(點選上方公眾號,可快速關註)
來源:Java驛站,
it.deepinmind.com/java/2015/01/04/performance-general-compression.html
本文將會對常用的幾個壓縮演演算法的效能作一下比較。結果表明,某些演演算法在極端苛刻的CPU限制下仍能正常工作。
文中進行比較的算有:
-
JDK GZIP ——這是一個壓縮比高的慢速演演算法,壓縮後的資料適合長期使用。JDK中的java.util.zip.GZIPInputStream / GZIPOutputStream便是這個演演算法的實現。
-
JDK deflate ——這是JDK中的又一個演演算法(zip檔案用的就是這一演演算法)。它與gzip的不同之處在於,你可以指定演演算法的壓縮級別,這樣你可以在壓縮時間和輸出檔案大小上進行平衡。可選的級別有0(不壓縮),以及1(快速壓縮)到9(慢速壓縮)。它的實現是java.util.zip.DeflaterOutputStream / InflaterInputStream。
-
LZ4壓縮演演算法的Java實現——這是本文介紹的演演算法中壓縮速度最快的一個,與最快速的deflate相比,它的壓縮的結果要略微差一點。如果想搞清楚它的工作原理,我建議你讀一下這篇文章。它是基於友好的Apache 2.0許可證釋出的。
-
Snappy——這是Google開發的一個非常流行的壓縮演演算法,它旨在提供速度與壓縮比都相對較優的壓縮演演算法。我用來測試的是這個實現。它也是遵循Apache 2.0許可證釋出的。
http://en.wikipedia.org/wiki/LZ4_%28compression_algorithm%29
壓縮測試
要找出哪些既適合進行資料壓縮測試又存在於大多數Java開發人員的電腦中(我可不希望你為了執行這個測試還得個幾百兆的檔案)的檔案也著實費了我不少工夫。最後我想到,大多數人應該都會在本地安裝有JDK的檔案。因此我決定將javadoc的目錄整個合併成一個檔案——拼接所有檔案。這個透過tar命令可以很容易完成,但並非所有人都是Linux使用者,因此我寫了個程式來生成這個檔案:
public class InputGenerator {
private static final String JAVADOC_PATH = “your_path_to_JDK/docs”;
public static final File FILE_PATH = new File( “your_output_file_path” );
static
{
try {
if ( !FILE_PATH.exists() )
makeJavadocFile();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void makeJavadocFile() throws IOException {
try( OutputStream os = new BufferedOutputStream( new FileOutputStream( FILE_PATH ), 65536 ) )
{
appendDir(os, new File( JAVADOC_PATH ));
}
System.out.println( “Javadoc file created” );
}
private static void appendDir( final OutputStream os, final File root ) throws IOException {
for ( File f : root.listFiles() )
{
if ( f.isDirectory() )
appendDir( os, f );
else
Files.copy(f.toPath(), os);
}
}
}
在我的機器上整個檔案的大小是354,509,602位元組(338MB)。
測試
一開始我想把整個檔案讀進記憶體裡,然後再進行壓縮。不過結果表明這麼做的話即便是4G的機器上也很容易把堆記憶體空間耗盡。
於是我決定使用作業系統的檔案快取。這裡我們用的測試框架是JMH。這個檔案在預熱階段會被作業系統載入到快取中(在預熱階段會先壓縮兩次)。我會將內容壓縮到ByteArrayOutputStream流中(我知道這並不是最快的方法,但是對於各個測試而言它的效能是比較穩定的,並且不需要花費時間將壓縮後的資料寫入到磁碟裡),因此還需要一些記憶體空間來儲存這個輸出結果。
下麵是測試類的基類。所有的測試不同的地方都只在於壓縮的輸出流的實現不同,因此可以復用這個測試基類,只需從StreamFactory實現中生成一個流就好了:
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Fork(1)
@Warmup(iterations = 2)
@Measurement(iterations = 3)
@BenchmarkMode(Mode.SingleShotTime)
public class TestParent {
protected Path m_inputFile;
@Setup
