作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
事實上,在論文《Dynamic Routing Between Capsules》釋出不久後,一篇新的 Capsule 論文《Matrix Capsules with EM Routing》就已經匿名公開了(在 ICLR2018 的匿名評審中),而如今作者已經公開,他們是 Geoffrey Hinton,Sara Sabour 和 Nicholas Frosst。
不出大家意料,作者果然有 Hinton。大家都知道,像 Hinton 這些“鼻祖級”的人物,一般發表出來的結果都是比較“重磅”的。那麼,這篇新論文有什麼特色呢?
在筆者的思考過程中,文章《Understanding Matrix capsules with EM Routing 》[1] 給了我頗多啟示,以及知乎上各位大神的相關討論也加速了我的閱讀過程,在此表示感謝。
快速預覽
讓我們先來回憶一下上一篇介紹再來一頓賀歲宴 | 從K-Means到Capsule中的那個圖:
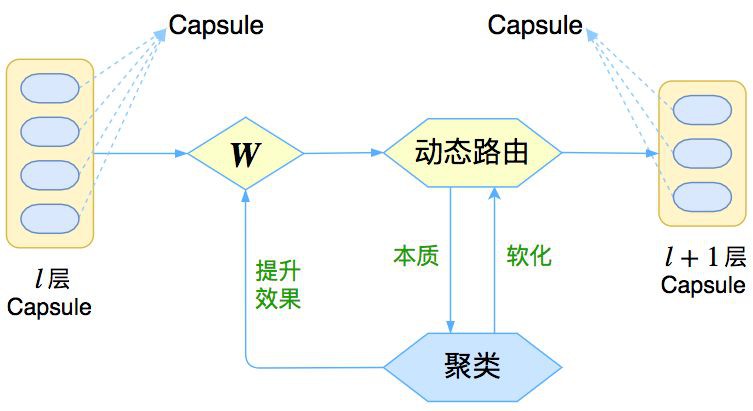
△ 圖1:Capsule框架的簡明示意圖
上圖表明,Capsule 事實上描述了一個建模的框架,這個框架中的東西很多都是可以自定義的,最明顯的是聚類演演算法,可以說“有多少種聚類演演算法就有多少種動態路由”。
那麼這次 Hinton 修改了什麼呢?總的來說,這篇新論文有以下幾點新東西:
-
原來用向量來表示一個 Capsule,現在用矩陣來表示
-
聚類演演算法換成了 GMM(高斯混合模型)
-
在實驗部分,實現了 Capsule 版的摺積
一波疑問
事實上,看到筆者提出的這三點新東西,讀者應該就會有很多想法和疑問了,比如:
向量 vs 矩陣
矩陣和向量有什麼區別呢?矩陣不也可以展平為向量嗎?
其實是有點區別的。比如一個 4×4 的矩陣,跟一個 16 維的向量,有什麼差別呢?答案是矩陣的不同位置的元素重要性不一樣,而向量的每個元素的重要性都是一樣的。
熟悉線性代數的讀者應該也可以感覺到,一個矩陣的對角線元素的地位“看起來”是比其他元素要重要一些的。
從計算的角度看,也能發現區別:要將一個 16 維的向量變換為另外一個 16 維的向量,我們需要一個 16×16 的變換矩陣;但如果將一個 4×4 的矩陣變換為另外一個 4×4 的矩陣,那麼只需要一個 4×4 的變換矩陣,引數量減少了。
從這個角度看,也許將 Capsule 從向量變為矩陣的根本目的是降低計算量。
立方陣
以後的 Capsule 可能是“立方陣”甚至更高階張量嗎?
不大可能。因為更高階張量的乘法本質上也是二階矩陣的乘法。
GMM vs K-Means
GMM 聚類與你之前說的 K-Means 聚類差別大嗎?
這個得從兩個角度看。一方面,GMM 可以看成是 K-Means 的升級版,而且它本身就是可導的,不需要之前的“軟化”技巧,如果在 K-Means 中使用歐氏距離的話,那麼 K-Means 就是 GMM 的一個極限版本。
但另一方面,K-Means 允許我們更靈活地使用其他相似的度量,而 GMM 中相當於只能用(加權的)歐氏距離,也就是把度量“寫死”了,也是個缺點。總的來說,兩者半斤八兩吧。
Capsule 版的摺積
Capsule 版的摺積是怎麼回事?
我們所說的動態路由,事實上就只相當於深度學習中的全連線層,而深度學習中的摺積層則是區域性的全連線層。那麼很顯然,只需要弄個“區域性動態路由”,那麼就得到了 Capsule 版的摺積了。
這個東西事實上在 Hinton 上一篇論文就應該出現,因為它跟具體的路由演演算法並沒有關係,但不知為何,Hinton 在這篇新論文才實現了它。
GMM 模型簡介
既然這篇新論文用到了 GMM 來聚類,那麼只要花點功夫來學習一下 GMM 了。理解 GMM 演演算法是一件非常有意思的事情,哪怕不是因為 Capsule——因為 GMM 模型能夠大大加深我們對機率模型和機器學習理論(尤其是無監督學習理論)的理解。
當然,只想理解 Capsule 核心思想的讀者,可以有選擇地跳過比較理論化的部分。
本質
事實上,在我們腦海裡最好不要將 GMM 視為一個聚類演演算法,而將它看作一個真正的無監督學習演演算法,它試圖學習資料的分佈。資料本身是個體,而分佈則是一個整體,從研究資料本身到研究資料分佈,是質的改變。
GMM,全稱 Gaussian Mixed Model,即高斯混合模型;當然學界還有另一個 GMM——Generalized Method of Moments ,是用來估計引數的廣義矩估計方法,但這裡討論的是前者。
具體來說,對於已有的向量 x1,…,xn,GMM希望找到它們所滿足的分佈 p(x)。當然,不能漫無目的地找,得整一個比較簡單的形式出來。GMM 設想這批資料能分為幾部分(類別),每部分單獨研究,也就是:

