來自:咖啡拿鐵 (ID: close_3092860495)
前言
不知道你是否遇到過這樣的情況,去小賣鋪買東西,付了錢,但是店主因為處理了一些其他事,居然忘記你付了錢,又叫你重新付。又或者在網上購物明明已經扣款,但是卻告訴我沒有發生交易。
事實上,上面所描述的這一系列情況都是因為沒有事務導致的。這說明瞭事務在生活中的一些重要性。有了事務,你去小賣鋪買東西,那就是一手交錢一手交貨。有了事務,你去網上購物,扣款即產生訂單交易。
事務的具體定義
事務提供一種機制將一個活動涉及的所有操作納入到一個不可分割的執行單元,組成事務的所有操作只有在所有操作均能正常執行的情況下方能提交,只要其中任一操作執行失敗,都將導致整個事務的回滾。
簡單地說,事務提供一種“要麼什麼都不做,要麼做全套 (All or Nothing)”的機制。
資料庫本地事務
ACID
說到資料庫事務,就不得不說資料庫事務中的四大特性 —— ACID:
A —— 原子性(Atomicity)
一個事務(transaction)中的所有操作,要麼全部完成,要麼全部不完成,不會結束在中間某個環節。事務在執行過程中發生錯誤,會被回滾(Rollback)到事務開始前的狀態,就像這個事務從來沒有執行過一樣。
就像你買東西,要麼交錢收貨一起都執行,要麼就是發不出貨,就退錢。
C —— 一致性(Consistency)
事務的一致性指的是在一個事務執行之前和執行之後資料庫都必須處於一致性狀態。如果事務成功地完成,那麼系統中所有變化將正確地應用,系統處於有效狀態。如果在事務中出現錯誤,那麼系統中的所有變化將自動地回滾,系統傳回到原始狀態。
I —— 隔離性(Isolation)
隔離性指的是在併發環境中,當不同的事務同時操縱相同的資料時,每個事務都有各自的完整資料空間。由併發事務所做的修改必須與任何其他併發事務所做的修改隔離。
