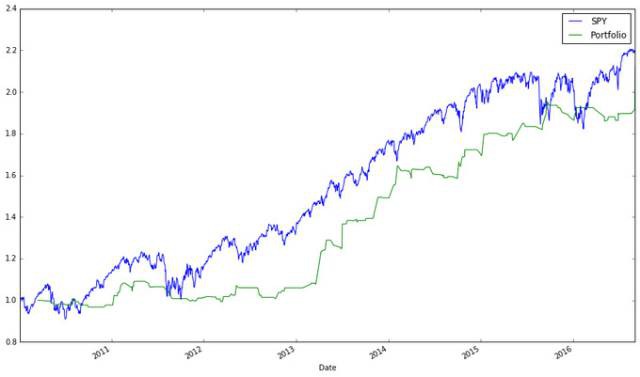
買入持有SPY比我們當前的交易系統好——我們的系統還沒有考慮不菲的交易費用。考慮到機會成本和該策略的消耗,我們不應該用它。
怎樣才能改進我們的系統呢?對於初學者來儘量多樣化是一個選擇。目前我們所有的股票都來自技術公司,這意味著技術型公司的不景氣會反映在我們的投資組合上。我們應該設計一個可以利用空頭頭寸和熊市的系統,這樣不管市場如何變動,我們都可以盈利。我們也可以尋求更好的方法預測股票的最高期望價格。但是不論如何我們都需要做得比SPY更好,不然由於我們的系統會自帶機會成本,是沒用的。
其他的基準策略也是存在的。如果我們的系統比“買入持有SPY”更好,我們可以進一步跟其他的系統比較,例如:

(我最初在這裡接觸到這些策略)基本準則仍然是:不要使用一個複雜的,包含大量交易的系統如果它贏不了一個簡單的交易不頻繁的指數基金模型。(事實上這個標準挺難實現的)
最後要強調的是,假設你的交易系統在回溯測試中打敗了所有的基準系統,也不意味著它能夠準確地預測未來。因為回溯測試容易過擬合,它不能用於預測未來。
結論
雖然講座最後的結論不是那麼樂觀,但記住有效市場理論也有缺陷。我個人的觀點是當交易更多依賴於演演算法的時候,就更難戰勝市場。有一個說法是:信託基金都不太可能戰勝市場,你的系統能戰勝市場僅僅是一個可能性而已。(當然信託基金錶現很差的原因是收費太高,而指數基金不存在這個問題。)
本講座只簡單地說明瞭一種基於移動平均的交易策略。還有許多別的交易策略這裡並沒有提到。而且我們也沒有深入探討空頭股票和貨幣交易。特別是股票期權有很多東西可以講,它也提供了不同的方法來預測股票的走向。你可以在Derivatives Analytics with Python: Data Analysis, Models, Simulation, Calibration and Hedging書中讀到更多的相關內容。(猶他大學的圖書館有這本書)
另一個資源是O’Reilly出的Python for Finance,猶他大學的圖書館裡也有。
記住在股票裡面虧錢是很正常的,同樣股市也能提供其他方法無法提供的高回報,每一個投資策略都應該是經過深思熟慮的。這個講座旨在拋磚引玉,希望同學們自己進一步探討這個話題。
作業
問題1
建立一個基於移動平均的交易系統(不需要止損條件)。選擇15支2010年1月1日之前上市的股票,利用回溯測試檢驗你的 系統,並且SPY基準作比較,你的系統能戰勝市場嗎?
問題2
在現實中每一筆交易都要支付一筆佣金。弄明白如何計算佣金,然後修改你的backtes()函式,使之能夠計算不同的佣金樣式(固定費用,按比例收費等等)。
我們現在的移動平均交匯點分析系統在兩條平均線交叉的時候觸發交易。修改系統令其更準確:


當你完成修改之後,重覆問題1,使用一個真實的佣金策略(從交易所查)來模擬你的系統,同時要求移動平均差異達到一定的移動標準差再激發交易。
問題3
我們的交易系統無法處理空頭股票。空頭買賣的複雜性在於損失是沒有下限的(多頭頭寸的最大損失等於購入股票的總價格)。學習如何處理空頭頭寸,然後修改backtest()使其能夠處理空頭交易。思考要如何實現空頭交易,包括允許多少空頭交易?在進行其他交易的時候如何處理空頭交易?提示:空頭交易的量在函式中可以用一個負數來表示。
完成之後重覆問題1,也可以同時考慮問題2中提到的因素。
相關閱讀:《用Python做股市資料分析(一)》
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