其中 j 代表了類別,取值為 1,2,…,k,由於 p(j) 跟 x 沒關係,因此可以認為它是個常數分佈,記 p(j)=πj。然後 p(x|j) 就是這個類內的機率分佈,GMM 的特性就是用機率分佈來描述一個類。
那麼它取什麼好呢?我們取最簡單的正態分佈,註意這裡 x 是個向量,因此我們要考慮多元的正態分佈,一般形式為:

其中 d 是向量 x 的分量個數。現在我們得到模型的基本形式:

求解
現在模型有了,但是未知的引數有 πj,μj,Σj,怎麼確定它們呢?
理想的方法是最大似然估計,然而它並沒有解析解,因而需要轉化為一個 EM 過程,但即使這樣,求解過程也比較難理解(涉及到行列式的求導)。
這裡給出一個比較簡單明瞭的推導,它基於這樣的一個事實——對於正態分佈來說,最大似然估計跟前兩階矩的矩估計結果是一樣的。
說白了,μj,Σj 不就是正態分佈的均值(向量)和(協)方差(矩陣)嘛,我直接根據樣本算出對應的均值和方差不就行了嗎?
沒那麼簡單,因為我們所假設的是一個正態分佈的混合模型,如果直接算它們,得到的也只是混合的均值和方差,沒法得到每一類的正態分佈 p(x|j) 的均值和方差。
不過我們可以用貝葉斯公式轉化一下,首先我們有:

比如對於均值向量,我們有:

這裡 E[] 的意思是對所有樣本求均值,那麼我們就可以得到:

其中 p(j|x) 的運算式在 (4) 已經給出。類似地,對於協方差矩陣,我們有:
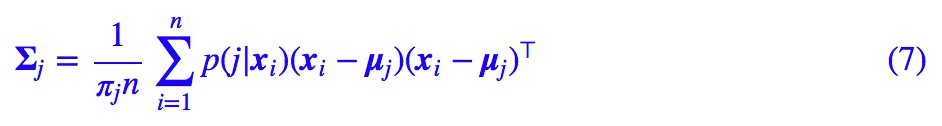
然後:

所以:

理論上,我們需要求解 (6),(7),(9) 構成的一個巨大的方程組,但這樣是難以操作的,因此我們可以迭代求解,得到迭代演演算法:
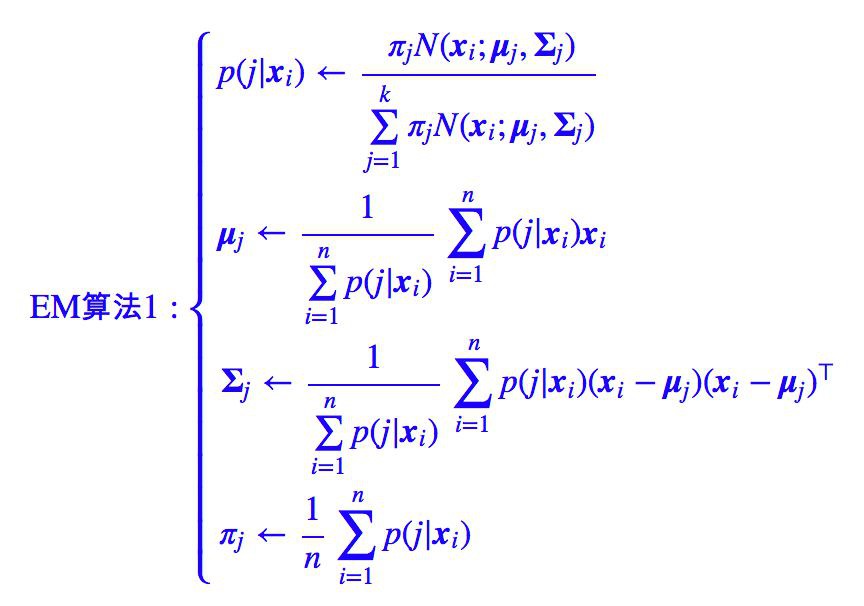
其中為了突出加權平均的特點,上述迭代過程先將 (9) 式作了恆等變換然後代入 (6),(7) 式。在上述迭代過程中,第一式稱為 E 步,後三式稱為 M 步,整個演演算法就叫做 EM 演演算法。
下麵放一張網上搜索而來的動圖來展示 GMM 的迭代過程,可以看到 GMM 的好處是能識別出一般的二次曲面形狀的類簇,而 K-Means 只能識別出球狀的。

△ 圖2:GMM 迭代過程展示
約簡
在 Capsule 中實際上使用了一種更加簡單的 GMM 形式,在前面的討論中,我們使用了一般的正態分佈,也就是 (2) 式,但這樣要算逆矩陣和矩陣的行列式,計算量頗大。
一個較為簡單的模型是假設協方差矩陣是一個對角陣 Σj=diagσj,σj 是類別 j 的方差向量,其中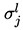 表示該向量的第 l 個分量。這樣相當於將 x 的各個分量解耦了,認為各個分量是獨立的,(2) 式就變為:
表示該向量的第 l 個分量。這樣相當於將 x 的各個分量解耦了,認為各個分量是獨立的,(2) 式就變為:
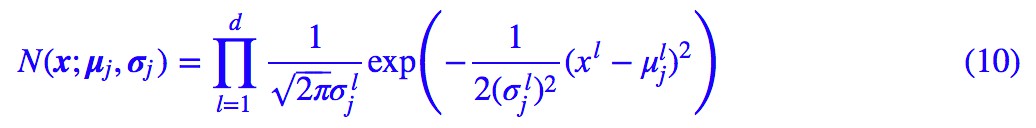
而迭代過程也有所簡化:
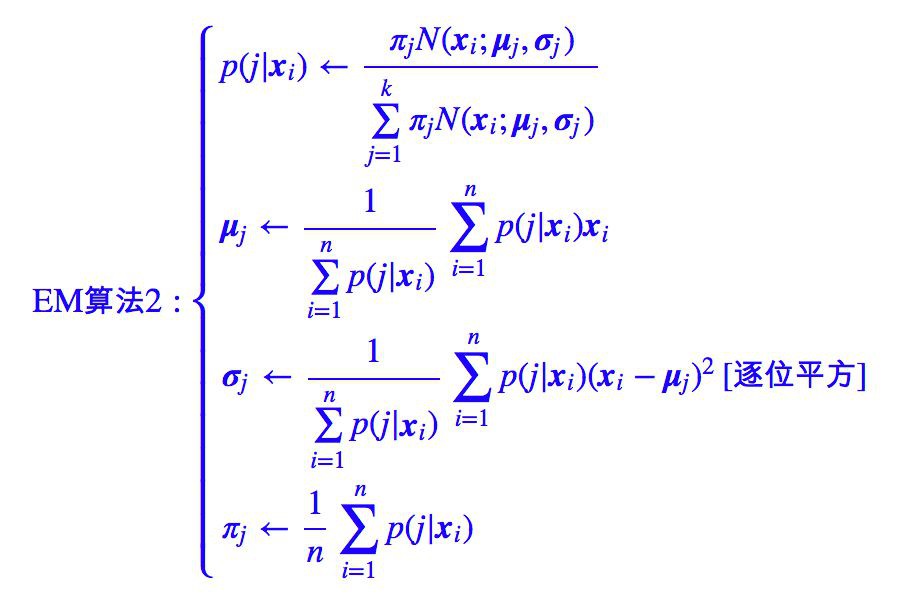
更簡單些
如果所有的都取同一個常數 σ 呢?這就得到:

這樣整個分佈就更為簡單了,有意思的是,在指數的括號內出現了歐氏距離。
更極端地,我們讓 σ→0 呢?這時指數內的括號為無窮大,對於每個 xi,只有 的那個 N(xi;μj,σ) 佔主導作用,這時候根據 (4) 式,p(j|xi) 非零即 1(即使得最小的那個 j 的 p(j|xi) 為 1,其餘為 0)。
的那個 N(xi;μj,σ) 佔主導作用,這時候根據 (4) 式,p(j|xi) 非零即 1(即使得最小的那個 j 的 p(j|xi) 為 1,其餘為 0)。
這表明任意一個點只屬於距離它最近的那個聚類中心,這就跟使用歐氏距離的 K-Means 一致了,所以說,基於歐氏距離的 K-Means 可以看作是 GMM 的一個極限。
新版路由
言歸正傳,還是說回 Capsule。我們說《Matrix Capsules with EM Routing》中用 GMM 演演算法完成了聚類過程,現在就來詳細看看是怎麼做的。
矩陣->向量
不得不說,新論文裡邊的符號用得一塌糊塗,也許能夠在一堆混亂的符號中看到真理才是真正的大牛吧。這裡結合網上的一些科普資料以及作者自己的閱讀,給出一些理解。
首先,我們用一個矩陣 Pi 來表示第 l 層的 Capsule,這一層共有 n 個 Capsule,也就是 i=1,…,n;用矩陣 Mj 來表示第 l+1 層的 Capsule,這一層共有 k 個 Capsule,也就是聚為 k 類,j=1,…,k。
論文中 Capsule 的矩陣是 4×4 的,稱之為 Pose 矩陣。然後呢,就可以開始 GMM 的過程了,在做 GMM 的時候,又把矩陣當成向量了,所以在 EM 路由那裡,Pi 就是向量,即 d=16 。整個過程用的是簡化版的 GMM,也就是把協方差矩陣約定為一個對角陣。
所以根據前面的討論,可以得到新的動態路由演演算法:

這裡記了 pij=N(xi;μj,σj),Rij=p(j|xi),符號儘量跟原論文一致,方便大家對比原論文。這裡的動態路由的思想跟《Dynamic Routing Between Capsules》的是一致的,都是將 l+1 層的 Capsule 作為 l 層 Capsule 的聚類中心,只是聚類的方法不一樣而已。
啟用值
在《Dynamic Routing Between Capsules》一文中,是透過向量的模長來表示該特徵的顯著程度,那麼在這裡還可以這樣做嗎?
答案是否定的。因為我們使用了 GMM 進行聚類,GMM 是基於加權的歐氏距離(本質上還是歐氏距離),用歐氏距離進行聚類的一個特點就是聚類中心向量是類內向量的(加權)平均(從上面MjMj的迭代公式就可以看出)。
既然是平均,就不能體現“小弟越多,勢力越大”的特點,這我們在再來一頓賀歲宴 | 從K-Means到Capsule中就已經討論過了。
既然 Capsule 的模長已經沒法衡量特徵的顯著性了,那麼就只好多加一個標量 a 來作為該 Capsule 的顯著性。所以,這篇論文中的 Capsule,實際上是“一個矩陣 + 一個標量”,這個標量被論文稱為“啟用值”,如圖:

△ 圖3:這個版本的Capsule是“矩陣+標量”
作為 Capsule 的顯著程度,aj 最直接的選擇應該就是 πj,因為 l+1 層的 Capsule 就是聚類中心而 πj 就代表著這個類的機率。
然而,我們卻不能選擇 πj,原因有兩個:
1. πj 是歸一化的,而我們希望得到的只不過是特徵本身的顯著程度,而不是跟其他特徵相比後的相對顯著程度(更通俗點,我們希望做多個二分類,而不是一個多分類,所以不需要整體歸一化)。
2. πj 確實能反映該類內“小弟”的多少,但人多不一定力量大,還要團結才行。那麼這個啟用值應該怎麼取呢?論文給出的公式是:

我相信很多讀者看到這個公式和論文中的“推導”後,還是不知所云。事實上,這個公式有一個非常漂亮的來源——資訊熵。
現在我們用 GMM 來聚類,結果就是得到一個機率分佈 p(X|j) 來描述一個類,那麼這個類的“不確定性程度”,也就可以衡量這個類的“團結程度”了。
說更直白一點,“不確定性”越大(意味著越接近均勻分佈),說明這個類可能還處於動蕩的、各自為政的年代,此時啟用值應該越小;“不確定性”越小(意味著分佈越集中),說明這個類已經團結一致步入現代化,此時啟用值應該越大。
因此可以用不確定性來描述這個啟用值,而我們知道,不確定性是用資訊熵來度量的,所以我們寫出:

這就是論文中的那個 ,所以論文中的 cost 就是熵,多直觀清晰的含義。而且熵越小越好,這也是多自然的邏輯。
,所以論文中的 cost 就是熵,多直觀清晰的含義。而且熵越小越好,這也是多自然的邏輯。
為什麼不直接積分算出正態分佈的熵,而是要這樣迂迴地算?因為直接積分算出來是理論結果,我們這裡要根據這批資料本身算出一個關於這批資料的結果。
經過化簡,結果是(原論文計算結果應該有誤):

因為熵越小越顯著,所以我們用 −Sj 來衡量特徵的顯著程度,但又想將它壓縮為 0~1 之間。那麼可以對它做一些簡單的尺度變換後用 sigmoid 函式啟用:

(15) 式和 (13) 式基本是等價的,上式相當於 −Sj 和 πj 的加權求和,也就是綜合考慮了 −Sj(團結)和 πj(人多)。
其中 βa,βu 透過反向傳播最佳化,而 λ 則隨著訓練過程慢慢增大(退火策略,這是論文的選擇,我認為是不必要的)。
βa,βu 可能跟 j 有關,也就是可以為每個上層膠囊都分配一組訓練引數 βa,βu。說“可能”是因為論文根本就沒說清楚,或許讀者可以按照自己的實驗和需求調整。
有了 aj 的公式後,因為我們前面也說 aj 和 πj 有一定共同之處,它們都是類的某種權重,於是為了使得整個路由流程更緊湊,Hinton 乾脆直接用 aj 替換掉 πj,這樣替換雖然不能完全對應上原始的 GMM 的迭代過程,但也能收斂到類似的結果。
於是現在得到更正後的動態路由:

這應該就是最終的新的動態路由演演算法了,如果我沒理解錯的話,因為原論文實在太難看懂。
權重矩陣
最後,跟前一篇文章一樣,給每對指標 (i,j) 配上一個權重矩陣 Wij(稱為視覺不變矩陣),得到“投票矩陣”Vij=PiWij,然後再進行動態路由,得到最後的動態路由演演算法:

結語
評價
經過這樣一番理解,應該可以感覺到這個新版的 Capsule 及其路由演演算法並不複雜。
新論文的要點是使用了 GMM 來完成聚類過程,GMM 是一個基於機率模型的聚類演演算法。
緊抓住“機率模型”這一特性,尋找機率相關的量,就不難理解 aj 運算式的來源,這應該是理解整篇論文最困難的一點;而用矩陣代替向量,應該只是一種降低計算量和引數量的方案,並無本質變化。
只不過新論文傳承了舊論文的晦澀難懂的表達方式,加上混亂的符號使用,使得我們的理解難度大大增加,再次詬病作者們的文筆。
感想
到現在,終於算是把《Matrix Capsules with EM Routing》梳理清楚了,至於程式碼就不寫了,因為事實上我個人並不是特別喜歡這個新的 Capsule 和動態路由,不想再造輪子了。
這是我的關於 Capsule 理解的第三篇文章。相對於筆者的其他文章而言,這三篇文章的篇幅算得上是“巨大”,它們承載了我對 Capsule 的思考和理解。每一篇文章的撰寫都要花上好幾天的時候,試圖盡可能理論和通俗文字相結合,盡可能把前因後果都梳理清楚。
希望這些文字能幫助讀者更快速地理解 Capsule。當然,作者水平有限,如果有什麼誤導之處,歡迎留言批評。
當然,更希望 Capsule 的作者們能用更直觀、更具啟發性的語言來介紹他們的新理論,這就省下了我們這些科普者的不少功夫了。
畢竟 Capsule 有可能真的是深度學習的未來,怎可如此模糊呢?
相關連結
[1] Understanding Matrix capsules with EM Routing
https://jhui.github.io/2017/11/14/Matrix-Capsules-with-EM-routing-Capsule-Network/

點選以下標題檢視相關內容:

 #榜 單 公 布 #
#榜 單 公 布 #
2017年度最值得讀的AI論文 | NLP篇 · 評選結果公佈
2017年度最值得讀的AI論文 | CV篇 · 評選結果公佈
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 進入作者部落格