事務檢視資料更新時,資料所處的狀態要麼是另一事務修改它之前的狀態,要麼是另一事務修改它之後的狀態,事務不會檢視到中間狀態的資料。
打個比方,你買東西這個事情,是不影響其他人的。
D —— 永續性(Durability)
永續性指的是隻要事務成功結束,它對資料庫所做的更新就必須永久儲存下來。即使發生系統崩潰,重新啟動資料庫系統後,資料庫還能恢復到事務成功結束時的狀態。
打個比方,你買東西的時候需要記錄在賬本上,即使老闆忘記了那也有據可查。
InnoDB 實現原理
InnoDB 是 MySQL 的一個儲存引擎,大部分人對 MySQL 都比較熟悉,這裡簡單介紹一下資料庫事務實現的一些基本原理。在本地事務中,服務和資源在事務的包裹下可以看做是一體的:
 我們的本地事務由資源管理器進行管理:
我們的本地事務由資源管理器進行管理:
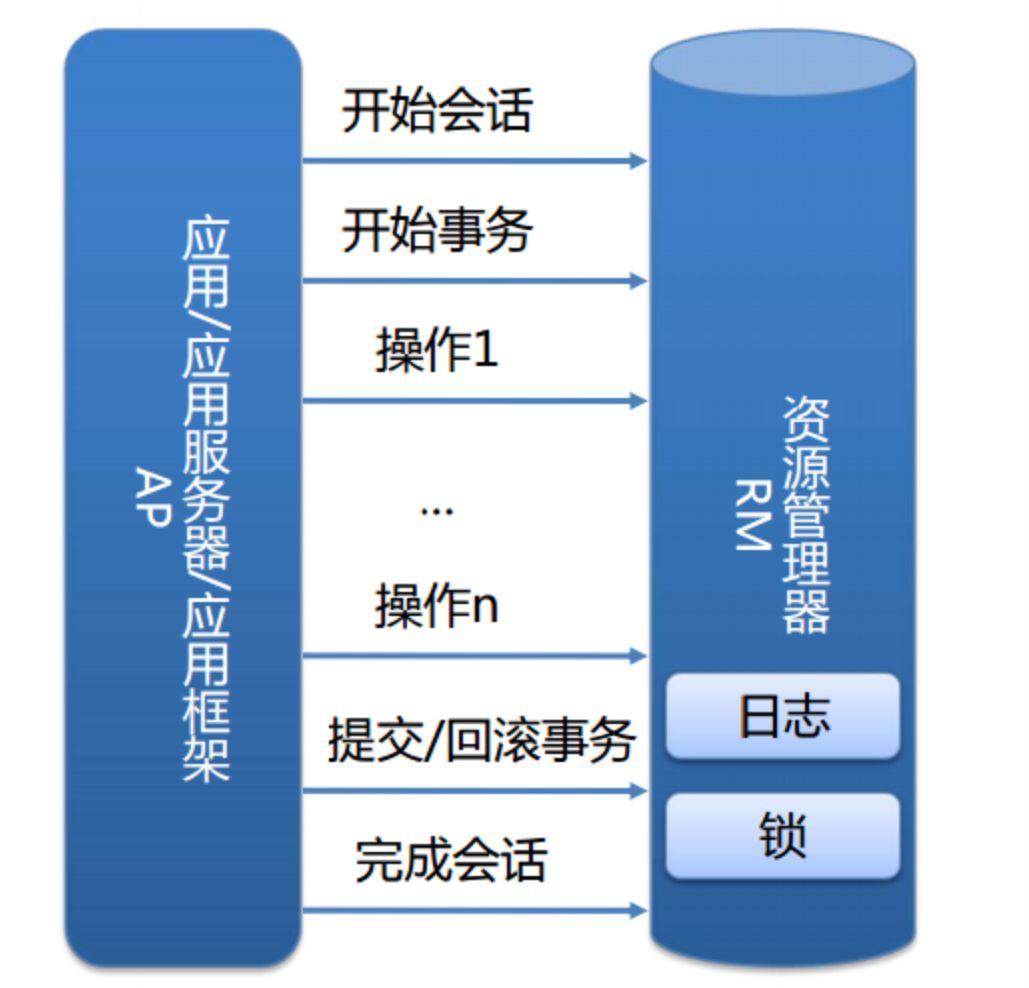
而事務的 ACID 是透過 InnoDB 日誌和鎖來保證。
事務的隔離性是透過資料庫鎖的機制實現的,永續性透過 redo log(重做日誌)來實現,原子性和一致性透過 Undo log(回滾日誌) 來實現。
Undo Log 的原理很簡單,為了滿足事務的原子性,在操作任何資料之前,首先將資料備份到一個地方(這個儲存資料備份的地方稱為 Undo Log)。然後進行資料的修改。如果出現了錯誤或者使用者執行了 ROLLBACK 陳述句,系統可以利用 Undo Log 中的備份將資料恢復到事務開始之前的狀態。
和 Undo Log 相反,Redo Log 記錄的是新資料的備份。在事務提交前,只要將 RedoLog 持久化即可,不需要將資料持久化。
當系統崩潰時,雖然資料沒有持久化,但是 Redo Log 已經持久化。系統可以根據 Redo Log 的內容,將所有資料恢復到最新的狀態。
對具體實現過程有興趣的同學可以去自行搜尋擴充套件。
分散式事務
什麼是分散式事務?
