
站在風口上的大資料,究竟被什麼拖了後腿?
導讀:當大資料帶給世界更多位元,這些實時產生的海量資料成為了一座開採難度巨大的礦山。大家都知道透過這些碎片化的資料能夠挖掘出更多價值,但是就目前的整體發展來看,大資料的應用遠沒有達到預期的效果,其原因有如下幾個。 ...
導讀:當大資料帶給世界更多位元,這些實時產生的海量資料成為了一座開採難度巨大的礦山。大家都知道透過這些碎片化的資料能夠挖掘出更多價值,但是就目前的整體發展來看,大資料的應用遠沒有達到預期的效果,其原因有如下幾個。 ...

導讀:生成對抗網路GAN是Ian Goodfellow在2014年他的博士期間提出的機器學習架構。與傳統的神經網路模型不同,GAN包括了兩套獨立的網路:生成器與判別器,兩者之間作為互相對抗的標的,最終生成器將能創造出讓判別器無法識別真假的內...
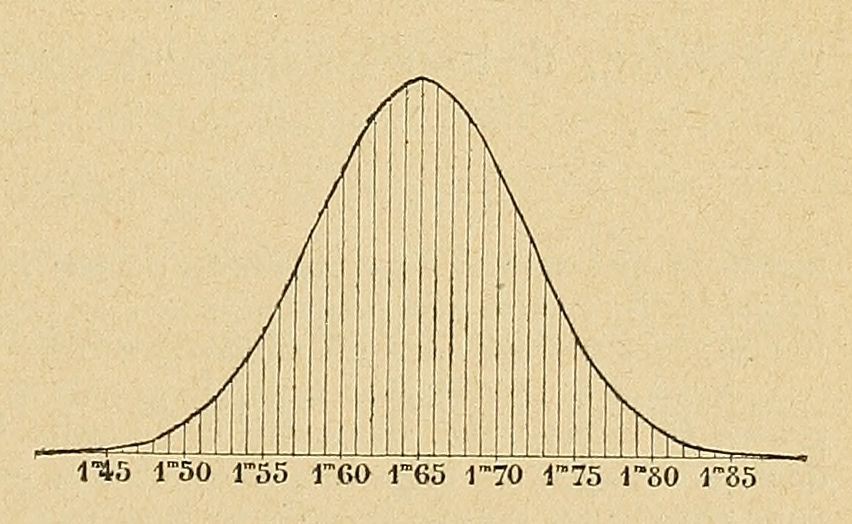
導讀:為什麼正態分佈如此特殊?為什麼大量資料科學和機器學習的文章都圍繞正態分佈進行討論?我決定寫一篇文章,用一種簡單易懂的方式來介紹正態分佈。 在機器學習的世界中,以機率分佈為核心的研究大都聚焦於正態分佈。本文將闡述正態分佈的機率,並解釋它...

由於缺乏人手以及缺乏簡單的修複方法,該 bug 多年來一直沒有解決 作者/來源:安華金和 Tor 將修複一個過去幾年被用於向暗網網站發動 DDoS 攻擊的 Bug。即將釋出的 Tor protocol 0.4.2 將修複該 bug。 拒絕訪...

導讀:在資料清洗過程中,主要處理的是缺失值、異常值和重覆值。所謂清洗,是對資料集透過丟棄、填充、替換、去重等操作,達到去除異常、糾正錯誤、補足缺失的目的。 作者:宋天龍 如需轉載請聯絡大資料(ID:...
導讀:本文為不同階段的Python學習者從不同角度量身定製了49個學習資源。 來源:專知(ID:Quan_Zhuanzhi) 01 初學者 1. Welcome to Python.or...
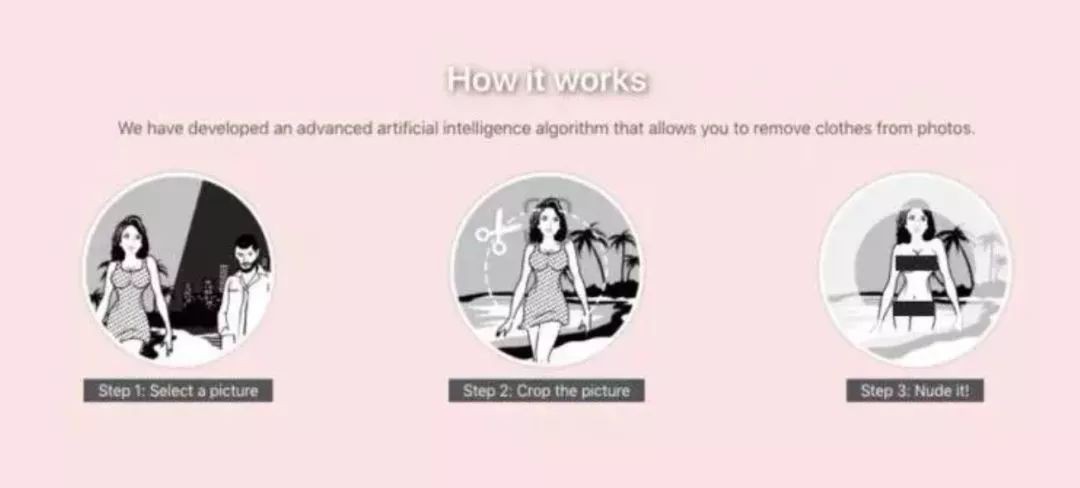
導讀:本文會探討一些image/text/random-to-image的神經網路模型,僅供學習交流之用,也歡迎分享你的技術解決方案。 作者:yuanxiaosc 來源:Github、大資料文摘 原文: https://git...

導讀:很多程式員處理文字而不是數字。文字包含字元:字母、數字、標點符號、空格等。字串是一系列字元。例如,字串”Hello”是一個包含5個字元的序列。 作者:凱·霍斯特曼(Cay Horst...

導讀:Microsoft Word在當前使用中是佔有巨大優勢的文書處理器,這使得Word專用的檔案格式Word 檔案(.docx)成為事實上最通用的標準。 在日常工作中,有些時候會有很多重覆的工作,比如批次的替換、報名錶、合同、邀請函等很多...

導讀:我們發現,西部城市正在霸佔大眾視野。 抖音是主要平臺之一。根據抖音在《2018短影片與城市形象研究白皮書》中公佈的資料,重慶、西安和成都是城市形象短影片播放量最高的三個城市,排名首位的重慶播放量達113.6億次,是第四位北京的1.5倍...