(點選上方藍字,快速關註我們)
伯樂線上/劉唱 編譯,Erik Bernhardsson
我看了一篇部落格,標題是《為什麼我們要從 X 語言轉到 Y 語言》,具體是哪種程式語言,我忘了。於是我開始想,是不是可以把這些文章歸納起來,生成一個關於從 X 語言轉到 Y 語言的 N*N 的聯串列(contingency table)?
所以我寫了個小指令碼,可以用指令碼在 Google 上查詢,再加上一小段程式碼就能得到搜尋結果的數目。我嘗試了用幾個不同的關鍵詞來搜尋,像“move from
本文圖表尺寸很大,「程式員的那些事」先來解釋如何讀圖:
左側縱向語言是「叛逃的源語言」;
上方橫向的語言是「叛逃的標的語言」;
例如:從 C 語言轉到 C# 的數量為 3619,從 C# 轉到 C 的有 37229;
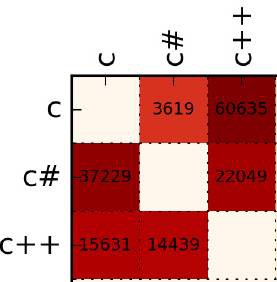

(點選上圖,然後雙指縮放,可以看到詳細數字。以下類同)
有意思的部分來了。實際上我們可以把搜尋結果數看作是程式語言之間轉換的機率,從而得出一些關於未來程式語言的流行趨勢的結論。一個關鍵點是,這個(程式語言轉換過程)的平穩分佈並不取決於它們的初始分佈。事實證明,這隻是矩陣的第一特徵向量(first eigenvector)而已。所以沒必要去假設現在哪種程式語言很流行,我們推測出的未來的平穩分佈狀態和初始狀態是獨立的。
我們需要把上述的聯串列轉化成轉移矩陣(stochastic matrix)的形式,用來描述從狀態 ii 到狀態 jj 的機率。非常簡單——想要把聯列矩陣解釋為轉移機率的話,可以將聯列矩陣的每一行正則化。這樣就能得到從 X 語言到 Y 語言的粗略近似機率。
找出第一特徵向量並不重要,我們只要把一個向量多次乘上這個轉移矩陣,最終會向第一特徵向量收斂。順便說下,可以看看下麵的註意事項,有關於我如何操作的更多討論。
Go 是程式語言的未來(麼?)
閑話少說,下表是平穩分佈下排名前幾的語言:
| 16.41% | Go |
| 14.26% | C |
| 13.21% | Java |
| 11.51% | C++ |
| 9.45% | Python |
根據未來流行度,我把轉移矩陣按照程式語言做了排序(根據第一特徵向量所做的預測)
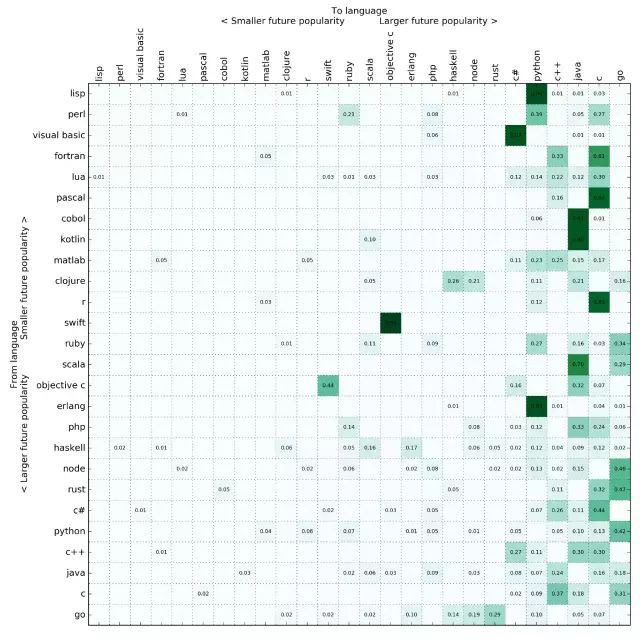
(點選檢視大圖)
令人驚訝的是(至少對我來說),Go 成為最大贏家。有超多的搜尋結果顯示大家由其他語言轉向 Go。我都不能確定我對此是什麼感受了(我對 Go 的感情很複雜)。但是我的絕對分析指出了一個必然結論,那就是 Go 值得關註。
C 語言到今年就有 45 歲了,仍然表現良好。我手動做了一些搜尋,有很多都是人們真的在寫他們透過從另一種程式語言遷移到 C,對特定的緊密迴圈(tight loops)做了最佳化。這個結果是錯的嗎?我不這麼認為。C 語言是計算機工作的通用語言(lingua franca),如果人們還會積極地將其他語言的片段轉換為 C 語言,那麼這個結論也就可想而知了。說真的,我認為 C 語言會在它 100 歲生日,也就是 2072 年以前,變得更強大。有我在 LinkedIn 上對 C 的支援,我希望招聘人員能在 21 世紀 50 年代的時候給我一些關於 C 語言的工作機會(我收回上面那句話——希望 C 會比 LinkedIn 活得久)。
除了上面提到的以外,這些分析也很符合我的預期。Java 還在,Perl 滅亡了,Rust 做的相當不錯。
順便一提,這個分析讓我想起了下麵這條推
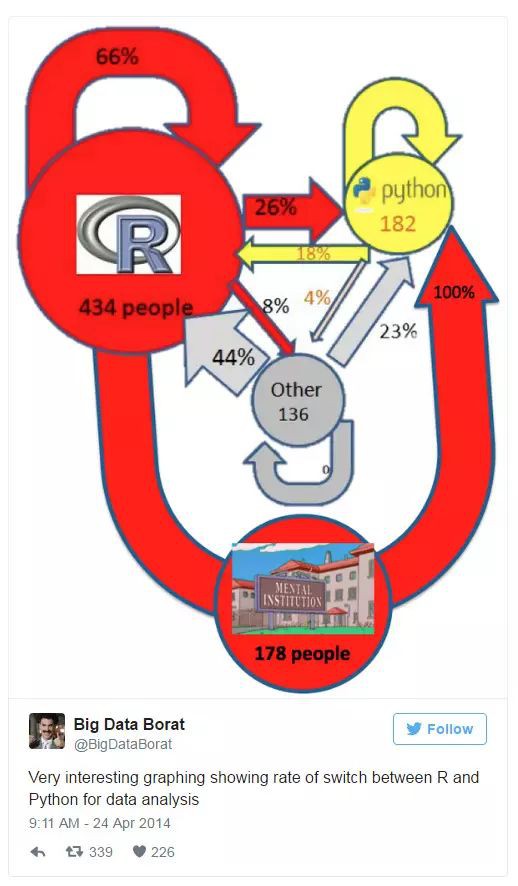
這圖非常有意思,展示了在資料分析中 R 和 Python 之間的轉化率。