分散式事務就是指事務的參與者、支援事務的伺服器、資源伺服器以及事務管理器分別位於不同的分散式系統的不同節點之上。
簡單的說,就是一次大的操作由不同的小操作組成,這些小的操作分佈在不同的伺服器上,且屬於不同的應用,分散式事務需要保證這些小操作要麼全部成功,要麼全部失敗。本質上來說,分散式事務就是為了保證不同資料庫的資料一致性。
分散式事務產生的原因
從上面本地事務來看,我們可以看為兩塊,一個是 service 產生多個節點,另一個是 resource 產生多個節點。
-
service 多個節點
隨著網際網路快速發展,微服務,SOA 等服務架構樣式正在被大規模地使用。
舉個簡單的例子,一個公司之內,使用者的資產可能分為好多個部分,比如餘額、積分、優惠券等等。在公司內部有可能積分功能由一個微服務團隊維護,優惠券又是另外的團隊維護。
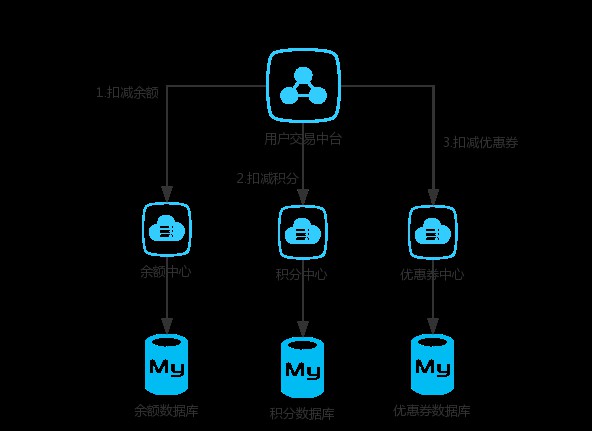
這樣的話就無法保證積分扣減了之後,優惠券能否扣減成功。
-
resource 多個節點
同樣的,網際網路發展得太快了,一般來說,我們的 MySQL 裝千萬級的資料就得進行分庫分表。對於一個支付寶的轉賬業務來說,你給別的朋友轉錢,有可能你的資料庫是在北京,而你朋友的錢是存在上海,所以我們依然無法保證他們能同時成功。

分散式事務的基礎
從上面來看,分散式事務是隨著網際網路高速發展應運而生的,這是一個必然的結果。我們之前說過,資料庫的 ACID 四大特性已經無法滿足我們分散式事務。這個時候又有一些新的大佬提出了一些新的理論:
CAP
CAP 定理,又被叫作布魯爾定理。對於設計分散式系統(不僅僅是分散式事務)的架構師來說,CAP 就是你的入門理論。
- C (一致性):對某個指定的客戶端來說,讀操作能傳回最新的寫操作。對於資料分佈在不同節點上的資料來說,如果在某個節點更新了資料,那麼在其他節點如果都能讀取到這個最新的資料,那麼就稱為強一致;如果有某個節點沒有讀取到,那就是分散式不一致。
- A (可用性):非故障的節點在合理的時間內傳回合理的響應(不是錯誤和超時的響應)。可用性的兩個關鍵:一個是合理的時間,一個是合理的響應。合理的時間指的是請求不能無限被阻塞,應該在合理的時間給出傳回。合理的響應指的是系統應該明確傳回結果並且結果是正確的,這裡的正確指的是比如應該傳回 50,而不是傳回 40。
- P (分割槽容錯性):當出現網路分割槽後,系統能夠繼續工作。打個比方,這個叢集有多臺機器,有臺機器網路出現了問題,但是這個叢集仍然可以正常工作。
熟悉 CAP 的人都知道,三者不能共有,如果感興趣可以搜尋 CAP 的證明。
在分散式系統中,網路無法 100% 可靠,分割槽其實是一個必然現象,如果我們選擇了 CA 而放棄了 P,那麼當發生分割槽現象時,為了保證一致性,這個時候必須拒絕請求,但是 A 又不允許,所以分散式系統理論上不可能選擇 CA 架構,只能選擇 CP 或者 AP 架構。
對於 CP 來說,放棄可用性,追求一致性和分割槽容錯性,我們的 zookeeper 其實就是追求的強一致。
對於 AP 來說,放棄一致性(這裡說的一致性是強一致性),追求分割槽容錯性和可用性,這是很多分散式系統設計時的選擇,後面的 BASE 也是根據 AP 來擴充套件。
順便一提,CAP 理論中是忽略網路延遲,也就是當事務提交時,從節點A複製到節點B,但是在現實中這個是明顯不可能的,所以總會有一定的時間是不一致。同時 CAP 中選擇兩個,比如你選擇了 CP,並不是叫你放棄 A。因為 P 出現的機率實在是太小了,大部分的時間你仍然需要保證 CA。就算分割槽出現了你也要為後來的 A 做準備,比如透過一些日誌的手段,使其他機器恢復至可用。