public void setup()
{
m_inputFile = InputGenerator.FILE_PATH.toPath();
}
interface StreamFactory
{
public OutputStream getStream( final OutputStream underlyingStream ) throws IOException;
}
public int baseBenchmark( final StreamFactory factory ) throws IOException
{
try ( ByteArrayOutputStream bos = new ByteArrayOutputStream((int) m_inputFile.toFile().length());
OutputStream os = factory.getStream( bos ) )
{
Files.copy(m_inputFile, os);
os.flush();
return bos.size();
}
}
}
這些測試用例都非常相似(在文末有它們的原始碼),這裡只列出了其中的一個例子——JDK deflate的測試類;
public class JdkDeflateTest extends TestParent {
@Param({“1”, “2”, “3”, “4”, “5”, “6”, “7”, “8”, “9”})
public int m_lvl;
@Benchmark
public int deflate() throws IOException
{
return baseBenchmark(new StreamFactory() {
@Override
public OutputStream getStream(OutputStream underlyingStream) throws IOException {
final Deflater deflater = new Deflater( m_lvl, true );
return new DeflaterOutputStream( underlyingStream, deflater, 512 );
}
});
}
}
測試結果
輸出檔案的大小
首先我們來看下輸出檔案的大小:
||實現||檔案大小(位元組)|| ||GZIP||64,200,201|| ||Snappy (normal)||138,250,196|| ||Snappy (framed)|| 101,470,113|| ||LZ4 (fast)|| 98,316,501|| ||LZ4 (high) ||82,076,909|| ||Deflate (lvl=1) ||78,369,711|| ||Deflate (lvl=2) ||75,261,711|| ||Deflate (lvl=3) ||73,240,781|| ||Deflate (lvl=4) ||68,090,059|| ||Deflate (lvl=5) ||65,699,810|| ||Deflate (lvl=6) ||64,200,191|| ||Deflate (lvl=7) ||64,013,638|| ||Deflate (lvl=8) ||63,845,758|| ||Deflate (lvl=9) ||63,839,200||
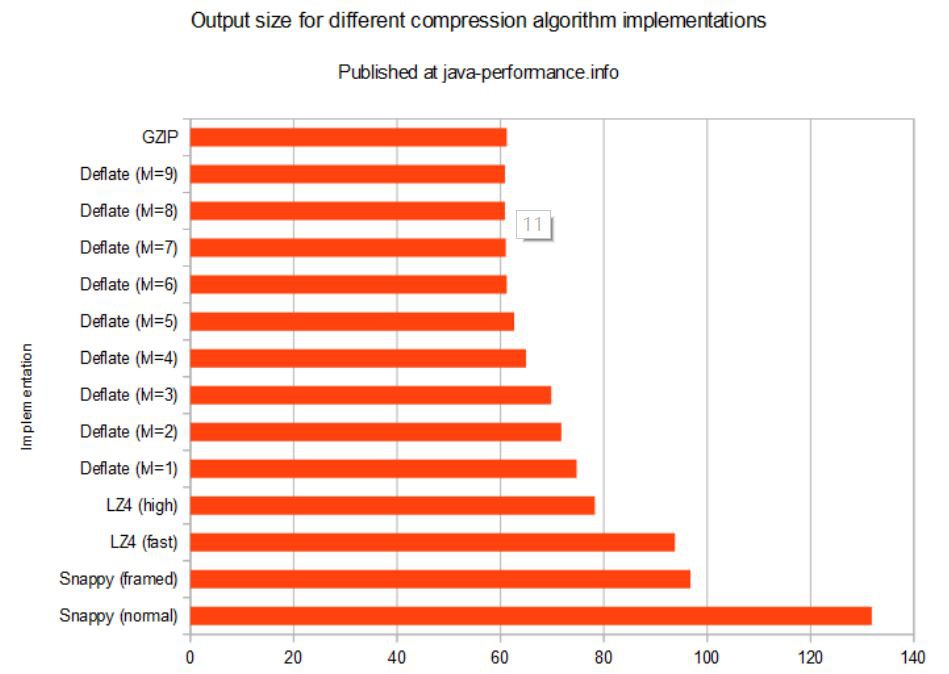
可以看出檔案的大小相差懸殊(從60Mb到131Mb)。我們再來看下不同的壓縮方法需要的時間是多少。
壓縮時間
||實現||壓縮時間(ms)|| ||Snappy.framedOutput ||2264.700|| ||Snappy.normalOutput ||2201.120|| ||Lz4.testFastNative ||1056.326|| ||Lz4.testFastUnsafe ||1346.835|| ||Lz4.testFastSafe ||1917.929|| ||Lz4.testHighNative ||7489.958|| ||Lz4.testHighUnsafe ||10306.973|| ||Lz4.testHighSafe ||14413.622|| ||deflate (lvl=1) ||4522.644|| ||deflate (lvl=2) ||4726.477|| ||deflate (lvl=3) ||5081.934|| ||deflate (lvl=4) ||6739.450|| ||deflate (lvl=5) ||7896.572|| ||deflate (lvl=6) ||9783.701|| ||deflate (lvl=7) ||10731.761|| ||deflate (lvl=8) ||14760.361|| ||deflate (lvl=9) ||14878.364|| ||GZIP ||10351.887||

我們再將壓縮時間和檔案大小合併到一個表中來統計下演演算法的吞吐量,看看能得出什麼結論。
吞吐量及效率