JavaScript 框架
我對前端框架也做了同樣的分析:

我預期 React 會脫穎而出成為第一,但有趣的是,Vue 也表現得非常好。我很驚訝於 Angular 的表現——傳聞大批的人似乎在逃離 Angular。
資料庫
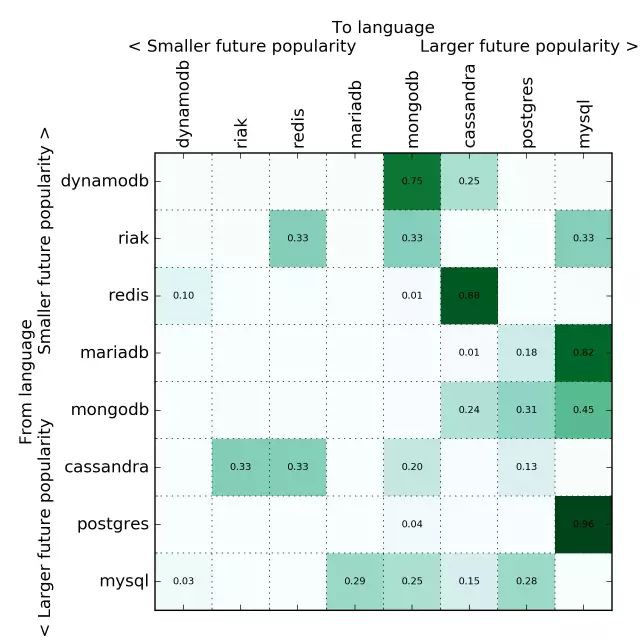
我開始留意共享單車 App,深度學習框架還有其他一些東西,但是資料太稀疏了,也不太可靠。有結果的話,會及時向大家公佈的!
註意事項
-
關於我這篇文章,看看網友們在 Hacker News 和 /r/programming 上的討論;
-
《為什麼我從程式語言 1 轉向程式語言 2》這篇博文也給我了啟發;
-
下麵是如何抓取 Google 並獲取搜尋結果數的程式碼:
def get_n_results_dumb(q):
r = requests.get(‘http://www.google.com/search’,
params={‘q’: q,
“tbs”: “li:1”})
r.raise_for_status()
soup = bs4.BeautifulSoup(r.text)
s = soup.find(‘div’, {‘id’: ‘resultStats’}).text
if not s:
return 0
m = re.search(r‘([0-9,]+)’, s)
return int(m.groups()[0].replace(‘,’, ”))
-
很不幸,Google 對查詢的 IP 有速率限制,但是我最終用 Proxymesh 抓取到了這 N*N 組合所需的所有資料。
-
註意:我在搜尋的時候將確切的查詢陳述句放在雙引號中了,比如:“switch from go to c++”
-
細心的讀者可能會問為什麼 JavaScript 沒有包含在分析中。原因是:(a)如果你在前端開發中使用它,那麼你會一直堅持用下去,並沒有轉移的這個過程,除非你瘋了,要做轉譯(transpiling,從一種程式語言到另一種程式語言的編譯),這種情況太不常見了;(b)大家會把後端的 JavaScript 認作是 “Node”。
-
對角線的元素又是怎麼回事呢?當然了,有些人會只堅持使用一種程式語言,這也是有很大的可能性的。但是我選擇忽略它,因為:(a)事實證明,像“stay with Swift”(堅守 Swift)的搜尋結果 99% 都是和女明星 Taylor Swift 相關的;(b)平穩分佈與新增一個常數對角(單位)矩陣是無關的(即新增一個常數對角矩陣結果不變);(c)這是我的部落格,所以我想怎樣就怎樣 [壞笑]
-
對於上一條的(b),e(αS+(1−α)I) = e(S) 這個結論是對的,其中,e(…) 是第一特徵向量,I 是單位矩陣。這個結論可能不完全符合現實,對於不同的程式語言,你堅持用它的機率可能是不相等的。
-
重覆相乘以得到第一特徵向量的方法叫做冪迭代(Power iteration)。
-
這個用特徵向量表示的模型能不能對實際情況做超準確地描述呢?大概不能。我的腦海中浮現出了一句來自 George Box 的名言:“所有模型都有錯,不過有些還是有用的”(All models are wrong, some are useful,意為沒有模型能夠完全準確地描述實際情況,但是可以用一些模型來解決問題。George Box 是英國著名的統計學家)。
-
我也知道還有一些其他的約束條件需要一一考慮,但是實際情況基本都是這樣的。
-
程式碼可以在 Github 上找到:https://github.com/erikbern/eigenstuff
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功