BASE
BASE 是 Basically Available(基本可用)、Soft state(軟狀態)和 Eventually consistent(最終一致性)三個短語的縮寫。是對 CAP 中 AP 的一個擴充套件:
- 基本可用:分散式系統在出現故障時,允許損失部分可用功能,保證核心功能可用。
- 軟狀態:允許系統中存在中間狀態,這個狀態不影響系統可用性,這裡指的是 CAP 中的不一致。
- 最終一致:最終一致是指經過一段時間後,所有節點資料都將會達到一致。
BASE 解決了 CAP 中理論沒有網路延遲,在 BASE 中用軟狀態和最終一致保證了延遲後的一致性。
BASE 和 ACID 是相反的,它完全不同於 ACID 的強一致性模型,而是透過犧牲強一致性來獲得可用性,並允許資料在一段時間內是不一致的,但最終達到一致狀態
分散式事務解決方案
有了上面的理論基礎後,這裡介紹開始介紹幾種常見的分散式事務解決方案。
是否真的要分散式事務?
在說方案之前,首先一定要明確你是否真的需要分散式事務?
上面說過出現分散式事務的兩個原因,其中有個原因是因為微服務過多。我見過太多團隊一個人維護幾個微服務,太多團隊過度設計,搞得所有人疲勞不堪,而微服務過多就會引出分散式事務,這個時候我不會建議你去採用下麵任何一種方案,而是請把需要事務的微服務聚合成一個單機服務,使用資料庫的本地事務。
因為不論任何一種方案都會增加你係統的複雜度,這樣的成本實在是太高了,千萬不要因為追求某些設計,而引入不必要的成本和複雜度。
如果你確定需要引入分散式事務,可以看看下麵幾種常見的方案。
2PC
說到 2PC 就不得不聊資料庫分散式事務中的 XA Transactions。

在 XA 協議中分為兩階段:
-
第一階段:事務管理器要求每個涉及到事務的資料庫預提交(precommit)此操作,並反映是否可以提交。
-
第二階段:事務協調器要求每個資料庫提交資料,或者回滾資料。
優點:
-
儘量保證了資料的強一致,實現成本較低,在各大主流資料庫都有自己實現,對於 MySQL 是從 5.5 開始支援。
缺點:
- 單點問題:事務管理器在整個流程中扮演的角色很關鍵,如果其宕機,比如在第一階段已經完成,在第二階段正準備提交的時候事務管理器宕機,資源管理器就會一直阻塞,導致資料庫無法使用。
- 同步阻塞:在準備就緒之後,資源管理器中的資源一直處於阻塞,直到提交完成,釋放資源。
- 資料不一致:兩階段提交協議雖然為分散式資料強一致性所設計,但仍然存在資料不一致性的可能,比如在第二階段中,假設協調者發出了事務 commit 的通知,但是因為網路問題該通知僅被一部分參與者所收到並執行了 commit 操作,其餘的參與者則因為沒有收到通知一直處於阻塞狀態,這時候就產生了資料的不一致性。
總的來說,XA 協議比較簡單,成本較低,但是其單點問題,以及不能支援高併發(由於同步阻塞)依然是其最大的弱點。
TCC
關於 TCC(Try-Confirm-Cancel) 的概念,最早是由 Pat Helland 於2007年發表的一篇名為《Life beyond Distributed Transactions:an Apostate’s Opinion》的論文提出。
TCC 事務機制相比於上面介紹的 XA,解決了其幾個缺點:
1.解決了協調者單點,由主業務方發起並完成這個業務活動。業務活動管理器也變成多點,引入叢集。
2.同步阻塞:引入超時,超時後進行補償,並且不會鎖定整個資源,將資源轉換為業務邏輯形式,粒度變小。
3.資料一致性,有了補償機制之後,由業務活動管理器控制一致性。

對於 TCC 的解釋:
-
Try階段:嘗試執行,完成所有業務檢查(一致性),預留必須業務資源(準隔離性)。
-
Confirm階段:確認執行真正執行業務,不作任何業務檢查,只使用 Try 階段預留的業務資源,Confirm 操作滿足冪等性。要求具備冪等設計,Confirm 失敗後需要進行重試。
-
Cancel階段:取消執行,釋放 Try 階段預留的業務資源,Cancel 操作滿足冪等性,Cancel 階段的異常和 Confirm 階段異常處理方案基本上一致。
舉個簡單的例子如果你用100元買了一瓶水,Try階段:你需要向你的錢包檢查是否夠100元並鎖住這100元,水也是一樣的。
如果有一個失敗,則進行 cancel(釋放這100元和這一瓶水),如果 cancel 失敗,不論什麼失敗都進行重試 cancel,所以需要保持冪等。
如果都成功,則進行 confirm,確認這100元已扣和這一瓶水被賣;如果 confirm 失敗,無論什麼失敗則重試(會依靠活動日誌進行重試)。
對於 TCC 來說適合一些:
- 強隔離性,嚴格一致性要求的活動業務
- 執行時間較短的業務
實現參考:ByteTCC https://github.com/liuyangming/ByteTCC/
本地訊息表
本地訊息表這個方案最初是 ebay 提出的 ebay 的完整方案
https://queue.acm.org/detail.cfm?id=1394128
此方案的核心是將需要分散式處理的任務透過訊息日誌的方式來非同步執行。訊息日誌可以儲存到本地文字、資料庫或訊息佇列,再透過業務規則自動或人工發起重試。人工重試更多的是應用於支付場景,透過對賬系統對事後問題的處理。
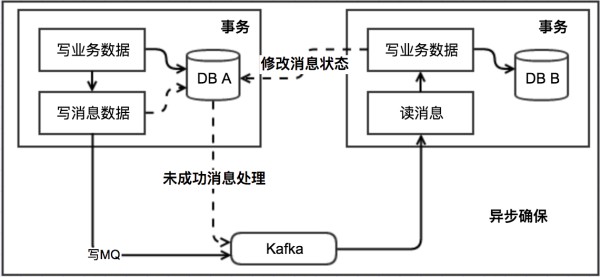
對於本地訊息佇列來說核心是把大事務轉變為小事務。
還是舉上面用100元去買一瓶水的例子:
1.當你扣錢的時候,你需要在你扣錢的伺服器上新增加一個本地訊息表,你需要把你扣錢和寫入減去水的庫存到本地訊息表放入同一個事務(依靠資料庫本地事務保證一致性)。
2.這個時候有個定時任務去輪詢這個本地事務表,把沒有傳送的訊息扔給商品庫存伺服器,叫他減去水的庫存,到達商品伺服器之後這個時候得先寫入這個伺服器的事務表,然後進行扣減,扣減成功後,更新事務表中的狀態。
3.商品伺服器透過定時任務掃描訊息表或者直接通知扣錢伺服器,扣錢伺服器本地訊息表進行狀態更新。
4.針對一些異常情況,定時掃描未成功處理的訊息,進行重新傳送,在商品伺服器接到訊息之後,首先判斷是否是重覆的,如果已經接收,再判斷是否執行,如果執行則馬上又進行通知事務,如果未執行,需要重新執行,需要由業務保證冪等,也就是不會多扣一瓶水。
本地訊息佇列是 BASE 理論,是最終一致模型,適用於對一致性要求不高的。實現這個模型時需要註意重試的冪等。
MQ事務
在 RocketMQ 中實現了分散式事務,實際上其實是對本地訊息表的一個封裝,將本地訊息表移動到了 MQ 內部。
下麵簡單介紹一下 MQ 事務,如果想對其詳細瞭解可以參考:https://www.jianshu.com/p/453c6e7ff81c。

基本流程如下:
第一階段 Prepared 訊息,會拿到訊息的地址。