||實現||時間(ms)||未壓縮檔案大小||吞吐量(Mb/秒)||壓縮後檔案大小(Mb)|| ||Snappy.normalOutput ||2201.12 ||338 ||153.5581885586 ||131.8454742432|| ||Snappy.framedOutput ||2264.7 ||338 ||149.2471409017 ||96.7693328857|| ||Lz4.testFastNative ||1056.326 ||338 ||319.9769768045 ||93.7557220459|| ||Lz4.testFastSafe ||1917.929 ||338 ||176.2317583185 ||93.7557220459|| ||Lz4.testFastUnsafe ||1346.835 ||338 ||250.9587291688 ||93.7557220459|| ||Lz4.testHighNative ||7489.958 ||338 ||45.1270888301 ||78.2680511475|| ||Lz4.testHighSafe ||14413.622 ||338 ||23.4500391366 ||78.2680511475|| ||Lz4.testHighUnsafe ||10306.973 ||338 ||32.7933332124 ||78.2680511475|| ||deflate (lvl=1) ||4522.644 ||338 ||74.7350443679 ||74.7394561768|| ||deflate (lvl=2) ||4726.477 ||338 ||71.5120374012 ||71.7735290527|| ||deflate (lvl=3) ||5081.934 ||338 ||66.5101120951 ||69.8471069336|| ||deflate (lvl=4) ||6739.45 ||338 ||50.1524605124 ||64.9452209473|| ||deflate (lvl=5) ||7896.572 ||338 ||42.8033835442 ||62.6564025879|| ||deflate (lvl=6) ||9783.701 ||338 ||34.5472536415 ||61.2258911133|| ||deflate (lvl=7) ||10731.761 ||338 ||31.4952969974 ||61.0446929932|| ||deflate (lvl=8) ||14760.361 ||338 ||22.8991689295 ||60.8825683594|| ||deflate (lvl=9) ||14878.364 ||338 ||22.7175514727 ||60.8730316162|| ||GZIP ||10351.887 ||338 ||32.651051929 ||61.2258911133||

可以看到,其中大多數實現的效率是非常低的:在Xeon E5-2650處理器上,高階別的deflate大約是23Mb/秒,即使是GZIP也就只有33Mb/秒,這大概很難令人滿意。同時,最快的defalte演演算法大概能到75Mb/秒,Snappy是150Mb/秒,而LZ4(快速,JNI實現)能達到難以置信的320Mb/秒!
從表中可以清晰地看出目前有兩種實現比較處於劣勢:Snappy要慢於LZ4(快速壓縮),並且壓縮後的檔案要更大。相反,LZ4(高壓縮比)要慢於級別1到4的deflate,而輸出檔案的大小即便和級別1的deflate相比也要大上不少。
因此如果需要進行“實時壓縮”的話我肯定會在LZ4(快速)的JNI實現或者是級別1的deflate中進行選擇。當然如果你的公司不允許使用第三方庫的話你也只能使用deflate了。你還要綜合考慮有多少空閑的CPU資源以及壓縮後的資料要儲存到哪裡。比方說,如果你要將壓縮後的資料儲存到HDD的話,那麼上述100Mb/秒的效能對你而言是毫無幫助的(假設你的檔案足夠大的話)——HDD的速度會成為瓶頸。同樣的檔案如果輸出到SSD硬碟的話——即便是LZ4在它面前也顯得太慢了。如果你是要先壓縮資料再傳送到網路上的話,最好選擇LZ4,因為deflate75Mb/秒的壓縮效能跟網路125Mb/秒的吞吐量相比真是小巫見大巫了(當然,我知道網路流量還有包頭,不過即使算上了它這個差距也是相當可觀的)。
總結
如果你認為資料壓縮非常慢的話,可以考慮下LZ4(快速)實現,它進行文字壓縮能達到大約320Mb/秒的速度——這樣的壓縮速度對大多數應用而言應該都感知不到。
如果你受限於無法使用第三方庫或者只希望有一個稍微好一點的壓縮方案的話,可以考慮下使用JDK deflate(lvl=1)進行編解碼——同樣的檔案它的壓縮速度能達到75Mb/秒。
原始碼
Java壓縮測試原始碼
http://d1k2jhzcfaebet.cloudfront.net/wp-content/uploads/2014/12/compress_src.zip
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

