
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @britin。本文給出了一種 end-to-end 的系統來自動將 NL 問題轉換成 SPARQL 查詢語言。
作者綜合了物體識別以及距離監督和 learning-to-rank 技術,使得 QA 系統的精度提高了不少,整個過程介紹比較詳細,模型可靠接地氣。
如果你對本文工作感興趣,點選底部的閱讀原文即可檢視原論文。
關於作者:Britin,中科院物理學碩士,研究方向為自然語言處理和計算機視覺。
■ 論文 | More Accurate Question Answering on Freebase
■ 連結 | https://www.paperweekly.site/papers/1356
■ 原始碼 | https://github.com/ad-freiburg/aqqu
論文動機
在知識問答中,要把一個自然語言的問句對映到知識庫 KB 中是很難的,目前的問答系統通常是將 NLP 問句轉換成一個 SPARQL 查詢陳述句去檢索 KB。如何完成這一轉換過程面臨著很多問題,比如怎麼在 KB 中找到和問句中匹配的物體與關係。
首先問題中的物體名可能不完全依照資料庫中的名稱,同一個物體有多種叫法。其次資料庫中多個物體對應的名稱可能是一樣的。比如 Freebase 裡叫 apple 的就有 218 種物體。精確匹配的話很難找到答案,模糊匹配又會從大型資料庫中搜索到冗餘的資料。
本文在學習演演算法基礎上採用了 learning-to-rank 來重點關註被大部分工作忽略掉的物體識別的問題。
模型介紹
本文要完成的任務是根據 KB 知識來回答自然語言問題,給出了一個叫 Aqqu 的系統,首先為問題生成一些備選 query,然後使用學習到的模型來對這些備選 query 進行排名,傳回排名最高的 query,整個流程如下:
比如要回答這個問題:What character does Ellen play in finding Nemo?
1. Entity Identification 物體識別
首先在 KB 中找到和問句中名詞匹配置信度較高的物體集合,因為問句中的 Ellen,finding Nemo 表達並不明確,會匹配到 KB 中的多個物體。
先用 Stanford Tagger 進行詞性標註。然後根據詞性挑出可能是物體的詞與 KB 進行匹配,利用了 CrossWikis 資料集匹配到名稱相似或別名相似的物體,併進行相似度評分和詞語流行度評分。
2. Template Matching 模板匹配
這一步對上一步得到的候選物體在資料庫中進行查詢,然後利用三種模板生成多個候選 query。三種模板和示例如圖所示:

3. Relation Matching 關係匹配
這一步將候選 query 中的 relation 與問句中剩下的不是物體的詞進行匹配,分別從 Literal,Derivation,Synonym 和 Context 四個角度進行匹配。
Literal 是字面匹配,Derivation 利用 WordNet 進行衍生詞匹配,Synonym 利用 word2vec,匹配同義詞。Context 則是從 wiki 中找出和 relation 匹配的句子,然後利用這些句子計算原問句中的詞語和這些 relation 匹配出現的機率,採用 tf-idf 演演算法。
4. Answer Type Matching 答案型別匹配
這裡採用了較為簡潔的方法,將 relation 連線的物件型別和問句中的疑問詞匹配,比如 when 應該和型別為日期的物件匹配。
5. Candidate Features 人工設計的特徵
-
物體匹配的特徵:(1)備選 query 中物體的個數(2)字面大部分匹配的物體個數(3)物體中匹配的token的數量(4-5)物體匹配機率的平均值和總和(6-7)物體匹配流行度的平均值和總和
-
關係匹配的特徵:(8)匹配模板中的關係個數(9)字面匹配的關係個數(10-13)分別在 literal,derivation,synonym 和 context 四個角度匹配的 token 個數(14)同義詞匹配總分(15)關係背景關係匹配總分(16)答案的 relation 在 KB 中出現的次數(17)n-gram 特徵匹配度
-
綜合特徵:(18)特徵 3 和 10 的總和(19)問句中匹配到物體或關係的詞所佔比重(20-22)二進位制結果大小為 0 或 1-20 或大於 20(23)答案型別匹配的二元結果
6. Ranking
本文采用了基於 learning-to-ranking 的方法根據上述特徵對備選結果進行 ranking。作者使用了 pairwise ranking,針對兩個備選的 query,預測哪一個評分更高,然後取勝出最多的那個。
分類器採用了 logistic regression 和 random forest。
實驗結果
本文使用 Freebase 作為 KB,但對於 WikiData 同樣有效。
資料集使用了 Free917 和 WebQuestions。前者手動編寫了改寫 81 個 domain 的自然語言問句,語法準確,每個問句都對應一條 SPARQL 陳述句,用它可以在 KB 中查到標準答案。訓練集和測試集比例為 7:3。
WebQuestions 包含 5810 條從 Google Suggest API 上爬下來的問句,和 Free917 不同的是,它比較口語化,語法不一定準確,並且問題改寫的領域多為 Google 上被問到最多的領域。答案是用眾包生成的,噪聲較大,訓練集和測試集比例為 7:3。
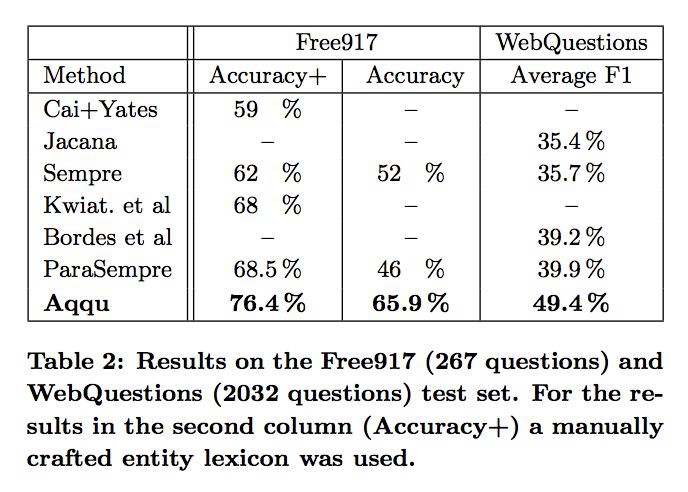
和 Sempre,GraphParser 等結果較好的模型比較了 accuracy 和 F1 score,結果如下:
文章還分析了每個特徵對系統可靠性的影響:

對於 80% 的查詢,正確答案都能出現在 Top-5 裡。
文章評價
本文給出了一種 end-to-end 的系統來自動將 NL 問題轉換成 SPARQL 查詢語言。系統綜合了物體識別以及距離監督和 learning-to-rank 技術。設計的特徵非常具體豐富,比以往的模型準確度高了不少。並且據說程式執行效率也很好,一秒就能回答出一個問題。
系統的準確雖然不是特別高,但在 Top-5 內的準確度很高,如果加上互動式問答的形式,結果可能就會改善。本文沒有採用深度學習的方法,採用的是統計學習的方法,並且手動設計了特徵,人工代價比較高,對資料集的要求和質量較高。
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

 #榜 單 公 布 #
#榜 單 公 布 #
2017年度最值得讀的AI論文 | NLP篇 · 評選結果公佈
2017年度最值得讀的AI論文 | CV篇 · 評選結果公佈
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群一起刷論文