
千萬級中文公開免費聊天語料資料分享
分享一個包含千萬級聊天語料的資源。地址:https://github.com/codemayq/chaotbot_corpus_Chinese 該庫是對目前市面上已有的開源中文聊天語料的蒐集和系統化整理工作 該庫蒐集...
分享一個包含千萬級聊天語料的資源。地址:https://github.com/codemayq/chaotbot_corpus_Chinese 該庫是對目前市面上已有的開源中文聊天語料的蒐集和系統化整理工作 該庫蒐集...

3 月 14 日(週四)晚 8 點,平安人壽智慧平臺團隊資深演演算法工程師謝舒翼在 PaperWeekly 直播間為大家帶來了智慧問答系統的探索與實踐主題分享,並且介紹了平安人壽基於業務場景的技術探索成果。 本文將獨家分享本期活動的影片實錄和...

2017年10月,《紐約客》雜誌的一張封面毫無徵兆地刷了屏: 封面上,人類坐地行乞,機器人則扮演了施予者的角色,意指明顯——在未來社會,人類的工作機會被不斷進化的機器人剝奪,從而淪為了流落街頭的弱者。 《紐約客》雜誌封面 高德納...
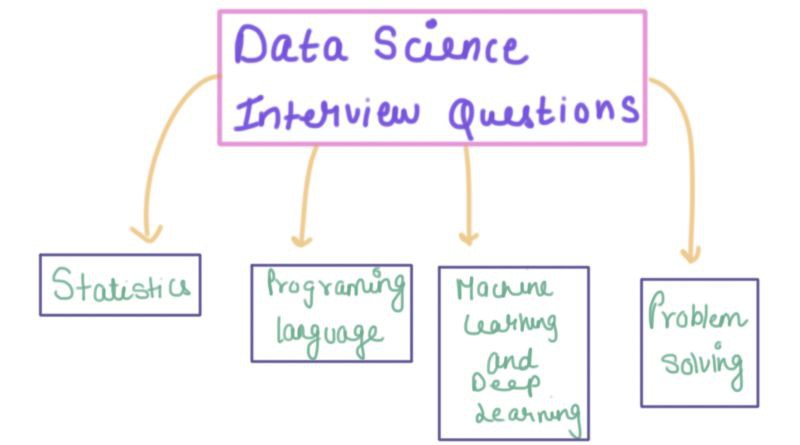
作者:Kartik Singh;翻譯:王雨桐;校對:霍詩琴 本文約50000字,建議閱讀10分鐘。 本文盤點了資料科學和機器學習面試中的常見問題。 技術的不斷進步使得資料和資訊的產生速度今非昔比,並且呈現出繼續增長的趨勢。此外,目前對解釋、...
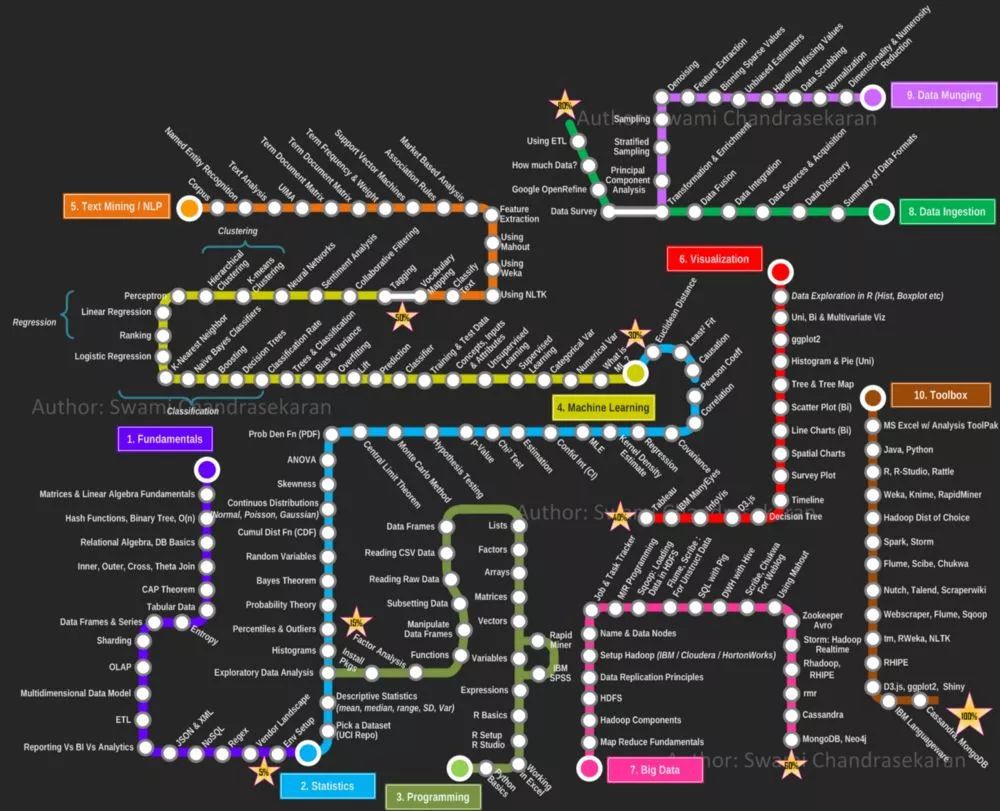
