
站在風口上的大資料,究竟被什麼拖了後腿?
導讀:當大資料帶給世界更多位元,這些實時產生的海量資料成為了一座開採難度巨大的礦山。大家都知道透過這些碎片化的資料能夠挖掘出更多價值,但是就目前的整體發展來看,大資料的應用遠沒有達到預期的效果,其原因有如下幾個。 ...
導讀:當大資料帶給世界更多位元,這些實時產生的海量資料成為了一座開採難度巨大的礦山。大家都知道透過這些碎片化的資料能夠挖掘出更多價值,但是就目前的整體發展來看,大資料的應用遠沒有達到預期的效果,其原因有如下幾個。 ...

導讀:生成對抗網路GAN是Ian Goodfellow在2014年他的博士期間提出的機器學習架構。與傳統的神經網路模型不同,GAN包括了兩套獨立的網路:生成器與判別器,兩者之間作為互相對抗的標的,最終生成器將能創造出讓判別器無法識別真假的內...
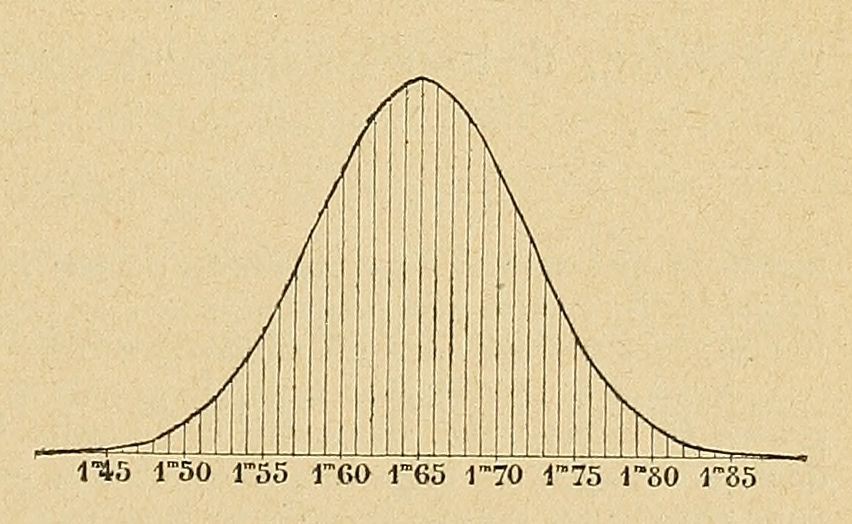
導讀:為什麼正態分佈如此特殊?為什麼大量資料科學和機器學習的文章都圍繞正態分佈進行討論?我決定寫一篇文章,用一種簡單易懂的方式來介紹正態分佈。 在機器學習的世界中,以機率分佈為核心的研究大都聚焦於正態分佈。本文將闡述正態分佈的機率,並解釋它...

導讀:在資料清洗過程中,主要處理的是缺失值、異常值和重覆值。所謂清洗,是對資料集透過丟棄、填充、替換、去重等操作,達到去除異常、糾正錯誤、補足缺失的目的。 作者:宋天龍 如需轉載請聯絡大資料(ID:...
導讀:本文為不同階段的Python學習者從不同角度量身定製了49個學習資源。 來源:專知(ID:Quan_Zhuanzhi) 01 初學者 1. Welcome to Python.or...
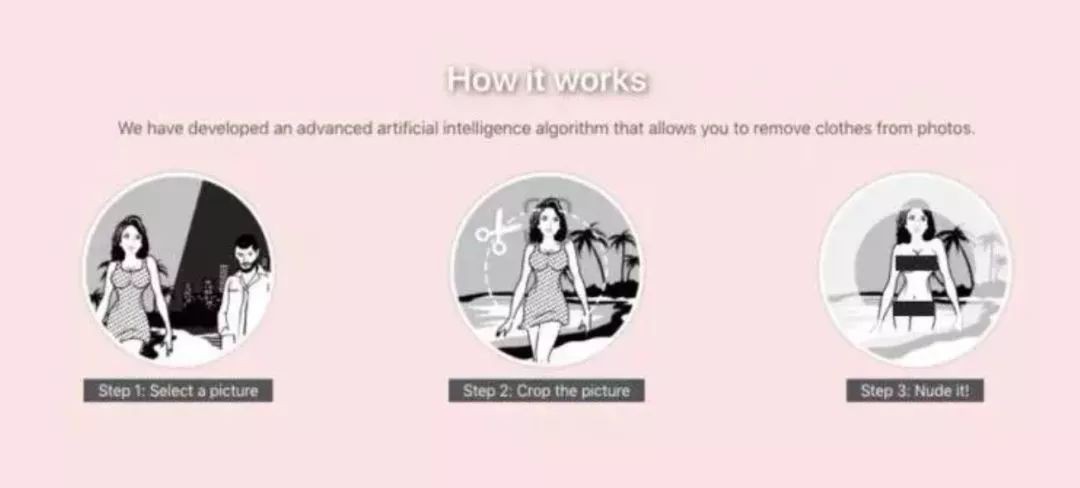
導讀:本文會探討一些image/text/random-to-image的神經網路模型,僅供學習交流之用,也歡迎分享你的技術解決方案。 作者:yuanxiaosc 來源:Github、大資料文摘 原文: https://git...

作者:Ben Sanders;翻譯:吳慧聰;校對:鄭滋 本文約2400字,建議閱讀10分鐘。 本文將簡要介紹什麼是機器學習,其運作原理,以及兩個主要的機器學習的演演算法。 簡介 本文中,資料科學創業公司Yhat的前聯合創始人,現任Waldo的...

作者:Pete Warden;翻譯:申利彬; 本文約6800字,建議閱讀10分鐘。 本文作者基於自身專案經驗闡述訓練資料的重要性並分享了一些改進的實用技巧。 Lisha Li 攝 這張幻燈片是Andrej Karpathy 在Train...

導讀:很多程式員處理文字而不是數字。文字包含字元:字母、數字、標點符號、空格等。字串是一系列字元。例如,字串”Hello”是一個包含5個字元的序列。 作者:凱·霍斯特曼(Cay Horst...

作者:Jacob Devlin and Ming-Wei Chang, Research Scientists, Google AI Language;翻譯:佟海寧;校對:吳金笛 本文約2000字,建議閱讀9分鐘。 本文為你介紹谷歌最新釋出...