第二階段執行本地事務。
第三階段透過第一階段拿到的地址去訪問訊息,並修改狀態。訊息接受者就能使用這個訊息。
如果確認訊息失敗,在RocketMq Broker中提供了定時掃描沒有更新狀態的訊息,如果有訊息沒有得到確認,會向訊息傳送者傳送訊息,來判斷是否提交,在rocketmq中是以listener的形式給傳送者,用來處理。

如果消費超時,則需要一直重試,訊息接收端需要保證冪等。如果訊息消費失敗,這個就需要人工進行處理,因為這個機率較低,如果為了這種小機率時間而設計這個複雜的流程反而得不償失。
Saga事務
Saga是30年前一篇資料庫倫理提到的一個概念。其核心思想是將長事務拆分為多個本地短事務,由 Saga 事務協調器協調,如果正常結束那就正常完成,如果某個步驟失敗,則根據相反順序一次呼叫補償操作。
Saga 的組成:每個 Saga 由一系列 sub-transaction Ti 組成,每個 Ti 都有對應的補償動作 Ci,補償動作用於撤銷 Ti 造成的結果,這裡的每個T,都是一個本地事務。
可以看到,和 TCC 相比,Saga 沒有“預留Try”動作,它的 Ti 就是直接提交到庫。
Saga 的執行順序有兩種:
T1, T2, T3, …, Tn
T1, T2, …, Tj, Cj,…, C2, C1,其中 0 < j < n Saga 定義了兩種恢復策略:
-
向後恢復,即上面提到的第二種執行順序,其中 j 是發生錯誤的 sub-transaction,這種做法的效果是撤銷掉之前所有成功的 sub-transation,使得整個 Saga 的執行結果撤銷。
-
向前恢復,適用於必須要成功的場景,執行順序是類似於這樣的:T1, T2, …, Tj(失敗), Tj(重試),…, Tn,其中 j 是發生錯誤的 sub-transaction。該情況下不需要 Ci。
這裡要註意的是,在 Saga 樣式中不能保證隔離性,因為沒有鎖住資源,其他事務依然可以改寫或者影響當前事務。
還是拿100元買一瓶水的例子來說,這裡定義
T1=扣100元 T2=給使用者加一瓶水 T3=減庫存一瓶水
C1=加100元 C2=給使用者減一瓶水 C3=給庫存加一瓶水
我們一次進行 T1, T2, T3,如果發生問題,就執行發生問題的C操作的反向。上面說到的隔離性的問題會出現。如果執行到 T3 這個時候需要執行回滾,但是這個使用者已經把水喝了(另外一個事務),回滾的時候就會發現,無法給使用者減一瓶水了。這就是事務之間沒有隔離性的問題。
可以看見 Saga 樣式沒有隔離性的影響還是較大,可以參照華為的解決方案:從業務層面入手加入 Session 以及鎖的機制來保證能夠序列化操作資源。也可以在業務層面透過預先凍結資金的方式隔離這部分資源,最後在業務操作的過程中可以透過及時讀取當前狀態的方式獲取到最新的更新。
具體實體:參考華為的 ServiceComb
最後
還是那句話,能不用分散式事務就不用,如果非得使用的話,結合自己的業務分析,看看自己的業務比較適合哪一種,是在乎強一致,還是最終一致即可。
上面對解決方案只是一些簡單介紹,如果真正的想要落地,其實每種方案需要思考的地方都非常多,複雜度都比較大,所以最後再次提醒一定要判斷好是否使用分散式事務。
最後再總結一些問題,大家可以試下自己從文章找尋答案:
1.ACID 和 CAP 的 CA 是一樣的嗎?
2.分散式事務常用的解決方案的優缺點是什麼?適用於什麼場景?
3.分散式事務出現的原因?用來解決什麼痛點?