導讀:學 Excel 還是 R、Python?機器學習怎麼入門?資料工程師和資料科學家有什麼區別?聽聽美國 IT 大牛的建議。 最近看到一篇叫「2019 年學習資料科學是什麼感受」的文章,深有感觸。作者是 Thomas Nield,美國西南...
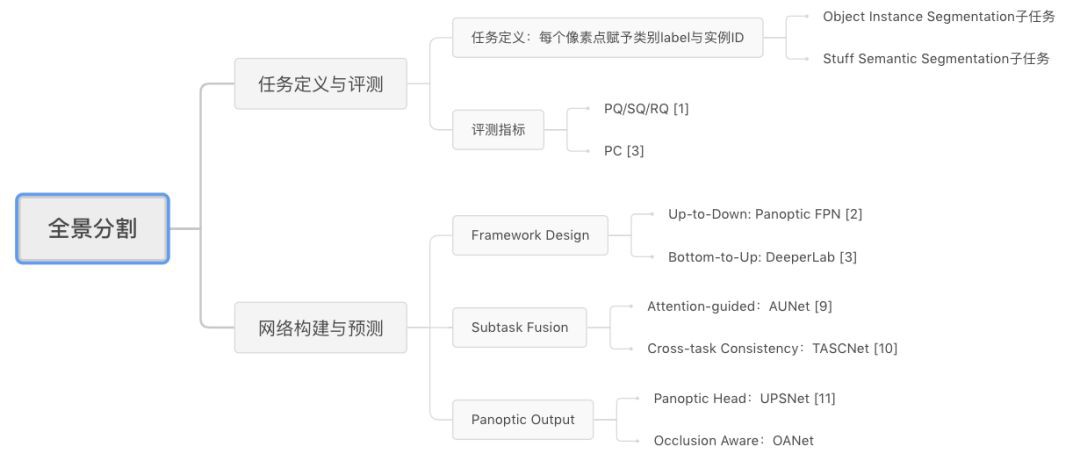
關於作者:劉環宇,浙江大學控制科學與工程自動化系碩士,曠視科技研究院演演算法研究員,全景分割演演算法 OANet 第一作者,研究方向包括全景分割、語意分割等;2018 COCO + Mapillary 全景分割比賽曠視 Detection 組冠...

作者丨蘇劍林 單位丨廣州火焰資訊科技有限公司 研究方向丨NLP,神經網路 個人主頁丨kexue.fm 高舉“讓 Keras 更酷一些!”大旗,讓 Keras 無限可能。 今天我們會用 Keras 做到兩件很重要的事情:分層設定學習率和靈...

讀一切好書,就是和許多高尚的人談話。——笛卡兒 在這個資料世界裡,如何讀懂資料,用好資料,對於個人和公司,都顯得非常重要了。因此,以資料為物件,學習相關的系統的知識,並且積極的實踐,以努力成為一名資料人才。閱讀一些好書,是一種有效的學習方法...

導讀:我們將結合知名度、典型性、綜合性等多種因素,以國內國外、企業院校等4個維度為標準,每個維度選取3個具有代表性的企業或院校,為大家總結國內外知名院校及企業的人工智慧實驗室現狀,以及他們的就職以及實習(錄取)申請要求。排名不分先後,僅供各...

(給資料分析與開發加星標,提升資料技能) 作者:GjZero,轉自:資料派(ID:datapi) Bert介紹 Bert模型是Google在2018年10月釋出的語言表示模型,Bert在NLP領域橫掃了11項任務的最優結果,可...